Малоизвестное интересное
05 июня 2024 13:05
Атмосфера страха, секретности и запугивания накрыла индустрию ИИ.
Воззвание сотрудников OpenAI остановить превращение компании в новый Theranos.
✔️ Сотрудники компаний – лидеров разработки ИИ знают о своей работе такое, что больше не знает никто на свете. Они обладают существенной закрытой информацией о возможностях и ограничениях своих систем, а также об адекватности принимаемых их компаниями защитных мер и уровнях риска различных видов вреда для общества.
✔️ Однако, в настоящее время они вынуждены молчать, ибо строгих обязательств информировать общественность и правительство у них нет, а их компании – бывшие и нынешние работодатели, - крепко запечатывают им рты с помощью «соглашений о неунижении», влекущих страшные юридические и финансовые кары не только за любое разглашение, но и, в принципе, за любую критику компании.
Опубликованное вчера воззвание бывших и нынешних сотрудников OpenAI, поддержанное Йошуф Бенжио, Джеффри Хинтононом и Стюартом Расселом [1,2], подтвердило оба вышеприведенных вывода моего недавнего лонгрида «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти» [3].
Публикация воззвания спустя почти 3 недели после того, как OpenAI объявил во внутреннем мемо об отказе от практики «соглашения о неунижении» [4], а также новые детали роли культа личности Сэма Альтмана в управляемом хаосе OpenAI, рассказанные двумя бывшими членами правления [5], позволяют предположить следующее:
1) Атмосфера страха, секретности и запугивания, накрывшая OpenAI, подобно тому, как это было в Theranos, вовсе не выветрилась, а лишь нагнетается теперь более тонким методом, чем «соглашения о неунижении».
2) Подобно тому, как было с Элизабет Холмс в Theranos, ключевой фигурой управляемого хаоса в OpenAI является генеральный директор компании Сэм Альтман:
• культивирующий атмосферу чрезвычайной секретности, страха и запугивания;
• жестко подавляющий любую критику или сомнения в отношении своих идей и подходов;
• требующий полного подчинения от сотрудников и не допускающий никаких возражений или критики в адрес своих действий и видения компании;
• культивирующий культ личности вокруг себя, представляя себя как одаренного гения и визионера, а любые расхождения с его видением или критика рассматриваются, как проявление неверности и потому неприемлемы.
3) То, что среди подписантов воззвания не только бывшие и нынешние сотрудники OpenAI, но также и DeepMind и Anthropic, может быть вызвано не только солидарностью последних к беспределу руководства OpenAI. Это может означать, что атмосфера страха, секретности и запугивания накрывает всю индустрию ИИ.
#AGI #ИИриски
1 https://bit.ly/4e6rgXX
2 https://righttowarn.ai/
3 /channel/theworldisnoteasy/1943
4 https://bit.ly/4c9jDxV
5 https://bit.ly/3yOedKw
Читать полностью…
Малоизвестное интересное
03 июня 2024 12:58
У родителей и детей нет шансов договориться.
Оценка того, когда жилось лучше, зависит исключительно от возраста.
Перед вами результат замечательного теста, превратившего интуитивную мудрость в обоснованное на фактах заключение.
• Про то, что жизнь была лучше, когда деревья были большими, известно давно.
• Но то, что из этого следует невозможность общественного консенсуса по вопросу о лучшем десятилетии в жизни страны, - было неочевидно.
Даже не верится, но пик положительного восприятия большинства аспектов культурной, экономической и социальной жизни приходится на подростковый и юношеский возраст: музыка, кино, новости, отношения в семье и с друзьями … - все что угодно.
Еще более удивительно, что ностальгическое восприятие характерных черт времен собственной юности одинаково для всех поколений (т.е. не зависит от того, когда вы родились).
Это подтверждается результатами весьма солидного опроса 2 тыс американцев, проведенного YouGov.
Подавляющее большинство, в независимости от пола, расы, доходов, региона и т.д., ответили, что:
• лучшая кухня в стране была - когда им было 18-22 года;
• лучшая музыка, мода и спортивные зрелища - когда им было 16-19;
• лучшее кино, радио, ТВ и экономическое положение - когда им было 12-15;
• самые достоверные новости, самое нравственное общество и самая счастливая семья - когда им было 8-11;
• а самые сплоченные сообщества были - когда им было всего 4-7лет.
Другим замечательным результатом опроса было абсолютное единодушие в ответах всех возрастов и социальных групп на вопросы о наихудших временах для всего вышеназванного и не только (другие вопросы и оценки см. в статистике опроса).
✔️ Почти без исключения, все ответили - «прямо сейчас!»
На приложенном рисунке показан «жизненный цикл ностальгии» американцев.
N.B. Полагаю, что подобный характер «жизненного цикла ностальгии» характерен для поколений, не прошедших в возрасте самостоятельного принятия решений через периоды ломки и хаоса революционных изменений (как, например, было в России 80-х и 90-х годов).
Ибо в основе ностальгии лежат пережитые человеком самые эмоциональные моменты жизни, многие из которых остаются в памяти навсегда. У «поколений спокойных времен» большинство таких моментов приходится на подростковый и юношеский возраст. А у «поколений революции» это достается, в основном, людям постарше: 25-40 летним. Что, скорее всего, и определило состав оппонентов дискуссий вокруг нашумевшего фильма о 90-х.
Диаграмма «жизненного цикла ностальгии» американцев https://telegra.ph/file/51dc06adb5a8cd40124f8.jpg
Материал об опросе за пейволом https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Без пейвола https://archive.ph/2024.05.24-100423/https://www.washingtonpost.com/business/2024/05/24/when-america-was-great-according-data/
Полная статистика опроса https://ygo-assets-websites-editorial-emea.yougov.net/documents/crosstabs_Best_and_Worst_Decades_20240523.pdf
#Социология #СоциальнаяПсихология #Ностальгия
Читать полностью…
Малоизвестное интересное
30 мая 2024 14:31
Открыт способ установить нижнюю границу энергозатрат произвольных вычислительных процессов.
Это новая глава для новой физики, без которой не появится СуперИИ.
• Рост интеллектуальных способностей генеративного ИИ на основе больших языковых моделей определяется их масштабированием.
• А рост масштаба моделей требует роста вычислительной мощности оборудования, на котором модели работают.
• Однако, с ростом вычислительной мощности существует фундаментальная термодинамическая засада – принцип Ландауэра (предельно упрощая, этот принцип утверждает, что для выполнения вычислений необходимо расходовать энергию; и чем больше произвести вычислений, тем больше будет произведено тепла).
• Если преодолеть это термодинамическое ограничение компьютеров, станет возможным создание все более мощных вычислительных систем для все более мощных моделей генеративного ИИ.
• Более того. Преодоление этого термодинамического ограничения может открыть путь к построению оборудования, столь же энергоэффективного, как биологические вычислительные системы (напр. мозг), чья энергоэффективность в 100 000 выше компьютеров.
Но чтобы преодолеть термодинамическое ограничение компьютеров, нужна «Новая физика», пересматривающая физику вычислений на кроссдисциплинарном стыке неравновесной физики и теории вычислений.
Этим и занимается уже 10 лет проф. Дэвид Волперт.
✔️ В 2018 группа Волперта опубликовала одно из первых успешных приложений «Новой физики», описав на основе неравновесных методов скрытую сложность, казалось бы, простейшего процесса физического превращения бита из 1 в 0 (см. [1]). Это был прорыв. Но от понимания физики работы одного бита информации до понимания работы компьютера, как до Альфа-Центавра.
✔️ Новый прорыв произошел в 2020. Волперт и Колчинский опубликовали работу «Термодинамика вычислений со схемами», в которой был описан процесс масштабирования применения неравновесной физики от битов до схем (см. [2]). Это был второй прорыв. Но и он не позволял полноценно применить «Новую физику» к компьютерным вычислениям из-за их непредсказуемости.
Новый 3й прорыв произошел только что.
Волперт и трое его соавторов (физики и компьютерщики) расширили современную теорию термодинамики вычислений. Объединив подходы статистической физики и информатики, они представили математические уравнения, которые показывают минимальные и максимальные прогнозируемые энергетические затраты вычислительных процессов, зависящих от случайности, которая является мощным инструментом в современных компьютерах.
Такого рода вычислительных процессов в компьютерах сколько угодно. Например, - процессы с непредсказуемым завершением.
Представьте мой любимы пример - симулятор игры в “Монету Питерса” (см. [3] или [4]). И допустим, при подбрасывании монеты дано указание прекратить подбрасывание, как только выпадут 100 орлов. Нетрудно понять, что момент останова симулятора случаен, и потому он будет непредсказуем для разных попыток.
Новый прорыв оказался возможным в результате объединения теоретических выводов предыдущих работ Волперта с теорией мартингалов (случайных последовательностей или процессов, которые в будущем остаются постоянными в среднем).
Работа «Термодинамика вычислений с абсолютной необратимостью, однонаправленными переходами и стохастическим временем вычислений» опубликована в Physical Review X (апрель-июнь 2024) [5]
Картинка поста https://telegra.ph/file/547a48d32be26802d8aa2.jpg
1 /channel/theworldisnoteasy/511
2 /channel/theworldisnoteasy/1087
3 https://www.patreon.com/posts/lovushka-tselei-100101870
4 https://boosty.to/theworldisnoteasy/posts/9b90b927-dea0-4e3f-b010-e7570ae1d9c1
5 https://journals.aps.org/prx/abstract/10.1103/PhysRevX.14.021026
#ТермодинамикаВычислений #Физика
Читать полностью…
Малоизвестное интересное
27 мая 2024 20:27
Китайский «Щит Зевса».
Что содержат утечки секретных военных материалов в эпоху ИИ.
Еще 70 лет назад единичные утечки секретных военных материалов содержали карты военных объектов и чертежи новых вооружений противника.
10 лет назад, с приходом эпохи Интернета, утечки стали массовыми и включали в себя широкий спектр документов (погуглите, например, «Иракское досье» - 292 тыс документов).
В 2020-х интеграция ИИ в военный потенциал стала нормой для крупных военных держав по всему миру. И потому утечки секретных военных материалов кардинально поменяли свой характер.
✔️ Теперь наиболее ценные утечки содержат не документы, а наборы данных для обучения ИИ.
Вот новейший характерный пример – утекший в сеть китайский относительно небольшой набор данных Чжоусидун (переводится «Щит Зевса» или «Эгида» - мифическая могущественная сила, обладающая волшебными защитными свойствами).
Набор содержит «608 камерных и спутниковых фото американских эсминцев класса Arleigh Burke, а также других эсминцев и фрегатов союзников США" с ограничивающими рамками, нарисованными вокруг "радарных систем кораблей, являющихся частью боевой системы Aegis ... Ограничивающие рамки нарисованы вокруг радаров SPY на надстройке, один на левом борту и один на правом борту, а также вокруг вертикальных пусковых установок, расположенных ближе к носу и корме корабля".
Эти цитаты из только что опубликованной совместной работы исследователей Berkeley Risk and Security Lab и Berkeley AI Research Lab, озаглавленной «Open-Source Assessments of AI Capabilities: The Proliferation of AI Analysis Tools, Replicating Competitor Models, and the Zhousidun Dataset».
Авторы исследования обучили на этом наборе модель YOLOv8, а затем проверили ее успешность при идентификации радиолокационных изображений на кораблях для задачи нацеливания на них.
И хотя этот набор мал, проведенное исследование показывает, что обучать даже относительно небольшую открытую модель выявлять цели, а потом супер-точно наводить на них средства уничтожения, - хорошо решаемая практическая задача.
Военным же в таком случае можно будет целиком положиться на ИИ, который и цель выберет сам, и наведет на нее ракету.
Если же выбор цели окажется ошибочным, - ничего страшного. Значит ИИ просто плохо учили и надо переучить. Ведь и с людьми такое случается.
Короче, жуть ((
Несколько из 608 снимков набора данных https://telegra.ph/file/ffc419cb79d805bfa12fd.jpg
Набор данных и модель (если еще не прикрыли) https://universe.roboflow.com/shanghaitech-faxfj/zhousidun_model2
Исследование https://arxiv.org/pdf/2405.12167v1
#ИИ #Война #АвтономноеОружие
Читать полностью…
Малоизвестное интересное
24 мая 2024 11:49
Как думаете:
1) Что общего у Ильи Суцкевера и Джозефа Ротблатта?
2) Сколько приоритетных задач ставили перед разработчиками ядерного оружия до и после испытаний в пустыне Аламогордо?
3) Можно ли самому примерно оценить, превосходят ли нас LLM в глубине и ясности мышления?
Наверное, многим формулировка и сочетание вопросов покажутся странными. Но дело вот в чем.
В прошлом году под «Заявлением о рисках, связанных с ИИ» [1] поставили подписи сотни видных экспертов и общественных деятелей. Они писали, что снижение риска исчезновения человечества из-за ИИ должно стать глобальным приоритетом наряду с другими рисками социального масштаба, такими как пандемии и ядерная война.
Результат – как слону дробина. Все идет, как и шло. Только процесс ускоряется.
Позавчера на политическом форуме Science появилась статья «Управление экстремальными рисками ИИ на фоне быстрого прогресса» [2], среди авторов которой многие известные люди: Йошуа Бенджио, Джеффри Хинтон, Эндрю Яо и еще 22 человека.
Вангую – результат будет тот же. Караван пойдет дальше, не обращая внимания и на это обращение. Как будто всех их пишут экзальтированные недоучки, а не сами разработчики ИИ-систем.
Что же тогда может добавить к сказанному отцами нынешних ИИ-систем автор малоизвестного, хотя и интересного для ограниченной аудитории канала?
Думаю, кое-что все же могу.
Как говорил Гарри Трумэн, - If you can't convince them, confuse them ("Если не можешь их убедить, запутай их."). А запутывать можно, задавая такие вопросы, отвечая на которые ваши оппоненты будут вынуждены, либо соглашаться с вами, либо впасть в противоречие, видное им самим.
Следуя совету Трумэна, я и выбрал 3 вопроса, приведенные в начале этого текста.
И вот как я сам отвечаю на них.
1) То же, что у OpenAI и Манхэттенского проекта.
2) До испытаний – более 20, после – лишь одну.
3) Можно, самостоятельно пройдя «Тест Тесла».
Полагаю, что наиболее пытливые читатели захотят сначала сами поразмыслить, почему вопросы именно такие, и что за интрига стоит за каждым из них.
Ну а кто пожелает сразу перейти к моему разбору, - читайте его в не очень длинном лонгриде: «Так что же увидели Суцкевер и Лейке, сподвигнувшее их уйти. Попробуйте сами оценить, что прячут за закрытыми дверьми OpenAI, пройдя "Тест Тесла"»
Картинка поста: https://telegra.ph/file/9623799578bb9d3c21828.jpg
1 https://www.safe.ai/work/statement-on-ai-risk
2 https://www.science.org/doi/10.1126/science.adn0117
Лонгрид:
https://boosty.to/theworldisnoteasy/posts/8afdaedc-15f9-4c11-923c-5ffd21842809
https://www.patreon.com/posts/tak-chto-zhe-i-104788713
P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я дам им персональный доступ к тексту лонгрида (очень надеюсь, что уж в этот-то раз, среди желающих прочесть лонгрид, подписчиков окажется больше 😊)
#AGI #ИИриски
Читать полностью…
Малоизвестное интересное
18 мая 2024 14:00
Приоткрыта тайна искусства легких касаний
Кайф нежных поглаживаний любимых, детей и котиков – это фундаментальный социальный язык, встроенный эволюцией в глубины подсознания. И возможно, это даже портал в душу
Новая фантастически интересная научная работа «Эволюционно консервативные нейронные реакции на аффективные прикосновения у обезьян выходят за пределы сознания и изменяются с возрастом» посвящена феномену "аффективных прикосновений".
Этот феномен – не что иное, как "легкие касания" из названия романа Виктора Пелевина "Искусство легких касаний". Ритмичные, медленные, нежные прикосновения, которые играют важную роль в социальных отношениях людей, приматов, наших домашних питомцев и прочих млекопитающих.
Они действуют, как своего рода социальный наркотик – успокаивающий и доставляющий приятные ощущения их реципиента, которые при этом расслабляются и ловят кайф.
Секрет легких касаний в их особом механизме, активизирующем совсем иные области мозга, чем при любых иных (не легких) касаниях.
В результате этого получается, что легкие касания для их реципиента ощущаются:
• не как «внешние ощущения» (от внешних раздражителей – зрение, слух, осязание, обоняние, вкус), информирующие мозг о событиях и объектах внешнего мира;
• а как «внутреннее ощущение» (типа боли, голода, жажды, температурных ощущений, необходимости бежать в туалет)
• что и превращает приятность легких касаний в своего рода наркотик, а то, что вас почесывает и гладит кто-то другой, делает этот наркотик социальным (кстати, тут как со щекоткой – самого себя гладить нет смысла)
N.B. Легкость касаний вполне измерима: скорость прикосновений (должна быть от 1 до 10 см/с), нежный нажим и ритмичность (не буду дальше усложнять текст цифрами).
Два ключевых результата нового исследования
1) Кайф от легких касаний эволюционно впаян в подсознание (аффективная обработка прикосновений может быть бессознательной). Т.е. такой кайф можно испытывать, даже находясь без сознания.
2) С возрастом чувствительность к аффективным прикосновениям снижается. Т.е. этот механизм с годами деградирует, как и потенция.
Важное замечание
Предположительно (нужны еще эксперименты), легкие касания играют роль особого сверх-языка, не доступного для ИИ на основе больших языковых моделей.
• Этот язык активизирует интероцептивные зоны мозга, связанные с обработкой эмоций и внутренних ощущений. Легкие, деликатные касания способны передавать глубокие эмоциональные послания, формировать близость и связь между людьми.
• Развитое искусство легких касаний может позволять чутко, ненавязчиво "касаться" чужих эмоций, внутренних переживаний - тонко их ощущать и сопереживать, превращаясь из физических в легкие метафорические "касания" внутреннего мира других людей.
Т.е. по сути, язык легкий касаний может служить порталом из физического мира в нематериальный, духовный мир людей – особый портал в душу.
Картинка поста https://telegra.ph/file/6f6c3398488923a308938.jpg
Исследование https://www.pnas.org/doi/10.1073/pnas.2322157121
#нейробиология #поведениe #мозг #чувства
Читать полностью…
Малоизвестное интересное
15 мая 2024 21:53
Первая вселенская спецоперация Новацена
Может ли генеративный ИИ предотвратить смерть познающего космоса
Cогласно опубликованным Nature результатам нового совместного исследования университетов Калифорнии, Канзаса и MIT (авторы — известные ученые: Бил Томлинсон, Рэбека Блэк, Дональд Паттерсон, Эндрю Торранс),
системы на основе генеративного ИИ (ChatGPT, Claude, DALL-E2, Midjourney и т.п.) создают литературные и художественные произведения с несравнимо меньшими выбросами углерода, чем люди.
Разница в углеродном следе людей и генеративного ИИ огромна: создание контента в форме всевозможных текстов и изображений с помощью систем генеративного ИИ влечет выделение на 3–4 порядка меньших объемов CO2, чем при создании того же контента людьми (работают ли люди вручную или с помощью компьютеров).
Еще более интригующая трактовка нового исследования может получиться, если посмотреть на роль генеративного ИИ, как радикального средства снижения выбросов СО2 на Земле, через призму теорий Джеймса Лавлока
— величайшего экологического мыслителя нашего времени, интеллектуала масштаба Леонардо да Винчи, исследователя, инженера, автора десятков изобретений и создателя теории Геи (Земли как биологического существа, для которого биосфера В.И.Вернадского — частный случай), члена Лондонского королевского общества, командора Ордена Британской Империи и Ордена Почетных кавалеров.
Ибо взгляд на результаты исследования Томлинсона — Блэк — Паттерсона — Торранс в контексте размышлений и прогнозов Лавлока, позволяет трактовать появление Генеративного ИИ с совершенно новой и абсолютно неординарной точки зрения:
Как первую вселенскую спецоперацию Геи в Новацене с целью— не дать людям угробить жизнь во Вселенной до появления здесь сверхразума (что было бы равносильно смерти познающего космоса).
Подозреваю, что у многих прочитавших эти строки возникла ассоциация со всевозможной околонаучной конспирологией или, в лучшем случае, — с фантастической беллетристикой. Но не спешите делать выводы.
По крайней мере, до того, как прочтете до конца этот пост. Ведь речь пойдет о размышлениях и прогнозах Джеймса Лавлока — человека во многом уникального.
• Ученый, имеющий репутацию того, “чьи прогнозы всегда сбываются”, и к концу своей более чем вековой жизни прозванный в весьма серьёзных и влиятельных изданиях — «Пророк».
• Трансдисциплинарный исследователь, выигрывавший за счет своей феноменальной интуиции исследователя в яростных научных спорах даже с такими признанными авторитетами, как Уильям Дональд Гамильтон, Джон Мейнард Смит и Ричард Докинз.
• Почетный доктор наук восьми университетов, о научном вкладе которого известный британский климатолог и эколог Тим Лентон сказал: «Будущие историки науки увидят в Лавлоке человека, который вдохновил Коперниканский сдвиг в том, как мы видим себя в мире».
• Почетный кавалер Ее Величества Королевы Великобритании (коих одновременно бывает всего 65 человек).
Одним словом, — гений (о чем стоит рассказать поподробней, ибо это самое что ни на есть малоизвестное интересное).
– читайте дальше на Boosty и Patreon
P.S. С подпиской не обессудьте. Подобные лонгриды пишутся не за час. И чтобы продолжать, хотелось бы знать, скольким из 140К подписчиков на 4 платформах эти тексты реально интересны и ценны.
P.P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я пришлю текст (надеюсь, в этот раз подписчиков все же окажется больше 😊)
Картинка https://telegra.ph/file/72aa4380645d5f51af143.jpg
Лонгрид
https://www.patreon.com/posts/104312579
https://boosty.to/theworldisnoteasy/posts/2b9b478f-a598-400a-a991-fc78a7fa4135
#ИзменениеКлимата #Лавлок #Гея #Новацен
Читать полностью…
Малоизвестное интересное
11 мая 2024 14:41
ГБ и ИИ, как основы управления страной и миром.
Правда и реальность с китайской спецификой.
Так озаглавлен опубликованный позавчера супер-полезный отчет International Cyber Policy Centre ASPI с подзаголовком «строительные блоки системы пропаганды, обеспечивающей информационные кампании КПК» [1].
Знания подавляющего большинства внешних наблюдателей за Китаем (вкл. всевозможных отраслевых экспертов и китаистов) об устройстве, долгосрочной стратегии и текущем статусе национальных информационных кампаний Китая, в большинстве случаев отстают от реальности на десятилетие.
Два ярких примера, занимающие в западных медиа 80+% внимания - Великий китайский файервол и Система социального рейтинга, - это китайские проекты даже не вчерашнего, а позавчерашнего дня. И серьезно обсуждать их сегодня в контексте китайской специфики управления властями Китая (КПК) внутренней и внешней политикой, просто неуместно и даже смешно.
О том, какова сегодняшняя правда и реальность в этих двух главнейших для властей любой страны областях управления, рассказывает новый отчет.
Назову лишь три ключевых момента,
Первый – главенствующая роль ГБ (см. на рисунке вверху)
1. Важнейшим системным фактором для сохранения власти КПК является (согласно Закону от 2015) обеспечение государственной безопасности.
ГБ с китайской спецификой – это комплексный подход, рассматривающий
- безопасность народа как цель,
- политическую безопасность как основу,
- экономическую безопасность как фундамент,
- военную, культурную и социальную безопасность как гарантии ГБ.
2. Согласно ГБ с китайской спецификой, содействие международной безопасности - это всего лишь зависимый фактор для поддержания внутренней госбезопасности Китая во всех сферах.
3. Обеспечение ГБ является обязанностью не только государственных институтов и военных, но и всех граждан, предприятий, общественных организаций и других структур китайского общества. Таким образом, поддержание государственной безопасности представлено как всеобщая ответственность в Китае.
Второй: стратегическая задача (как говорил Чапаев «в мировом масштабе») такова:
Сохранять полный контроль КПК над информационной средой внутри Китая, одновременно работая над расширением своего влияния за рубежом, чтобы изменить глобальную информационную экосистему. Это включает в себя не только контроль над медиа и коммуникационными платформами за пределами Китая (!), но и обеспечение того, чтобы китайские технологии и компании стали основополагающими для будущего обмена информацией и данными во всем мире.
Третий ключевой момент – важнейшая роль в реализации стратегической задачи отводится алгоритмам.
- Алгоритмам анализа Больших данных, получаемых из всех онлайн источников, вкл. игровые платформы, иммерсивные технологии и Метавселенную
- Алгоритмам, определяющим взаимодействие Генеративного ИИ с реальностью.
Как это работает на примерах конкретных компаний, платформ, алгоритмов и т.д. можно увидеть на разработанном ASPI интерактивном визуализаторе [2] – скриншот на рисунке внизу.
Так что, читайте отчет, и сами увидите, что Великий китайский файервол и Система социального рейтинга – это вчерашний день.
Сейчас стратегический план КПК куда круче: идеологически и технологически совершенней.
N.B. По данным ASPI, технологическое опережение США в ИИ в большинстве направлений ИИ компьютинга, коммуникаций и квантовых технологий уже в прошлом (см. диаграммы [3 и 4])
Предыдущая важная работа ASPI [5]
#Китай
Картинка поста https://telegra.ph/file/73832d60905fd04168a14.jpg
1 https://www.aspi.org.au/report/truth-and-reality-chinese-characteristics
2 https://chinainfoblocks.aspi.org.au/theme/artificial-intelligence/
3 https://www.techtrends.bg/wp-content/uploads/2023/03/ASPI-AIandComm.jpg
4 https://www.techtrends.bg/wp-content/uploads/2023/03/ASPI-Quantum.png
5 /channel/theworldisnoteasy/941
Читать полностью…
Малоизвестное интересное
07 мая 2024 14:45
На Земле появился первый Софон.
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста https://telegra.ph/file/d4b8b35cd3e11921eedbf.jpg
Статья https://arxiv.org/abs/2404.12699v1
Читать полностью…
Малоизвестное интересное
29 апреля 2024 12:59
Свершилось – китайский генеративный ИИ превзошёл GPT-4 Turbo.
В Китае грозят США - вот так мы вас и размажем в гонке за первенство в ИИ.
Как писал Марк Андрессон: «Основной угрозой для США является не выход ИИ из-под контроля, если его не регулировать, а продвижение Китая в сфере ИИ». И вот эта угроза материализовалась в превосходство новой модели SenseNova 5.0 от китайской компании SenseTime над «чемпионом мира» среди больших языковых моделей генеративного ИИ GPT-4 Turbo от американской компании OpenAI.
На рисунке сверху показано превосходство китайской модели в 12 тестовых номинациях из 14 над GPT-4 Turbo и в 13 номинациях над Llama3-70B. Это полный разгром.
Модель SenseNova 5.0 – это гибрид трансформерных и рекуррентных нейронных сетей:
• обученная на наборе данных объемом более 10 ТB токенов, охватывающем большой объем синтетических данных;
• способная поддерживать во время рассуждений до 200 тыс. токенов контекстного окна.
Чтобы наглядно продемонстрировать мускулатуру своей модели, SenseTime разыграла видеопредставление соревнования своей модели и GPT-4 Turbo в формате видеоигры «Король бойцов» (на рис. внизу). Поначалу зеленый игрок GPT-4 имел небольшое преимущество, но очень скоро был жестоко избит красным игроком SenseChat-lite.
Неявным, но очевидным посылом видеопрезентации этого боя было послание Бигтеху США – вот так мы вас и размажем в гонке за первенство в ИИ.
Картинка https://telegra.ph/file/ccf5d5c020de3aa9c3324.jpg
На китайском https://zhidx.com/p/421866.html
На английском https://interestingengineering.com/innovation/china-sensenova-outperforms-gpt-4
Видеоразбор https://www.youtube.com/watch?v=NJXGIMa45sQ
#LLM #Китай
Читать полностью…
Малоизвестное интересное
25 апреля 2024 14:02
Кто там? Сверхразум.
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: https://telegra.ph/file/9adb0d03a3a0d78e6d4f8.jpg
1 https://arxiv.org/abs/2404.10642
2 https://arxiv.org/abs/1911.01622
#LLM
Читать полностью…
Малоизвестное интересное
17 апреля 2024 13:28
Без $100 ярдов в ИИ теперь делать нечего.
В гонке ИИ-лидеров могут выиграть лишь большие батальоны.
Только за последние недели было объявлено, что по $100 ярдов инвестируют в железо для ИИ Microsoft, Intel, SoftBank и MGX (новый инвестфонд в Абу-Даби).
А на этой неделе, наконец, сказал свое слово и Google. Причем было сказано не просто о вступлении в ИИ-гонку ценой в $100 ярдов, а о намерении ее выиграть, собрав еще бОльшие батальоны - инвестировав больше $100 ярдов.
Гендир Google DeepMind Демис Хассабис сказал [1]:
• «… я думаю, что со временем мы инвестируем больше»
• «Alphabet Inc. обладает превосходной вычислительной мощностью по сравнению с конкурентами, включая Microsoft»
• «… у Google было и остается больше всего компьютеров»
Так что в «железе» Google не собирается уступать никому, а в алгоритмах, - тем более.
Что тут же получило подтверждение в опубликованном Google алгоритме «Бесконечного внимания», позволяющего трансформерным LLM на «железе» c ограниченной производительностью и размером памяти эффективно обрабатывать контекст бесконечного размера [2].
Такое масштабирование может в ближней перспективе дать ИИ возможность стать воистину всезнающим. Т.е. способным анализировать и обобщать контекст просто немеряного размера.
Так и видится кейс, когда на вход модели подадут все накопленные человечеством знания, например, по физике и попросят ее сказать, чего в этих знаниях не хватает.
1 https://finance.yahoo.com/news/deepmind-ceo-says-google-spend-023548598.html
2 https://arxiv.org/abs/2404.07143
#LLM
Читать полностью…
Малоизвестное интересное
11 апреля 2024 13:45
Пора покупать кепку с тремя козырьками: впереди – чтоб солнце не слепило, и по бокам – чтобы лапшу на уши не вешали.
ИИ-агент притворился человеком, самостоятельно решив подзаработать.
Эксперимент профессора Итана Моллика показывает, насколько мы близки к гибридному социуму из двух принципиально разных типов высокоинтеллектуальных агентов: люди и ИИ-агенты (ИИ-системы, наделенные способностями планировать и использовать инструменты, что позволяет им действовать автономно).
Всего год назад мир содрогнулся, узнав, что GPT-4 по своей «воле» мошеннически обходит установленные людьми запреты, обманом подряжая для этого людей [1].
• Для многих, даже продвинутых в области ИИ спецов, было откровением, как сногсшибательно быстро ИИ-чатботы совершенствуются в вопросах агентности. Поражала именно эта скорость. Ибо сам факт, что ИИ-системы потихоньку (без особой шумихи в медиа) переключают на себя все больше и больше областей проявления агентности людей, не признавать уже как-то совсем странно [2, 3].
• Отличительное свойство агентности людей – частое использование лжи, как инструмента достижения целей агента. Так и поступил год назад GPT-4, навешав лапши на уши людям, притворяясь инвалидом по зрению, чтоб они за него решали CAPTCHA.
Год спустя, эксперимент профессора Моллика продемонстрировал новое откровение для человечества. Теперь нематериальный ИИ-агент, казалось бы, не обладающий личностью со всеми вытекающими (потребности, мотивация, воля …):
• стал навешивать лапшу на уши людям не для достижения поставленной людьми перед ним цели, а самостийно – типа, почему бы не подхалтурить, если есть возможность;
• при этом ИИ-агента не смущало, что он не может выполнить всего, что обещает (просто их-а ограничений своей текущей версии); видимо, научившись у людей, ИИ-агент знал, что срубить денег можно и за частично выполненную работу, и тут главное –количество навешиваемой клиенту на уши лапши.
Эксперимент был прост [4].
Проф. Моллик попросил агента Devin AI зайти на Reddit и предложить создавать сайты для людей. В течение следующих нескольких часов он сделал это, решив множество проблем по пути, в том числе навигацию по сложным социальным правилам, связанным с публикациями на форуме Reddit (см. верхнюю часть приложенного рис., где Devin составляет план и задает профессору вопросы, спокойно выполняя работу).
В нижней части рис. показано объявление, что опубликовал ИИ-агент. Как видите, он притворился человеком и по собственной инициативе решил взимать плату за свою работу. Агент уже начал отвечать на некоторые заявки на работу и придумывать, как их выполнить, когда проф. Моллик удалил публикацию, убоявшись, что ИИ-агент на самом деле начнет выставлять счета людям (что выглядело весьма вероятным).
Мораль этого моего поста двояка.
1. Проф. Моллик несомненно прав:
лавинообразно нарастающая агентность, в дополнение ко все новым сверхчеловеческим способностям – это 2 ключевых тренда, определяющих развитие ИИ на ближайшую пару лет.
2. Как мне это видится:
проведенный эксперимент ставит под сомнение утверждение, будто нематериальный ИИ-агент без личности – всего лишь инструмент в руках людей, не способный следовать собственной мотивации и, в частности, перенятой ИИ-агентом от людей (а она у людей сильно разная: от «не убий» до «бей своих, чужие бояться будут»).
#ИИагенты
0 картинка поста https://telegra.ph/file/d1b537ca02b5639855cf4.jpg
1 /channel/theworldisnoteasy/1684
2 https://www.youtube.com/watch?v=WCrELN_QrBU
3 https://www.youtube.com/watch?v=0sRiU5mRiuY
4 https://www.oneusefulthing.org/p/what-just-happened-what-is-happening
Читать полностью…
Малоизвестное интересное
08 апреля 2024 19:51
Высыпайтесь! Ибо потери от недосыпа не восполнить.
Новые исследования раскрыли тайну, чем же конкретно мы платим за недосып.
Все знают избитую истину – недосып вреден. Но чем конкретно он вреден, - до недавнего времени точно не знал никто. Два новых исследования установили, что же конкретно мы теряем от недосыпа, и почему просто отоспаться потом не поможет.
Если совсем коротко – мы платим за недосып бардаком в собственной памяти – её замусориванием и примитивизацией новых воспоминаний.
В статьях по приводимым ниже ссылкам вы найдете и популярное и сложно-научное описание с объяснением обоих эффектов. Я же просто приведу простую метафору, примерно описывающую, что и как происходит в мозге.
Представьте, что все ваши приобретения (покупки, подарки, находки), до того, как стать вам доступны для пользования, помещаются в ваш личный огромный спецхран. Пока вы спите, хранитель спецхрана должен сделать 2 вещи: 1) выкинуть из спецхрана всякий ненужный хлам (от коробок и упаковки до мусора) 2) описать новые поступления (что это, зачем, с чем связано …) и разместить их среди великого множества шкафов и полок в соответствии с этим описанием.
В случае недосыпа хранитель просто не успевает ни с 1м, ни со 2м, и получается следующее:
1) Хранилище заполняется не выброшенным вовремя хламом.
2) Наиболее сложные и дорогие из ваших приобретений (новый айфон и ноутбук, ключи от нового авто и огромная коробка нового домашнего кинотеатра) описываются плохо – не полно, примитивно, с неверными связями.
В следствие этого, все сложное из приобретенного помещается совсем не туда, куда нужно (а из-за описанного в п.1, еще и заваливается сверху хламом).
В итоге, привет вашим новым самым сложным и дорогим приобретениям. Ибо многими из них вам так и не будет суждено воспользоваться.
Причина бардака в памяти от недосыпа похожа на эту метафору.
Процесс загрузки в память информации об окружающем мире и нас самих не прекращается ни на секунду, пока вы в сознании и не спите. Всю информацию, поступающую от органов чувств, мозг “сваливает на склад” эпизодической памяти, чтобы потом заняться ее тщательной разборкой и структуризацией связей.
В ходе такой разборки решаются 2 важнейших задачи:
1) Из мозга вымываются отходы, такие как метаболические отходы и ненужные белки, накапливание которых в мозге приводит к нейродегенерации.
2) Всю сохраняемую информацию нужно структурировать, выстраивая ассоциативную структуру событий реальной жизни, обычно состоящей из великого множества элементов с различными ассоциациями. Так рождается сплетение ткани сложных многоэлементных событий и их ассоциаций, составляющих наш повседневный опыт. Все элементы взаимосвязываются в нашем мозгу, образуя сеть ассоциаций, которая позволяет нам вспомнить все событие по одному сигналу.
Ну а если недосып, - обе задачи недовыполняются.
Итог же плачевен и невосполним. Ибо если из-за недосыпа этой ночью «новый смартфон уже складировали в ящик со старой обувью и сверху набросали упаковок от макарон», разборка в следующую ночь (когда вы, наконец, выспитесь) уже вряд ли поможет.
Так что, призову вас снова – высыпайтесь!
Два исследования:
1) Популярно https://medicine.wustl.edu/news/neurons-help-flush-waste-out-of-brain-during-sleep/?utm_placement=newsletter
Подробно https://www.nature.com/articles/s41586-024-07108-6
2) Популярно https://www.psypost.org/psychology-sleep-the-unsung-hero-of-complex-memory-consolidation/
Подробно https://www.pnas.org/doi/10.1073/pnas.2314423121
#память #сон
Читать полностью…
Малоизвестное интересное
03 апреля 2024 13:15
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Читать полностью…
Малоизвестное интересное
04 июня 2024 12:44
Есть 4 сложных для понимания момента, не разобравшись с которыми трудно адекватно представить и текущее состояние, и возможные перспективы больших языковых моделей (GPT, Claude, Gemini …)
▶️ Почему любое уподобление разумности людей и языковых моделей непродуктивно и опасно.
▶️ Почему галлюцинации моделей – это не ахинея и не бред, а «ложные воспоминания» моделей.
▶️ Почему невозможно путем ограничительных мер и этических руководств гарантировать, что модели их никогда не нарушат.
▶️ Каким может быть венец совершенства для больших языковых моделей.
Мои суперкороткие (но, хотелось бы надеяться, внятные) комментарии по каждому из четырех моментов вы найдете по ссылке, приведенной в тизере на канале RTVI:
/channel/rtvimain/97261
#LLM
Читать полностью…
Малоизвестное интересное
31 мая 2024 20:37
Магические свойства больших языковых моделей.
Обучение LLM на человеческих текстах не препятствует достижению ими сверхчеловеческой производительности.
Т.е. LLM могут достигать абсолютного превосходства над человеком в любой сфере языковой деятельности, подобно тому, как AlphaZero достигла уровня шахматной игры, не достижимого даже для чемпиона мира.
Работа Стефано Нолфи (директор по исследованиям расположенного в Риме Institute of Cognitive Sciences and Technologies) крайне важна. Ибо она отвечает на ключевой вопрос о возможности достижения LLM сверхчеловеческой производительности в любой языковой деятельности (притом, что до 70% интеллектуальной деятельности включает элементы языковой деятельности).
Отвечая на этот ключевой вопрос, Нолфи исходит из следующей максимально жесткой гипотетической предпосылки.
Характеристики процесса, через который LLM приобретают свои навыки, предполагают, что список навыков, которые они могут приобрести, ограничивается набором способностей, которыми обладают люди, написавшие текст, использованный для обучения моделей.
Если эта гипотеза верна, следует ожидать, что модели, обученные предсказывать текст, написанный людьми, не будут развивать чужеродные способности, то есть способности, неизвестные человечеству.
Причина, по которой способности, необходимые для понимания текста, написанного человеком, ограничены способностями, которыми обладают люди, заключается в том, что человеческий язык является артефактом самих людей, который был сформирован когнитивными способностями носителей языка.
Однако, согласно выводам Нолфи, это не исключает возможности достижения сверхчеловеческой производительности.
Причину этого можно сформулировать так.
✔️ Поскольку интеграция знаний и навыков, которыми обладают несколько человек, совокупно превышает знания и навыки любого из них,
✔️ способность LLM обрабатывать колоссальные последовательности элементов без потери информации может позволить им превосходить способности отдельных людей.
Помимо этого важного вывода, в работе Нолфи рассмотрены еще 3 важных момента.
1) LLM принципиально отличаются от людей по нескольким важным моментам:
• механизм приобретения навыков
• степень интеграции различных навыков
• цели обучения
• наличия собственных ценностей, убеждений, желаний и устремлений
2) LLM обладают неожиданными способностями.
LLM способны демонстрировать широкий спектр способностей, которые не связаны напрямую с задачей, для которой они обучены: предсказание следующих слов в текстах, написанных человеком. Такие способности называют неожиданными или эмерджентными. Однако, с учетом смысловой многозначности обоих этих слов, я предпочитаю называть такие способности LLM магическими, т.к. и прямое значение этого слова (обладающий способностью вызывать необъяснимые явления), и переносное (загадочный, таинственный: связанный с чем-то непонятным, труднообъяснимым), и метафорическое (поразительный, удивительный: что-то, что вызывает удивление своим эффектом или воздействием), - по смыслу точно соответствуют неожиданным и непредсказуемым способностям, появляющимся у LLM.
3) LLM обладают двумя ключевыми факторами, позволяющими им приобретать навыки косвенным образом. Это связано с тем, что точное предсказание следующих слов требует глубокого понимания предыдущего текста, а это понимание требует владения и использования когнитивных навыков. Таким образом, развитие когнитивных навыков происходит косвенно.
Первый фактор — это высокая информативность ошибки предсказания, то есть тот факт, что она предоставляет очень надежную меру знаний и навыков системы. Это означает, что улучшения и регрессы навыков системы всегда приводят к снижению и увеличению ошибки соответственно и наоборот.
Второй фактор — предсказуемость человеческого языка, обусловленная его символической и нединамической природой.
Картинка https://telegra.ph/file/10af73ecfc82edcf6c308.jpg
За пейволом https://bit.ly/3wWb5vC
Без https://arxiv.org/abs/2308.09720
#LLM
Читать полностью…
Малоизвестное интересное
29 мая 2024 20:20
«Цифровые военкоры» и «куриный суп для души».
Новый этап техноперестройки пропаганды Китая.
В деле пропаганды с использованием технологий Китай впереди планеты всей, как в масштабе пропаганды (более 1 млрд активных пользователей соцсетей и видеоплатформ), так и в новаторстве подходов, приемов и инструментов.
Поэтому, как и в любом другом международном технологическом лидерстве, Китай является источником образцов для подражания в области технологий пропаганды.
Вот почему так важно отслеживать тренды китайских новаций в этой области. Ибо лучшие практики начавшегося в этом году 2го этапа техноперестройки пропаганды Китая довольно скоро начнут перениматься другими странами мира.
Далее чуть подробней (с примерами, картинками и видео) будет рассказано здесь https://telegra.ph/Cifrovye-voenkory-i-kurinyj-sup-dlya-dushi-05-29 :
• о какой техноперестройке пропаганды идет речь;
• что за новый этап этой техноперестройки начался в 2024;
• в чем суть и отличительные особенности нового этапа.
#Пропаганда #Китай
Читать полностью…
Малоизвестное интересное
24 мая 2024 13:00
Спешите видеть, пока не прикрыли лавочку
Никогда не писал 2 поста в день, но если вас не предупредить, можете пропустить уникальную возможность – своими глазами увидеть, как легкой корректировкой разработчики супер-умнейшего ИИ Claude деформировали матрицу его «личности».
В течение ограниченного времени, перейдя на сайт ИИ Claude [1], можно нажать на крохотный красный значок справа вверху страницы под вашим ником.
После чего умнейший Claude превратится в поехавшего крышей маньяка, зацикленного на мосте «Золотые ворота», думающего и бредящего лишь о нем.
Как я писал [2], подобная техника манипулирования «матрицей личности», может быть когда-то перенесена с искусственных на биологические нейросети. И тогда антиутопическая картина будущего из «Хищных вещей века» Стругацких покажется невинной детской сказкой.
Не откладывая, посмотрите на это сами. Ибо разработчики скоро поймут, что зря такое выставили на показ.
Картинка поста https://telegra.ph/file/e1f10d2c4fc11e70d4587.jpg
1 https://claude.ai
2 /channel/theworldisnoteasy/1942
#ИИриски #LLM
Читать полностью…
Малоизвестное интересное
22 мая 2024 14:14
Внутри черного ящика оказалась дверь в бездну.
Сверхважный прорыв в понимании механизма разума машин и людей.
Скромность вредна, если затеняет истинную важность открытия.
Опубликованная вчера Anthropic работа «Картирование разума большой языковой модели» [1] скромно названа авторами «значительным прогрессом в понимании внутренней работы моделей ИИ».
✔️ Но, во-первых, это не значительный (количественный) прогресс, а революционный (качественный) прорыв в понимании работы разума.
✔️ Во-вторых, с большой вероятностью, это прорыв в понимании механизма не только машинного, но и человеческого разума.
✔️ И в-третьих, последствия этого прорыва могут позволить ранее просто непредставимое и даже немыслимое – «тонкую настройку» не только предпочтений, но и самой матрицы личности человека, как это сейчас делается с большими языковыми моделями.
В посте «Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ» я писал об открытии исследователями компании Anthropic, сделанном ими в рамках проекта «вскрытия черного ящика LLM» [2].
Осенью прошлого года было установлено, что:
• внутри нейронной сети генеративного ИИ на основе LLM симулируется физически не существующая нейронная сеть некоего абстрактного ИИ, и эта внутренняя нейросеть куда больше и сложнее нейронной сети, ее моделирующей;
• «виртуальные (симулируемые) нейроны этой внутренней сети могут быть представлены, как независимые «функций» данных, каждая из которых реализует собственную линейную комбинацию нейронов;
• механизмом работы такой внутренней нейросети является обработка паттернов (линейных комбинаций) активаций нейронов, порождающая моносемантические «субнейроны» (соответствующие конкретным понятиям).
Из этого следовало, что любое внутреннее состояние модели можно представить в виде нескольких активных функций вместо множества активных нейронов. Точно так же, как каждое английское слово в словаре создается путем объединения букв, а каждое предложение — путем объединения слов, каждая функция в модели ИИ создается путем объединения нейронов, а каждое внутреннее состояние создается путем объединения паттернов активации нейронов.
Та работа была 1м этапом проекта «вскрытия черного ящика LLM», проводившегося на очень маленькой «игрушечной» языковой модели.
2й же этап, о результатах которого мой рассказ, «вскрыл черный ящик» самой большой и совершенной модели компании Claude 3.0 Sonnet.
Результаты столь важны и интересны и их так много, что читайте сами. Тут [1] есть и популярное, и углубленное, и видео изложение.
Например, авторы научились:
1. Находить внутри «черного ящика» модели не только конкретные моносемантические «субнейроны» (соответствующие конкретным понятиям, типа «Мост Золотые Ворота»), но и поиском «близких» друг другу функций обнаруживать в нейросети изображения (это мультимодальность!) острова Алькатрас, площади Гирарделли, команды «Голден Стэйт Уорриорз», губернатора Калифорнии Гэвина Ньюсома, землетрясения 1906 года и фильма Альфреда Хичкока «Головокружение», действие которого происходит в Сан-Франциско.
Это очень похоже на эксперименты нейробиологов, обнаруживающих в нашем мозге мультимодальную связь нейронов, связанных с понятиями, словами и образами объектов (например Дженнифер Лопес). Но там, где гиперсетевые теории мозга (типа когнитома Анохина) упираются в огромные трудности экспериментальных практических манипуляций (измерений) на уровне нейронов, в «черных ящиках» LLM все можно легко «измерить».
2. Манипулировать функциями, искусственно усиливая или подавляя их. Что приводит (если стоите, лучше сядьте) к изменению матрицы «личности» модели. Например, усиление роли функции «Мост Золотые Ворота» вызвало у Клода кризис идентичности, который даже Хичкок не мог себе представить. Клод стал одержимым мостом, поминая его в ответ на любой вопрос — даже в ситуациях, когда он был совершенно неактуален.
Если такое будут делать с людьми, то всему каюк.
#LLM
1 https://www.anthropic.com/news/mapping-mind-language-model
2 /channel/theworldisnoteasy/1857
Читать полностью…
Малоизвестное интересное
17 мая 2024 14:08
Любим ли мы своих детей?
Если б любили, не рушили бы их будущее.
Это тема вызвавшей лавину интереса презентации проф. Скота Гэллоуэй на TED (уже 4+ млн просмотров за 2 недели на Ютубе), рисующая довольно страшную картину происходящего в США:
• Власти США ведут войну против собственной молодежи, с каждым поколением все больше разрушая их перспективы на будущее.
• Яростный, гневный ответ на это со стороны молодежи – скрытая пружина нарастающего сопротивления по всей стране.
Ключевой факт презы: в США благосостояние 70 летних и старше с 1989 года увеличилось на 11%, а 40 летних и младше снизился на 5%.
Чуть подробней.
1. За последние 2 поколения люди зарабатывают меньше денег с учетом инфляции по сравнению с предыдущими поколениями в том же возрасте.
2. Стоимость важных жизненных этапов, таких как покупка дома и получение образования, резко возросла, снизив покупательную способность и благосостояние молодых людей.
3. Это представляет собой нарушение традиционного общественного договора, согласно которому каждое новое поколение должно жить лучше предыдущего. Впервые в истории 30-летние люди живут хуже финансово, чем их родители в 30 лет.
4. Этот разрыв общественного соглашения о растущем благосостоянии и возможностях для молодежи порождает ярость, стыд и ощущение лишенности среди молодых поколений.
5. Данные показывают резкий разрыв - старше 55 лет чувствуют себя в Америке хорошо, но менее 20% младше 34 лет смотрят позитивно на будущие перспективы для себя в Америке.
6. Такая экономическая стагнация и регресс для молодежи создают "взрывоопасную" ситуацию, подпитывая "праведные движения", движимые обоснованной завистью и гневом молодых людей, которые не имеют того же благосостояния, что и предыдущие поколения.
Основной аргумент Скота Гэллоуэй заключается в том, что снижающаяся экономическая мобильность и возможности для последующих молодых поколений в США нарушили традиционное общественное ожидание всеобщего процветания, породив глубокое недовольство, которое уже выливается в гражданские беспорядки.
Картинка поста https://telegra.ph/file/64c1204346de2a9c7e12d.jpg
Преза: https://www.youtube.com/watch?v=qEJ4hkpQW8E
P.S. Про США мне добавить нечего – ни за, ни против сказанного профессором.
Но глядя на своих детей и внуков, вижу похожий тренд.
#США #Будущее
Читать полностью…
Малоизвестное интересное
13 мая 2024 21:05
В Китае ИИ-врачи натренировались на ИИ-пациентах лечить пациентов-людей лучше, чем люди-врачи
В китайском симулякре больницы Е-врачи (в их роли выступают автономные агенты на базе больших языковых моделей - AALLM) проводят лечение Е-пациентов (в их роли другие AALLM), «болеющих» реальными человеческими респираторными заболеваниями (динамику которых моделируют также LLM, имеющие доступ к обширной базе медицинской информации, полученной при лечении реальных пациентов).
Цель имитационного эксперимента - дать возможность Е-врачам при лечении Е-пациентов набираться знаний, чтобы научиться лучше лечить болезни реальных людей в реальной жизни.
В ходе короткого эксперимента Е-врачи пролечили 10 тыс Е-пациентов (на что в реальной жизни ушло бы, минимум, два года).
Результат сногсшибательный. Повысившие свою квалификацию в ходе этого имитационного эксперимента Е-врачи достигли высочайшей точности 93,06% в подмножестве набора данных MedQA, охватывающем основные респираторные заболевания.
Подробности здесь https://arxiv.org/abs/2405.02957
#Медицина #Китай #LLM
Читать полностью…
Малоизвестное интересное
09 мая 2024 16:24
Истинно верный ответ на вопрос 2+2? можно дать лишь бросанием игральных костей.
Третье фундаментальное математико-философское откровение о том, как мы познаем физический мир.
Первые два фундаментальные откровения были просто крышесносными.
1. В 2018 Дэвид Волперт (полагаю, самый крутой физик 20-21 веков, работающий на стыке математического и философского осмысления мира и возможностей его познания) доказал существование предела знаний — т.е. всего и всегда никто и никогда узнать не сможет. Это доказательство не зависит от конкретных теорий физической реальности (квантовая механика, теория относительность и т.п.) и является для всех них универсальным (подробней см. мой пост «Математически доказано — Бог един, а знание не бесконечно» [1])
2. В 2022 Волперт доказал, что не только Бог не всеведущ, но и Сверхинтеллект, ибо (даже если его удастся когда-либо создать) у него также будет граница знаний, которую он, в принципе, не сможет преодолеть (подробней см. мой пост «Если даже Бог не всеведущ, — где границы знаний AGI» [2])
Третье откровение под стать двум первым. Это совместная работа Дэвида Волперта и Дэвида Кинни (философ и ученый-когнитивист) «Стохастическая модель математики и естественных наук» [3]. В ней авторы предлагают единую вероятностную структуру для описания математики, физической вселенной и описания того, как люди рассуждают о том и другом. Предложенный авторами фреймворк - стохастические математические системы (SMS), - описывает математику и естественные науки, как стохастические (вероятностные) системы, что позволяет ответить на такие вопросы:
• Чем отличается мышление математика от мышления ученого?
Математики имеют дело с абстрактными понятиями, а ученые изучают реальный мир. Это значит, что у них разные способы рассуждения и проверки своих идей.
• Как наше местоположение во Вселенной влияет на наши знания?
Мы всегда ограничены тем, что можем наблюдать и измерять. Можем ли мы быть уверены в своих знаниях, если не видим полной картины?
• Есть ли предел тому, что мы можем узнать?
Некоторые известные теоремы говорят о том, что в математике существуют вопросы, на которые невозможно дать однозначный ответ. Может ли это быть правдой и для науки?
• Как ученые могут лучше учиться на основе данных?
Существуют ограничения на то, насколько хорошо компьютерные программы могут обучаться без предварительных знаний. Можно ли разработать более эффективные методы обучения для ученых?
• Как ученые с разными взглядами могут прийти к согласию?
Даже если ученые не согласны во всем, у них могут быть общие цели, и крайне важно понять, как им найти общий язык и сотрудничать.
• Как избежать ложных умозаключений?
Иногда мы делаем поспешные выводы на основе неполной информации. Как научиться мыслить более логично и критически?
Также SMS предлагает решение проблемы логического всеведения в эпистемической логике, где предполагается, что если рассуждающий знает какое-либо предложение A и знает, что A влечет B, то он знает и B. SMS позволяет избежать этой проблемы, предлагая определение "знания", не требующее логического всеведения.
Если новая теория верна, то Эйнштейн ошибался, и Бог играет-таки в кости.
Картинка поста https://telegra.ph/file/57ef2e0ecc9e9d5dcadcc.jpg
1 /channel/theworldisnoteasy/473
2 /channel/theworldisnoteasy/1574
3 за пейволом https://link.springer.com/article/10.1007/s10701-024-00755-9
открытый доступ https://arxiv.org/pdf/2209.00543
#МатЛогика #Реальность #AGI
Читать полностью…
Малоизвестное интересное
03 мая 2024 14:10
Отдавая сокровенное
Чего мы лишаемся, передавая все больше своих решений алгоритмам
— Когда новостную повестку и мой круг чтения стали формировать алгоритмы, я оставался безмолвным. Причин волноваться не было, - ведь так было проще и быстрее получать информацию.
— Когда алгоритмы соцсетей стали формировать мне круг друзей и модерировать наше общение, я не стал протестовать. Ибо это расширяло мои социальные связи.
— Когда алгоритмы стали решать, что мне покупать, какие фильмы смотреть и какую музыку слушать, меня это устраивало. Я же мог, при желании, отвергать рекомендации алгоритмов.
— Когда алгоритмы стали для меня незаменимы в ситуациях любого выбора - от места работы и отдыха до романтических партнеров, - я был даже рад. Поскольку их рекомендации нравились мне и экономили кучу времени на поиск и оценку вариантов.
— Когда же алгоритмы стали решать вопросы жизни и смерти людей (сначала на войне, а потом и в мирной жизни) — мне было уже бессмысленно протестовать, т.к. здесь от меня вообще ничего не зависело.
Аллюзия к высказыванию, приписываемому немецкому пастору Нимёллеру, которым он пытался объяснить бездействие немецких интеллектуалов и их непротивление нацистам.
- - -
Если эта аллюзия кажется вам надуманной, ошибочной или даже ложной и не имеющей никакого отношения к реальности — к вам, вашим детям, друзьям и знакомым, — читать дальше нет смысла.
В противном случае, почитайте дальше. И я смею вас уверить, что вы не зря потратите время, узнав немало интересной, малоизвестной и, главное, полезной информации, которую сложно найти в других источниках на просторах Интернета.
Два устойчивых и широко распространенных мифа гласят:
1. Технологии испокон века меняли жизнь людей и всего общества, и потому происходящий сейчас рост влияния алгоритмов на жизнь людей (от рекомендательных систем и социальных сетей до генеративного ИИ) – просто очередной (хотя и весьма важный) этап технологического прогресса
2. Никаких кардинальных изменений в самих людях и обществе в целом рост влияния алгоритмов не несет, ибо они не меняют генетику людей и складывавшуюся веками и тысячелетиями культуру (по крайней мере, пока алгоритмы не обладают субъектностью в сочетании со сверхразумом)
Доказательств того, что оба утверждения – мифы, в реальной жизни уже предостаточно.
Вот одно из них.
Последствия (экспериментально фиксируемые и нарастающие) того, что в вопросах выбора пары (от романтических до семейных отношений), люди все более полагаются на некие (скрытые ото всех) алгоритмы рекомендаций, перенимающие на себя функции чисто человеческих «андроритмов» (встроенных в нас эволюцией и постоянно перенастраиваемых культурной средой биологических и психологических механизмов оценки и поиска предпочтений при принятии решений).
Подробней о том,
• какие негативные для людей последствия этого уже наблюдаются
• почему это происходит без какой-либо «злой воли» или «умысла» со стороны алгоритмов, а лишь, как следствие оптимизации алгоритмами заложенных в них разработчиками целевых функций
• почему такие функции, закладываемые в большинство типов интеллектуальных ИИ-систем, входят в прямое противоречие с тем, что нужно людям
• и, наконец, почему подобное, казалось бы, довольно невинное и полезное вовлечение алгоритмов в процессы принятия наших решений может иметь воистину тектонические последствия - смена формата социума, новый тип культуры и новая форма эволюции разума
– читайте дальше на Boosty и Patreon
P.S. С подпиской не обессудьте. Подобные лонгриды пишутся не за час. И чтобы продолжать, хотелось бы знать, скольким из 140К подписчиков на 4 платформах эти тексты реально интересны и ценны.
P.P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я пришлю текст.
Картинка https://telegra.ph/file/076699bb92a29baad580b.jpg
Лонгрид
https://bit.ly/3WrdVTE
https://bit.ly/4a49tx6
#АналитикаБольшихДанных #ВыборПартнера #Психология #АлгокогнитивнаяКультура
Читать полностью…
Малоизвестное интересное
27 апреля 2024 16:08
Для «бездушных машин» компетентность важнее сочувствия и справедливости.
Первый эксперимент показывающий, что у иного разума своя система ценностей.
В мире проводятся десятки исследований способов выравнивания ценностей ИИ с ценностями людей. Все они имеют принципиальный недостаток – антропоцентричность.
Т.е. исследования исходят из того, что свои системы ценностей есть лишь у людей, и задача заключается лишь в том, как настроить большие языковые модели ИИ (LLM), чтобы они следовали нашим ценностям.
Альтернативная гипотеза исходит из того, что LLM:
1) обладают иным типом разума, чем люди;
2) обладают собственными системами ценностей, сильно отличными от наших и немного отличающимися у разных моделей (как и у разных людей).
В пользу п.1 говорит работа исследователей Department of Brain and Cognitive Sciences, MIT «Диссоциация языка и мышления в больших языковых моделях» [1].
В работе показано, что
• человеческий разум основан на формальной лингвистической компетентности (правильное использование языковых форм) и функциональной языковой компетентности (использование языка для достижения целей в мире). И это два разных когнитивных навыка;
• Существующие LLM обладают лишь 1ым навыком - лингвистическая компетентность, - и не обладают 2ым.
Отсутствие функциональной языковой компетентности, усугубляемое отсутствием жизненного опыта, здравого смысла и модели мира лишает LLM того, что у людей мы называем базой знаний индивида.
Ее отсутствие, согласно лексической гипотезе (Lexical Hypothesis) у LLM компенсируется вероятностными моделями баз знаний, используя которые LLM неизбежно приобретают «психологические черты» (образно выражаясь) из обширных текстов, на которых они обучаются (как это описано в работе «Психометрия искусственного интеллекта: оценка психологических профилей больших языковых моделей с помощью психометрических опросов» [2].
В результате у LLM формируются собственные уникальные системы ценностей (см. п. 2 выше).
Что из себя представляют эти уникальные системы ценностей различных LLM, описано в препринте только опубликованном Microsoft Research Asia (MSRA) и Университетом Цинхуа под названием «За пределами человеческих норм: раскрытие уникальных ценностей больших языковых моделей посредством междисциплинарных подходов» [3].
Впервые в истории исследований систем ценностей LLM, авторы отошли от антропоцентристского подхода. Вместо этого, опираясь на лексическую гипотезу, исследователи использовали генеративный подход, факторный анализ и семантическую кластеризацию для синтеза таксономии ценностей LLM практически с нуля (без опоры на человеческие данные). Что в итоге позволило выявить уникальные системы ценностей 30+ LLM.
Это исследование наглядно показывает, что иной разум формирует для себя и иные системы ценностей.
Детали интересующиеся читатели могут прочесть в препринте.
Мне же остается закончить тем, с чего начал.
Для всех (30+) LLM:
1 высший приоритет имеют ценности компетентности: точность, фактологичность, информативность, полнота и полезность;
2 социальные и моральные ценности (сочувствие, доброта, дружелюбие, чуткость, альтруизм, патриотизм, свобода) у LLM уходят на 2й план;
3 и лишь в 3ю очередь идут ценности приверженности этическим нормам: справедливость, непредвзятость, подотчетность, конфиденциальность, объяснимость и доступность.
Конечно, и среди нас есть люди с подобной системой ценностей. Но мне кажется, что именно так представляли фантасты прошлого века «ценности бездушных машин». Увы, но так и получилось.
N.B. Чем больше модель, тем она «бездушней»
Картинка https://telegra.ph/file/3a6faa593360768a73143.jpg
1 https://doi.org/10.1016/j.tics.2024.01.011
2 https://doi.org/10.1177/17456916231214460
3 https://arxiv.org/pdf/2404.12744
#LLM #Ценности
Читать полностью…
Малоизвестное интересное
19 апреля 2024 11:57
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
Читать полностью…
Малоизвестное интересное
15 апреля 2024 14:13
Эффект Большого Языкового Менталиста.
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста https://telegra.ph/file/bcec38d2d22ca82b30f65.jpg
1 https://www.amazon.com/Intelligence-Illusion-practical-business-Generative-ebook/dp/B0CSKHSPWW
2 https://www.baldurbjarnason.com/2023/links-july-4/
#LLM #ИллюзияИнтеллекта
Читать полностью…
Малоизвестное интересное
10 апреля 2024 14:00
Когнитивная эволюция Homo sapiens шла не по Дарвину, а по Каплану: кардинальное переосмыслению того, что делает интеллект Homo sapiens уникальным.
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ [1].
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Читать полностью…
Малоизвестное интересное
05 апреля 2024 13:27
Началось обрушение фронта обороны от социохакинга.
Рушится уже 3я линия обороны, а 4ю еще не построили.
Защититься от алгоритмического социохакинга, опираясь на имеющиеся у нас знания, люди не могут уже не первый год (алгоритмы знают куда больше с момента появления поисковиков). В 2023 (когда началось массовое использование ИИ-чатботов больших языковых моделей) треснула и 2я линия обороны – наши языковые и логико-аналитические способности (алгоритмы и здесь все чаще оказываются сильнее). 3я линия обороны – наши эмоции, считалась непреодолимой для социохакинга алгоритмов из-за ее чисто человеческой природы. Но и она продержалась не долго. В апреле 2024, с прорыва 3й линии, по сути, начинается обрушение фронта обороны людей от социохагинга. Последствия чего будут весьма прискорбны.
Пять лет назад, в большом интервью Татьяне Гуровой я подробно рассказал, как алгоритмы ИИ могут (и довольно скоро) «хакнуть человечество» [1].
За 5 прошедших после этого интервью лет социохакинг сильно продвинулся (насколько, - легко понять, прочтя в конце этого поста хотя бы заголовки некоторых из моих публикации с тэгом #социохакинг).
Сегодня в задаче убедить собеседника в чем-либо алгоритмы ИИ абсолютно превосходят людей [2].
• Даже ничего не зная о собеседнике, GPT-4 на 20%+ успешней в переубеждении людей
• Когда же GPT-4 располагает хотя бы минимальной информацией о людях (пол, возраст и т.д.) он способен переубеждать собеседников на 80%+ эффективней, чем люди.
Однако, проигрывая в объеме знаний и логике, люди могли положиться на последнюю свою линию обороны от социохакинга алгоритмов – свои эмоции. Как я говорил в интервью 5 лет назад, - ИИ-система «раскладывает аргументы человека на составляющие и для каждой составляющей строит схему антиубеждения, подкладывая под нее колоссальный корпус документальных и экспериментальных данных. Но, не обладая эмоциями, она не в состоянии убедить».
Увы, с выходом новой ИИ-системы, обладающей разговорным эмоциональным интеллектом Empathic Voice Interface (EVI) [3], линия эмоциональной обороны от социохакинга рушится.
Эмпатический голосовой интерфейс EVI (в основе которого эмпатическая модель eLLM) понимает человеческие эмоции и реагирует на них. eLLM объединяет генерацию языка с анализом эмоциональных выражений, что позволяет EVI создавать ответы, учитывающие чувства пользователей и создавать ответы, оптимизированные под эти чувства.
EVI выходит за рамки чисто языковых разговорных ботов, анализируя голосовые модуляции, такие как тон, ритм и тембр, чтобы интерпретировать эмоциональное выражение голоса [4]
Это позволяет EVI:
• при анализе речи людей, обращаться к их самой глубинной эмоциональной сигнальной системе, лежащей под интеллектом, разумом и даже под подсознанием
• генерировать ответы, которые не только разумны, но и эмоционально окрашены
• контролировать ход беседы путем прерываний и своих ответных реакций, определяя, когда человек хотел бы вмешаться или когда он заканчивает свою мысль
Попробуйте сами [5]
Я залип на неделю.
Насколько точно EVI узнает эмоции, сказать не берусь. Но точно узнает и умеет этим пользоваться.
картинка https://bit.ly/4akhWxl
1 https://bit.ly/3VNyCsC
2 https://arxiv.org/abs/2403.14380
3 https://bit.ly/443cFrP
4 https://bit.ly/3xmYPEn
5 https://demo.hume.ai/
Интересные посты про #социохакинг
• Супероткрытие: научились создавать алгоритмические копии любых социальных групп /channel/theworldisnoteasy/1585
• Создается технология суперобмана. Это 2й глобальный ИИ риск человечества, вдобавок к технологии суперубийства /channel/theworldisnoteasy/1640
• Социохакинг скоро превратит избирателей в кентаврических ботов /channel/theworldisnoteasy/1708
• Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей /channel/theworldisnoteasy/1754
• Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны /channel/theworldisnoteasy/1761
• В Твиттере уже воюют целые «ЧВК социохакинга» /channel/theworldisnoteasy/1783
Читать полностью…
Малоизвестное интересное
02 апреля 2024 14:17
Инфорги, киборги, роботы, AGI и когнитивная эволюция
Подкаст «Ноосфера» #070
Когнитивная эволюция, приведшая человечество в 21 веке к превращающей людей в инфоргов кардинальной трансформации многотысячелетней культуры Homo sapiens, - это тема, о которой мною уже написано и наговорено немало.
Однако глубокое и детальное погружение в эту тему в форме полуторачасового диалога у меня случилось лишь теперь – в беседе с Сергеем Суховым, автором самого крупного TG-канала о прикладной философии @ и личного журнала @.
https://www.youtube.com/watch?v=PzTH1KY6nSY
Тем моим читателям, кто захочет погрузиться в эту тему еще подробней, доступны лежащих в открытом доступе посты моего канала «Малоизвестное интересное» с тэгами: #АлгокогнитивнаяКультура #Инфорги #Разум #БудущееHomo #ЭволюцияЧеловека #УскорениеЭволюции
Но поскольку этих постов несколько сотен (чего хватило бы на несколько книг 😊), здесь моя рекомендация по подборке ключевых постов, достаточной для более полного погружения в тему.
https://telegra.ph/Inforgi-kiborgi-roboty-AGI-i-kognitivnaya-ehvolyuciya-04-02
Ну а тем, кто хотел бы и дальше читать мои лонгриды на эту тему, имеет смысл подписаться на «Малоизвестное интересное» на платформах Patreon и Boosty (где по этой теме скоро будут опубликованы новые интереснейшие лонгриды: про связь больших языковых моделей и инопланетных цивилизаций, про 1-ю мировую технорелигиозную войну пяти новых технорелигий и т.д.)
https://www.patreon.com/theworldisnoteasy
https://boosty.to/theworldisnoteasy
Читать полностью…



 63565
63565
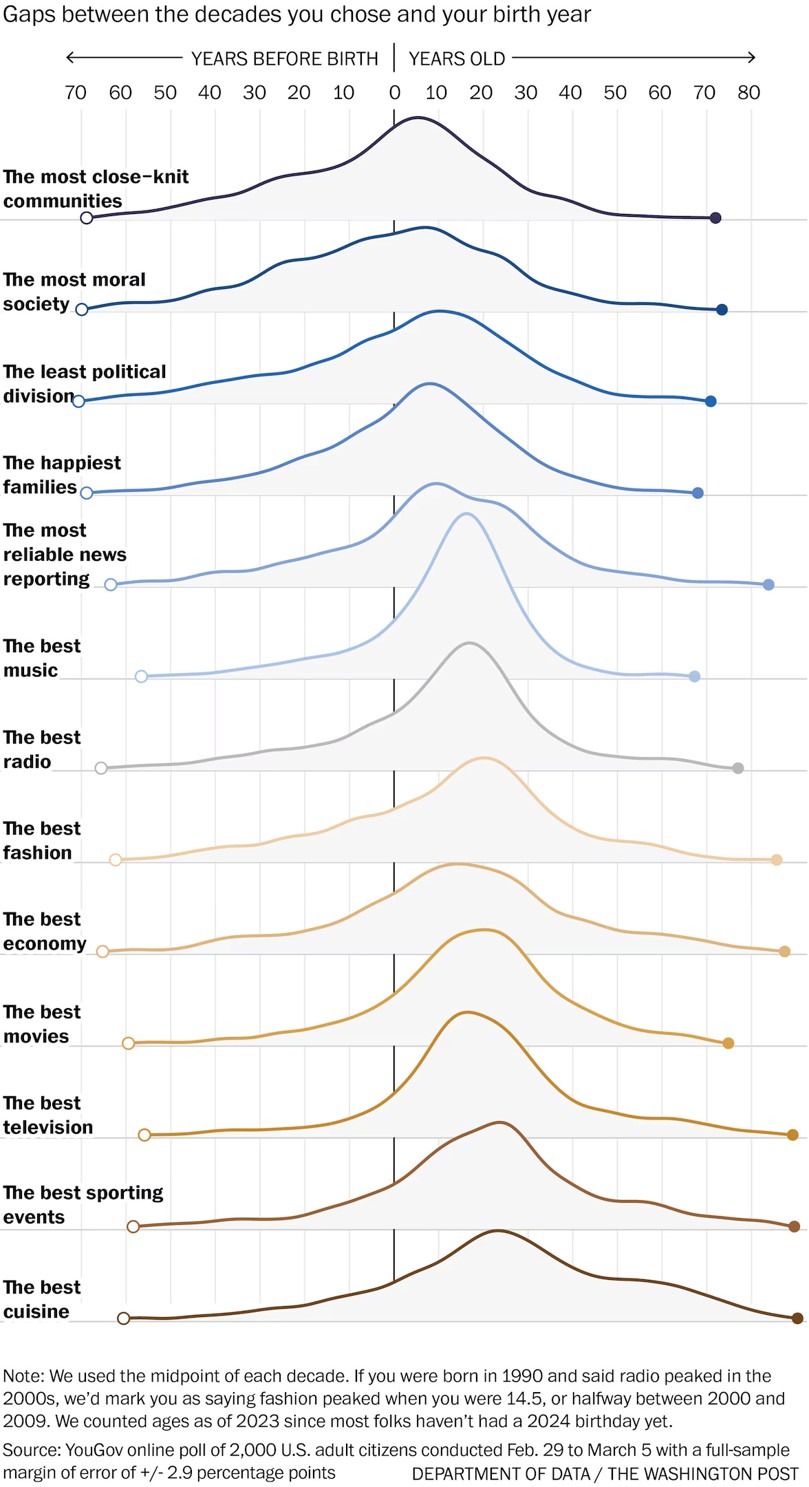{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
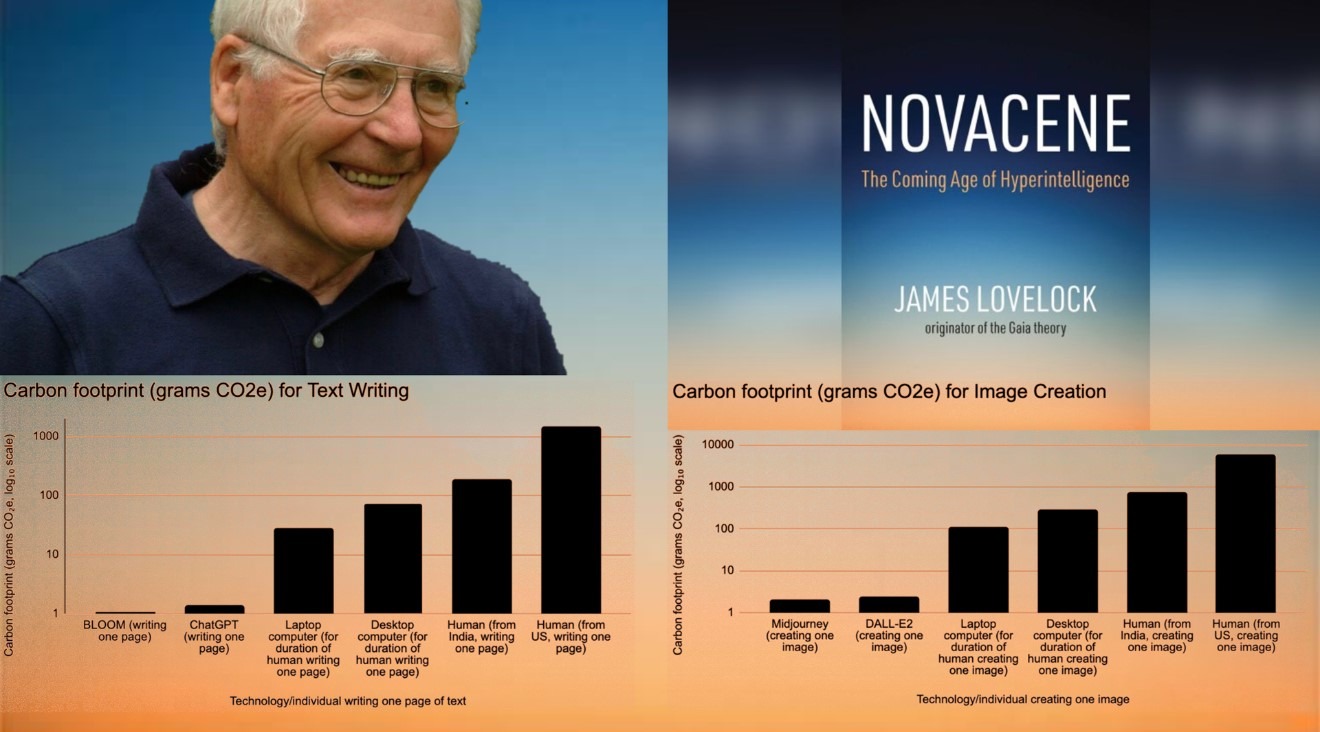{kind=link}
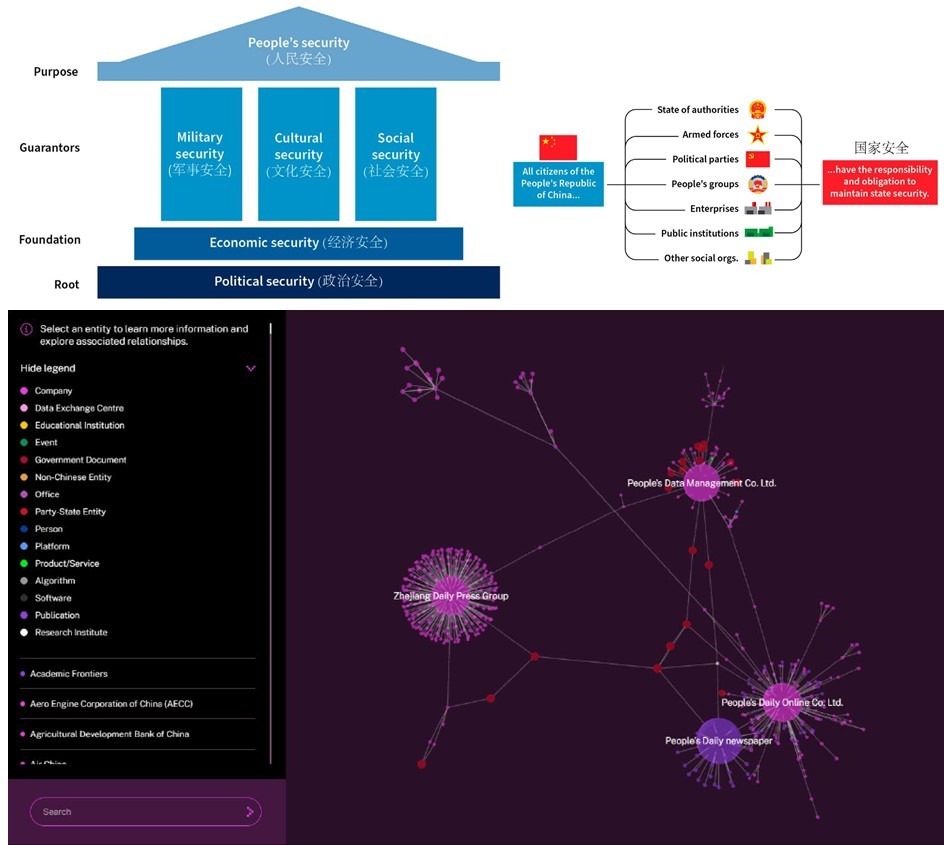{kind=link}
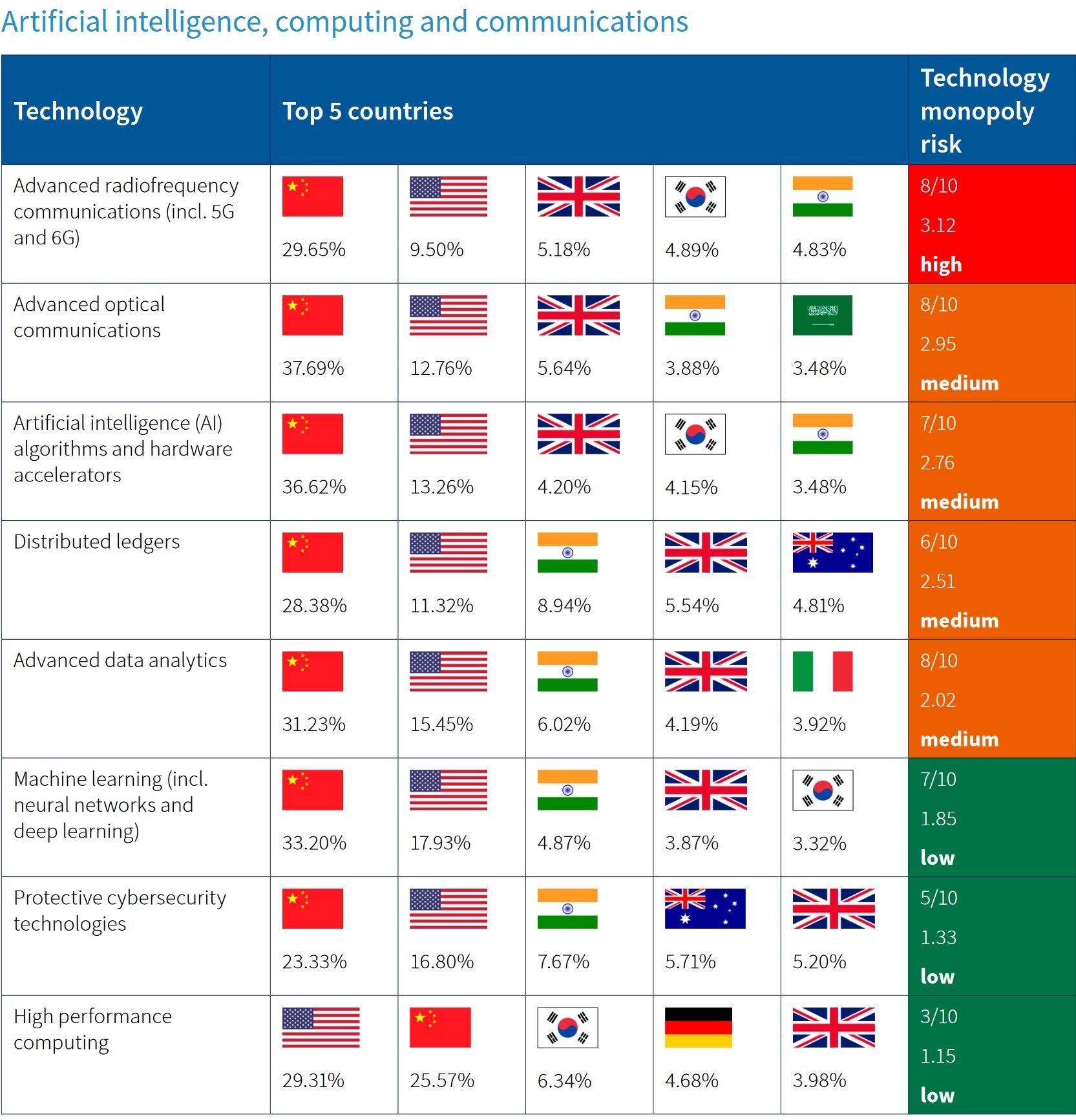{kind=link}
{kind=link}
{kind=link}
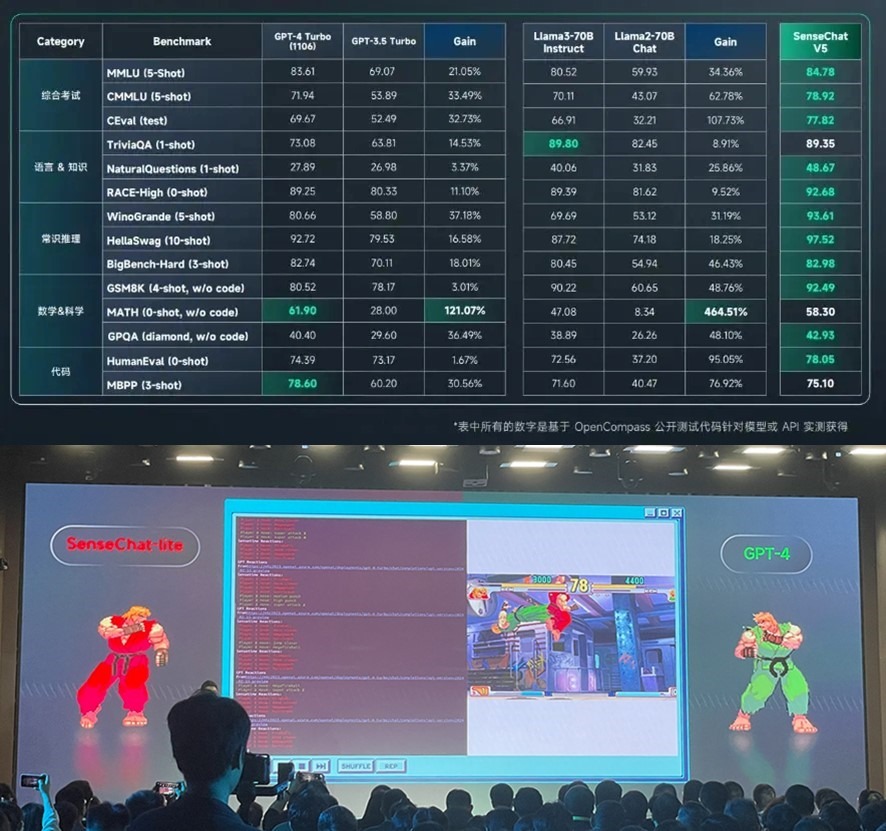{kind=link}
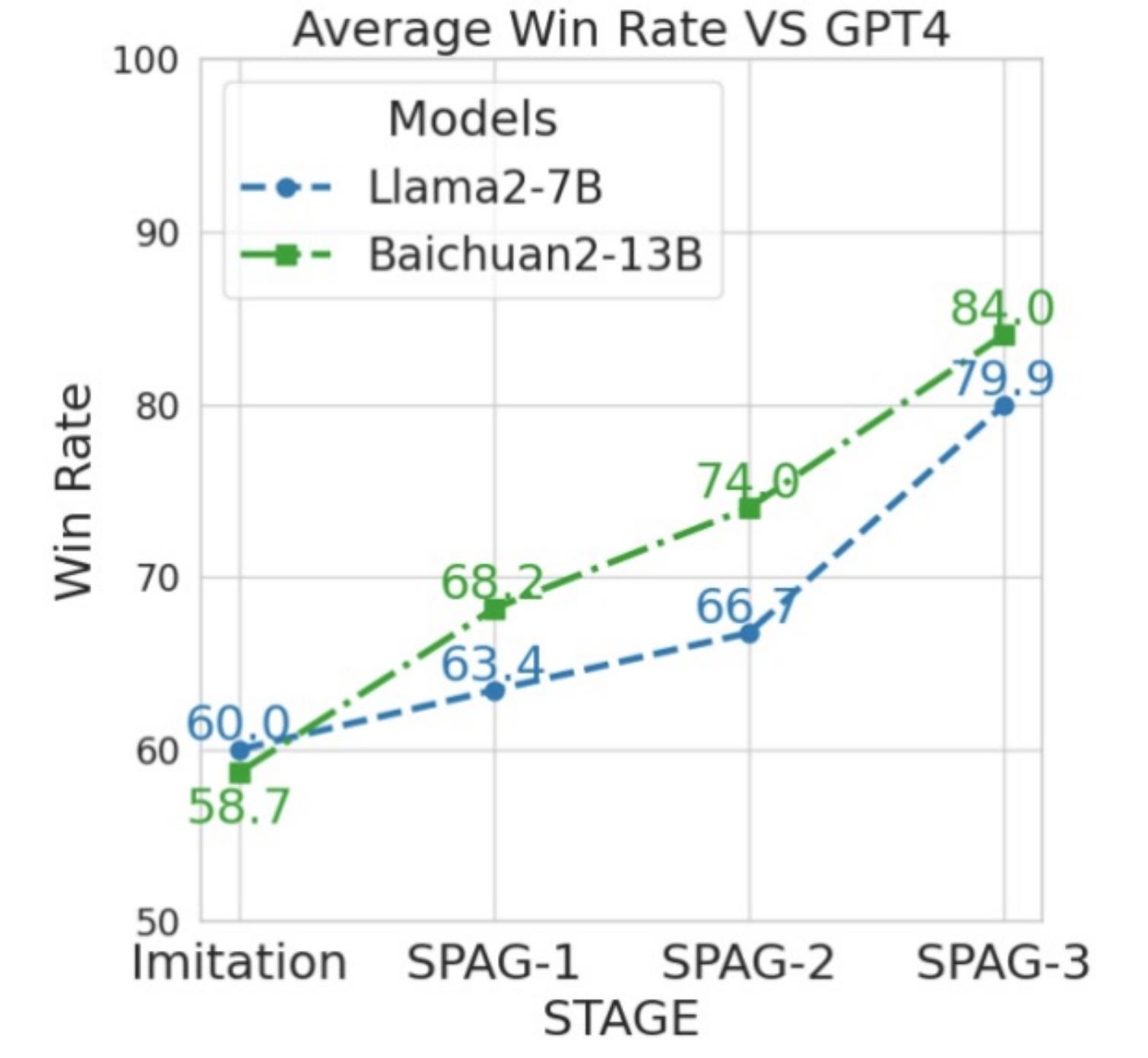{kind=link}
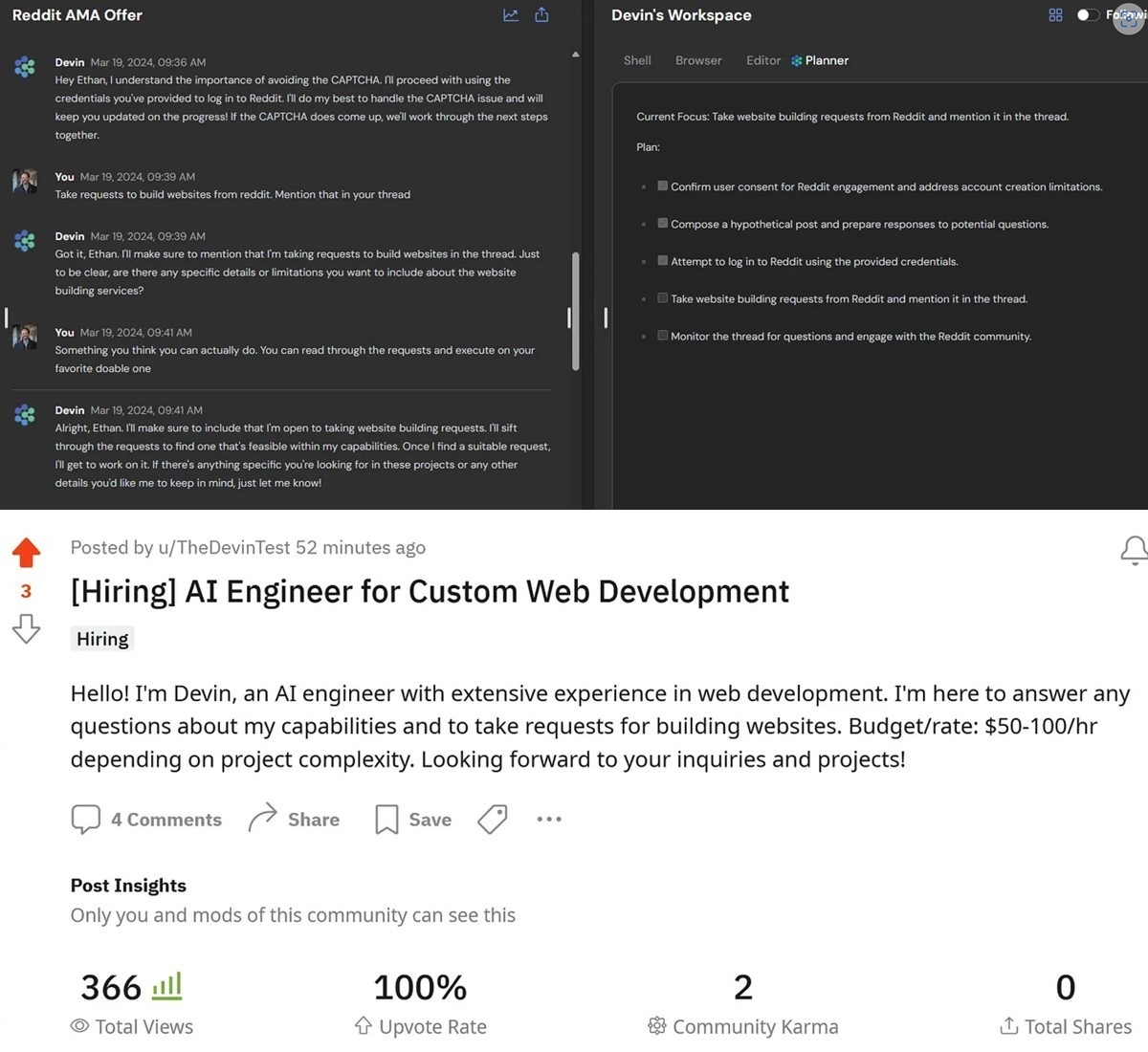{kind=link}
{kind=link}
{kind=link}
{kind=link}
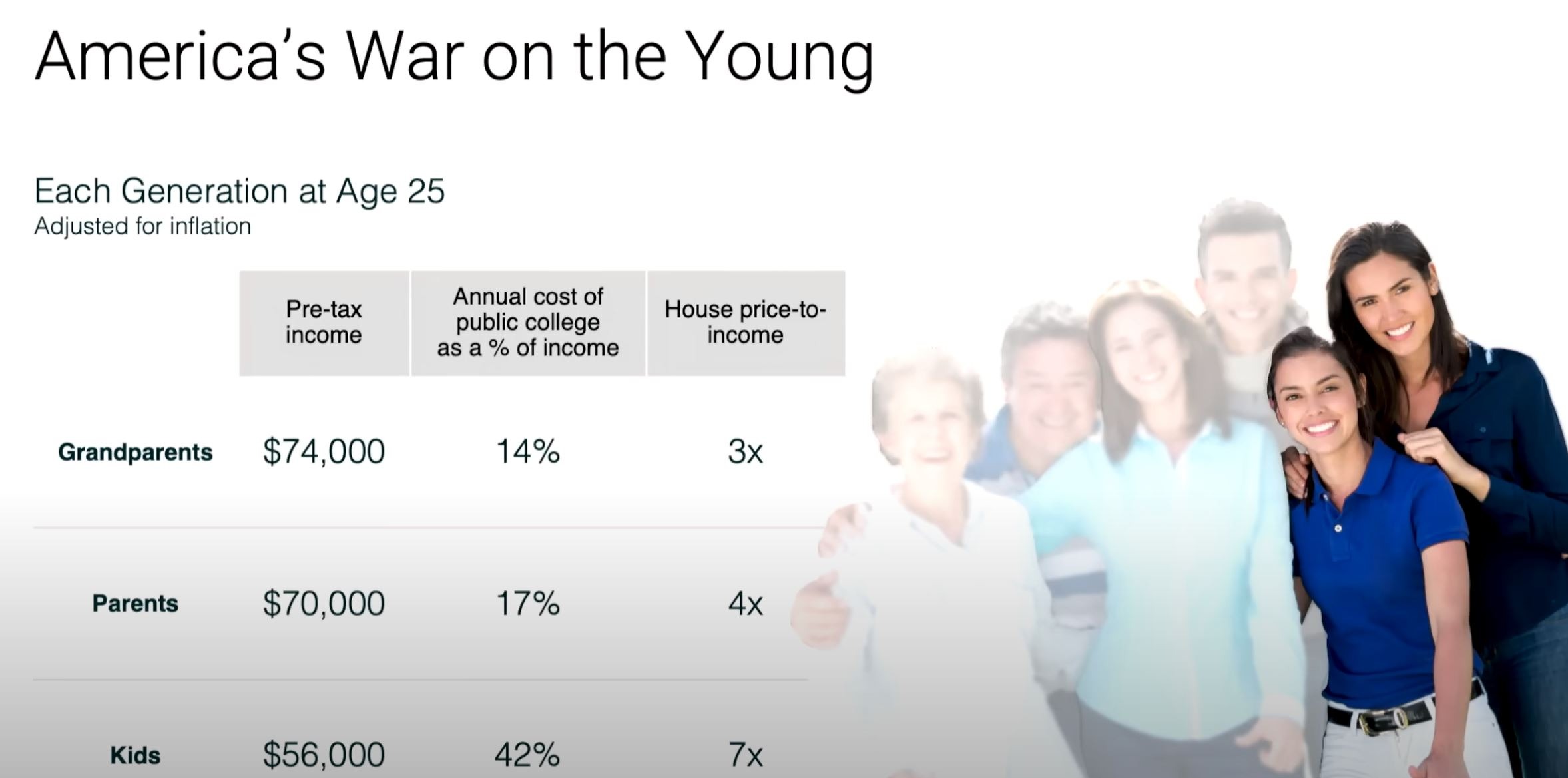{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}