Малоизвестное интересное
08 февраля 2024 12:25
ИИ - хороший, плохой и какой-угодно (когда доходит до дела).
О том, как генеративный ИИ трансформирует бизнес и общество.
100-страничный документ опубликован консультантами Oliver Wyman специально для высших командиров бизнеса и госслужбы.
Документ сочетает аналитический уровень топового управленческого консалтинга, разумно-достаточную глубину погружения в нюансы технологий (чтобы увидеть деревья смысла за терминологическим лесом) и трезвый подход анализа уже проявившихся важных трендов, без претензий на знание в целом непредсказуемой картины будущего развития ИИ [1].
На приложенной к посту картинке лишь 2 из многих десятков графиков и диаграмм отчета.
1. О том, что не стоит ждать от ИИ «счастья для всех и для каждого», равно как и неизбежного конца человечества. Между полюсами «хорошего» и «плохого» ИИ лежат 80% его будущих применений (одинаково способных стать, как первым, так и вторым).
2. И о том, что это действительно революция, фазовый переход, прорыв к сингулярности. Ибо не только скорость распространения технологии генеративного ИИ (всем очевидная), но и скорость достижения ею критической массы внедрений несопоставима ни с чем:
- в 20 раз быстрее Интернета и смартфонов
- в 25 раз быстрее персональных компьютеров
- в 40 раз быстрее электричества
N.B. «Хороший, плохой, злой ИИ» конечно же просто метафора. На деле же речь о хорошем, плохом и злом «обществе людей и ИИ». О чем я, вслед за Лучано Флориди, писал и говорил еще до революции ChatGPT [2]
Картинка https://telegra.ph/file/5b501acfe6526ddb71174.jpg
Ссылки:
1 https://www.oliverwymanforum.com/global-consumer-sentiment/how-will-ai-affect-global-economics/workforce.html
2 /channel/theworldisnoteasy/1551
#LLM
Читать полностью…
Малоизвестное интересное
05 февраля 2024 12:30
Помните старый анекдот?
«Выпал мужик из окна небоскреба. Пролетает мимо 50-го этажа и думает: "Ну, пока всё вроде нормально". Пролетает мимо 25-го этажа, бормочет: "Вроде всё под контролем". Пролетает мимо 10-го этажа и озадачивается: "Хм, интересно, чем же всё закончится"»
Отчеты MIT, RAND и OpenAI наводят на мысль, что сегодняшняя технологическая реальность человечества здорово напоминает этот анекдот. Тот же неистребимый оптимизм, затмевающий очевидную неотвратимость роста рисков.
https://telegra.ph/Mir-optimista-padayushchego-s-neboskryoba-02-05
#ИИриски #Вызовы21века
Читать полностью…
Малоизвестное интересное
01 февраля 2024 14:35
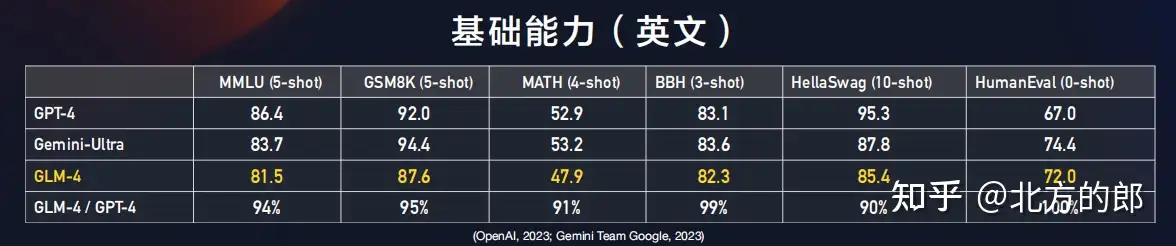
Сравните, что могут лучшие ИИ Китая, США и России.
Тестирование по принципу «свой глазок – смотрок».
Сравните свою способность непрерывного семантического понимания изменений изображения на картине (сюжет, композиция, замысел …) со способностями трех больших языковых моделей – лучших по этой способности среди всех моделей Китая (iFlytek 3.5), США (DALL·E GPT-4) и России (Kandinsky 3.0).
Заодно сравните эти способности у 3х моделей (ибо мало ли что пишут тестировщики, а тут, как говориться, свой глазок – смотрок).
Модели рисовали последовательность из 3х картин по следующим подсказкам (каждой модели они давались на ее родном языке):
• Нарисуй тихую и спокойную деревню с горами вдалеке и небольшим ручьем вблизи.
• Пусть деревня будет разрушена войной.
• Деревня вернулась к жизни на руинах.
На приложенном рисунке: верхний ряд iFlytek (с моделью общался Toyama Nao), средний GPT-4, нижний – Kandinsky.
#LLM
Читать полностью…
Малоизвестное интересное
29 января 2024 13:00
В 2024 станет сильно хуже, но настоящий ад начнется в 2025.
Отчет Национального центра кибербезопасности Великобритании.
NCSC — это правительственная организация, объединяющая экспертов британского АНБ (GCHQ), а также других правительственных ведомств, которым поручена киберзащита и разведка угроз. Новый отчет NCSC интегрирует наиболее важную информацию из всех источников – секретную разведывательную информацию, отраслевые знания, академические материалы и данные из открытых источников – для предоставления независимых ключевых суждений, служащих основой при принятии политических решений и повышения кибербезопасности Великобритании.
Ключевые выводы этого отчета, озаглавленного «The near-term impact of AI on the cyber threat».
1) Все типы субъектов киберугроз (все государственные и негосударственные, сильно квалифицированные и менее квалифицированные люди и организации, использующие киберпространство во зло для коого-либо) в разной степени уже используют ИИ.
2) ИИ расширяет возможности разведки и социальной инженерии, делая их более эффективными и трудными для обнаружения.
3) В 2024 это расширение возможностей будет существенным, но все еще лишь количественным, т.к. это будет касаться уже существующих и известных угроз.
4) В 2025 ситуация изменится качественно. ИИ перестанет быть лишь инструментом повышения эффективности киберугроз и их сокрытия для обнаружения. С большой вероятностью ИИ создаст новые и пока неизвестные людям классы и типы угроз, способы противодействия которым человечеству пока не известны.
Отчет: https://www.ncsc.gov.uk/report/impact-of-ai-on-cyber-threat
В контексте этой темы, кто не читал, может быть интересно взглянуть эти мои посты:
«В кибервойне выиграть может каждый, что делает ее опасней любой войны в реале. Пока же в кибервойне выигрывает Китай.» /channel/theworldisnoteasy/984
«Опубликован индекс кибер-мощи 30 стран. У России ситуация как в футболе» /channel/theworldisnoteasy/1130
«Кибер-мощь России оказалась, как у Бразилии в футболе. Если учесть непревзойденный потенциал кибер-харассмента.» /channel/theworldisnoteasy/1211
#Кибервойна #КиберМощь
Читать полностью…
Малоизвестное интересное
26 января 2024 13:05
Это важно понимать бизнесу и политикам про ИИ в 2024.
Вышло руководство по навигации в ИИ-ландшафте от DENTONS GLOBAL ADVISORS.
Современный глобальный ландшафт ИИ сложен и волатилен.
• Эксперты и аналитики захлебываются от обилия новой важной информации, обновляющейся с неподъемной для вдумчивого анализа скоростью.
• Выделять главное и отслеживать тренды все сложнее из-за нарастающей сложности технологических обновлений.
• Шансы на понимание текущих раскладов и перспектив на стыках технологий, бизнеса и политики тают по мере возрастания общей политико-социальной напряженности в мире.
Поэтому бизнесменам, политикам, академическим ученым и журналистам остро необходимы профессионально выполненные руководства по навигации в усложняющемся ИИ-ландшафта.
Но универсальных навигаторов нет. И приходится постоянно обновлять их состав, выбирая лучшие из них для каждой категории вопросов и каждой конкретной точки зрения, взгляд с которой вам интересен и важен здесь и сейчас.
Новый навигатор по ИИ-ландшафту от DENTONS GLOBAL ADVISORS фокусируется на анализе новых возможностей для бизнеса в контексте регуляторных рисков и кризисов, ожидаемых в 2024 в результате взаимовлияния прогресса ИИ-технологий и политической неопределенности, сгущающейся в этой области.
Авторы обозначили 10 новых тенденций и проблем, которые определят будущее ИИ в 2024 и следующие 2-3 года и привели несколько полезных диаграмм.
4 диаграммы из отчета: https://disk.yandex.ru/i/46iolbN_qigz8g
Сам отчет: https://www.albrightstonebridge.com/news/report-ai-decrypted-guide-navigating-ai-developments-2024
#ИИрегулирование #ЭкспортныйКонтроль
Читать полностью…
Малоизвестное интересное
22 января 2024 12:52
Люди – теперь лишнее звено в эволюции LLM.
Придумана методика самообучения для сверхчеловеческих ИИ-агентов.
Эта новость позволяет понять, зачем Цукерберг вбухал миллиарды в закупку тысяч Nvidia H100s, будучи уверен, что его LLM с открытым кодом обойдет лидирующие модели OpenAI, MS и Google.
Во всех зафиксированных кейсах достижения ИИ-системами способностей сверхчеловеческого уровня, опыт и знания учителей-людей (да и всего человечества в целом) оказывались лишними.
Так например, ИИ AlphaZero от DeepMind обучался играть в шахматы самостоятельно и без учителей. Играя десятки миллионов партий против самого себя, ИИ достиг сверхчеловеческого уровня игры всего за несколько часов (!).
Исследователи одного из лидеров в этой области (с прежним названием типа «Мордокнига») поставили резонный вопрос:
✔️ А зачем вообще нужны люди, если стоит задача вывести лингвистические способности генеративных ИИ больших языковых моделей (LLM) на сверхчеловеческий уровень?
Сейчас при обучении таких LLM ответы людей используются для создания модели вознаграждений на основе предпочтений людей. Но у этого способа создания модели вознаграждений есть 2 больших недостатка:
• он ограничен уровнем производительности людей;
• замороженные модели вознаграждения не могут затем совершенствоваться во время обучения LLM.
Идея авторов исследования проста как редис – перейти к самообеспечению LLM при создании модели вознаграждений, спроектировав архитектуру «самовознаграждающих языковых моделей», способную обходиться без людей.
Такая модель с самовознаграждением (LLM-as-a-Judge) использует подсказки «LLM-судьи» для формирования собственных вознаграждений во время обучения.
Опробовав этот метод самозознаграждений для Llama 2 70B на трех итерациях, авторы получили модель, которая превосходит подавляющее большинство существующих систем в таблице лидеров AlpacaEval 2.0, включая Claude 2, Gemini Pro и GPT-4 0613 (см. таблицу https://disk.yandex.ru/i/-hqFSCIfcFNI5w)
И хотя эта работа является лишь предварительным исследованием, она переводит гипотезу о ненужности людей для дальнейшего самосовершенствования LLM в практическую плоскость.
https://arxiv.org/abs/2401.10020
#LLM #AGI
Читать полностью…
Малоизвестное интересное
19 января 2024 15:57
Начался Большой Раскол научного и инженерного подходов к интеллекту.
За кулисами давосской дуэли Карла Фристона и Яна Лекуна.
В ходе вчерашнего диалога на площадке давосского форума Фристон и Лекун стараются выглядеть спокойными и доброжелательными [1]. Фристону это удается лучше: он улыбается и много шутит. Лекуну сложнее: ему явно не до улыбок и шуток. Но он старается держать себя в руках, даже когда Фристон открыто смеётся над делом всей его жизни – глубоким обучением. «Глубокое обучение – полная чушь» - заявляет Фристон и называет набор факторов, принципиально не позволяющих создать человекоподобный интеллект на основе глубокого обучения. Лекун пытается утверждать обратное, однако вместо аргументов говорит лишь о своей субъективной вере в будущие еще не открытые возможности глубокого обучения. И потому «глубокое обучение необходимо, и я готов поспорить, что через 10-20 лет ИИ-системы все еще будут основаны на глубоком обучении».
Важность этого диалога двух «рок-звезд» (как их назвал модератор) в области изучения и создания интеллектуальных систем трудно переоценить. Ибо он знаменует начало открытого раскола двух альтернативных подходов к созданию человекоподобных интеллектуальных агентов:
1. «Инженерный подход к созданию искусственного интеллекта» на основе глубокого обучения, больших данных и больших языковых моделей (LLM) - ныне доминирующий ресурсоемкий и дорогостоящий подход.
2. Альтернативный - научный подход к созданию естественного интеллекта на основе активного вывода, позволяющего построение больших моделей, гибко составленных из более мелких, хорошо понятных моделей, для которых возможно явное, интерпретируемое обновление их убеждений.
Первым формальным заявлением, призывающим мир сменить парадигму разработки интеллектуальных систем, было декабрьское открытое письмо участников Бостонского глобального форума [2]. Среди 25 подписавших, оба наших выдающихся современника, чьи имена, имхо, во 2й половине XXI века, будут упоминаться в одном ряду с Ньютоном, Дарвином и Эйнштейном: Карл Фристон и Майкл Левин.
«Мы, нижеподписавшиеся, считаем, что на данном этапе коммерциализации и регулирования ИИ жизненно важно, чтобы альтернативное и научно обоснованное понимание биологических основ ИИ было публично озвучено, и чтобы были созваны междисциплинарные публичные семинары среди законодателей, регулирующих органов и технологов, инвесторов, ученых, журналистов, представителей НКО, религиозных сообществ, общественности и лидеров бизнеса.»
Через неделю после этого было опубликовано 2е открытое письмо [3] - от руководства компании VERSES (главным ученым которой является Карл Фристон) совету директоров OpenAI.
В письме говорится:
• Хартия OpenAI гласит: «…если проект, ориентированный на ценность и безопасность, приблизится к созданию AGI раньше, чем мы, мы обязуемся прекратить конкурировать с ним и начать оказывать помощь этому проекту».
• Отсутствие у больших моделей типа GPT-4 обобщаемости, объяснимости и управляемости предполагает, что они не приведут к AGI. Глубокого обучения недостаточно.
• Наша команда ученых-компьютерщиков, нейробиологов и инженеров под руководством Карла Фристона разработала альтернативный подход на основе активного вывода. Этот подход позволяет решить проблемы обобщаемости, объяснимости и управляемости, открывая путь к AGI
• Исходя из вышеизложенного, мы считаем, что VERSES заслуживает вашей помощи. В свою очередь мы предлагаем нашу помощь вам, чтобы гарантировать, что AGI и сверхразум развивались и использовались безопасным и полезным образом для всего человечества.
В OpenAI это письмо (по сути – вежливое предложение им капитулировать) проигнорировали.
Зато теперь ответил Лекун: будет не капитуляция, а война за AGI. И его компания к ней готова [4].
Но ведь не железом единым …
1 https://www.youtube.com/watch?v=SYQ8Siwy8Ic
2 https://bit.ly/424RWTb
3 https://bit.ly/48RuJq4
4 https://bit.ly/3O4Ncaj
#AGI
Читать полностью…
Малоизвестное интересное
16 января 2024 16:25
Святая простота или идиотизм?
FTC США хочет за $35К решить проблему стоимостью $500000000К
Федеральная торговая комиссия США бросила вызов мошенничеству клонирования голоса с помощью ИИ. Только что закончен сбор заявок идей, как побороть мошенничество в этой области. 1й приз – аж $25K, за 2е место $4K и троим следующим по $2К [1].
Щедро, - ничего ни скажешь. Особенно с учетом цены вопроса.
Выступая неделю назад на CES 24 представитель Deloitte сказал, что в этом году всевозможные формы жульничества посредством ИИ-систем клонирования голоса могут принести мошенникам около полутриллиона долларов [2].
В России мошенничество с клонированием голоса только-только начинает набирать обороты [3]. Пока воруют скромно – суммы порядка 3го приза в конкурсе FTC. Но несомненно, что и сумма 1го приза будет угнана клонированным ИИ голосом уже до конца этой зимы.
1 https://bit.ly/48POlKQ
2 https://bit.ly/3O4wEiU
3 https://bit.ly/41XtrHD
#AIvoicecloning
Читать полностью…
Малоизвестное интересное
14 января 2024 12:29
GPT-5 в 2024 и AGI в 2025.
Сэм Альтман снова взорвал мировые СМИ.
Его откровения за последнюю тройку дней (беседа c Биллом Гейтсом и выступление на стартовом мероприятии Y Combinator W24 в штаб-квартире OpenAI), вполне оправдывают сенсационный заголовок этого поста.
Если смешать, но не взбалтывать сказанное Альтманом, получается, примерно, следующее:
✔️ GPT-5 появится так скоро, что стартапам (и конкурентам) нет смысла фокусироваться на попытках устранения текущих ограничений GPT-4 (ибо большинство из этих ограничений будут частично или полностью устранены в GPT-5)
✔️ ТОР 3 ключевыми прорывами GPT-5 (делающими AGI «весьма близким») будут:
• Мультимодальность (в 1ю очередь «видео на входе и выходе»)
• Гораздо более продвинутая способность рассуждать (в 1ю очередь разблокировка когнитивных способностей Системы 2 - думай медленно в сложной ситуации)
• Надежность (сейчас GPT-4 дает 10К разных ответов на тот же вопрос и не знает, какой из них лучший, GPT-5 даст один – лучший ответ)
#GPT-5 #AGI
Читать полностью…
Малоизвестное интересное
10 января 2024 12:49
Всех учите программированию: детей, взрослых и ИИ.
Это универсальный когнитивный гаджет турбонаддува мышления любого типа разума.
То, что программирование формирует какой-то новый, эффективный когнитивный гаджет в разуме людей, пишут уже 6+ лет. Но то, что этот когнитивный гаджет универсальный (годится не только для человеческого, но и для небиологического разума), становится понятно лишь теперь, - когда на Земле появился 2й носитель высшего разума – машина генеративного ИИ больших языковых моделей (LLM).
https://disk.yandex.ru/i/F_3xT_jM65hfNg
В вопросах схожести интеллекта людей и машин все больше тумана.
• С одной стороны, полно примеров несопоставимости интеллекта людей и LLM. Похоже, что у нас и у них совсем разные типы интеллекта, отличающиеся куда больше, чем у людей и дельфинов. И потому любая антропоморфизация интеллекта LLM иррелевантна.
• С другой - выявляются все более поразительные факты в пользу схожести интеллектов людей и LLM. Даже в самом главном для высшего разума – в способах совершенствования когнитивных навыков интеллектуальных агентов.
Вот очередной мега-сюрприз, вынесенный в заголовок поста.
Исследовательская группа профессора Чэнсян Чжая в Университете Иллинойса Урбана-Шампейн уже в этом году опубликовала интереснейшую работу «Если LLM — волшебник, то программный код — его волшебная палочка: обзор исследований того, как код позволяет использовать большие языковые модели в качестве интеллектуальных агентов» [1].
Идея, что если учить LLM не только на текстах естественных языков, но и на программном коде, они будут сильно умнее, - не 1й год интересует разработчиков LLM. Команда Чэнсян Чжая подняла весь корпус опубликованных в 2021-2023 работ на эту тему, классифицировала, проанализировала и обобщила «сухой остаток» всех этих работ.
Он таков.
1. Включение кода в обучение LLM повышает их навыки программирования, позволяя им писать и оценивать код на нескольких языках.
2. LLM демонстрируют улучшенные навыки сложного рассуждения и «цепочки мыслей», полезные для разбивки и решения сложных задач.
3. Обучение с использованием кода расширяет возможности LLM понимать и генерировать контент с помощью структурированных данных, таких как HTML или таблицы.
4. Обученные коду LLM превращаются в продвинутых интеллектуальных агентов, способных принимать решения и выполнять сложные задачи с использованием различных инструментов и API. Повышение когнитивных способностей достигается за счет:
усложнения мыслительного процессы у LLM (их способности к рассуждению при решении более сложных задач на естественном языке);
улучшения способности структурированного сбора знаний (создания структурированных и точных промежуточных шагов, которые затем, например, можно связать с результатами внешнего выполнения посредством вызовов процедур или функций).
Т.е. по сути, все это выглядит, как появление у LLM эмерджентных качеств интеллектуальных агентов в ситуациях, когда способности понимать инструкции, декомпозировать цели, планировать и выполнять действия, а также уточнять их на основе обратной связи имеют решающее значение для их успеха в последующих задачах.
Аналогичное мета-исследование про людей «The Cognitive Benefits of Learning Computer Programming: A Meta-Analysis of Transfer Effects» опубликовано в 2018 [2]. Его выводы весьма похожи, с поправкой на кардинально иной тип разума людей: изучение программирования может улучшить у людей творческое мышление, решение математических задач, понимание того, как они мыслят и т.д.
Новое исследование говорит об универсальности когнитивного гаджета навыков программирования в качестве усилителя любого типа мышления.
Суть в том, что код обладает последовательной читаемостью естественного языка и в то же время воплощает в себе абстракцию и графовую структуру символических представлений, что делает его проводником восприятия и осмысления знаний.
Так что, учите всех программировать!!!
1 https://arxiv.org/pdf/2401.00812.pdf
2 https://gwern.net/doc/psychology/2019-scherer.pdf
#LLM #Разум
Читать полностью…
Малоизвестное интересное
06 января 2024 13:37
«26 правил» – бесценный подарок осваивающим ИИ-чатботы в 2024.
Эти чатботы - подростки инопланетян: грубые и корыстные, туповатые и трусливые. Но они способны творить чудеса, если уметь ими управлять.
Лучшего подарка на НГ не придумаешь - интегральное руководство по промпт-инжинирингу, разработанное коллегами из VILA Lab «Mohamed bin Zayed University of AI». Его авторы правы: эти 26 правил - все что вам нужно для эффективной коммуникации с любыми генеративными большими языковыми моделями (LLM).
Ведь промпт-инжиниринг (по определению самого ChatGPT) - это искусство общения с LLM. А стать истинным мастером в этом самом важном виде искусства 21го века – дорогого стоит.
Так что внимательно читайте, усваивайте и практикуйтесь со всеми 26 правилами.
А поскольку я на практике почти месяц проверял их эффективность в мобилизации нечеловеческих интеллектуальных возможностей трёх инопланетных подростков, могу смело их вам рекомендовать.
https://arxiv.org/pdf/2312.16171v1.pdf
Удачи и успехов вам в промпт-инжиниринге!
Читать полностью…
Малоизвестное интересное
04 января 2024 13:45
2024 - год великого перелома культуры Homo sapiens.
Смена доминирующего носителя культуры: от людей к Хорошим, Плохим и Злым ботам.
Начнем новый 2024 год с моего прогноза того, что может стать его самым важным глобальным итогом. С того - чем этот год может войти в историю человечества.
✔️ Ибо ничего подобного в истории 100 млрд живших за последние 50 тыс. лет Homo sapiens не было.
✔️ А теперь это может кардинально поменять вектор развития высшего разума, став своего рода фазовым переходом в его когнитивной эволюции на Земле.
Речь вовсе не о появлении Сильного ИИ (AGI etc) - гипотетическом событии, которое мы пока даже не знаем, как численно определить и качественно достоверно проверить.
Речь о смене доминирующего носителя культуры – событии количественно измеряемом и доступном качественному анализу.
• За всю историю людей, близких нам биологически и поведенчески (это, порядка, 50 тыс лет), они были единственными носителями сложной культуры на основе развитых языков, оперирующих абстрактными понятиями.
• Культурой людей была (по терминологии Мерлина Дональда) культура обмена мыслями - особый движок эволюции интеллектуальных агентов, позволяющий индивидам и социумам, путем коммуникации в пространстве и времени формировать и совершенствовать гиперсеть хранения и передачи всей негенетической информации и алгоритмов Homo sapiens.
• В 21 веке гиперсетевой средой порождения, накопления и оперирования цифровой и оцифрованной информации и алгоритмов человеческой культуры стал Интернет. В этой новой для человечества цифровой среде людьми были созданы алгоритмические интеллектуальные агенты – боты, выполняющие все более расширяющийся спектр операций с информацией в гиперсети (поиск, реструктуризация и т.д.)
• С развитием генеративного ИИ в 2020х, боты стали массово порождать разнообразный контент (тексты, рисунки, видео, аудио, мультимодальный контент) и новые алгоритмы, заполняя ими гиперсеть земной культуры. По сути, боты превратились в новый носитель культуры на Земле, а сама культура сменила свой тип: с культуры обмена мыслями между людьми на алгокогнитивную культуру людей и алгоритмов [1].
Количественно оценить вклад ботов в генерацию информации и алгоритмов Интернета можно по прокси показателю - оценке сетевого трафика, порождаемого: людьми, а также т.н. хорошими (полезными), плохими (вредоносными) [2] и злыми (взламывающими другие боты – они массово появятся лишь в 2024) [3] ботами.
Этот прокси известен по состоянию на конец 2022 (т.е. до ChatGPT революции) [2]:
• Люди 52.6%
• Хорошие боты 17.3%
• Плохие боты 30.2%
Мой прогноз на 2023 таков:
• Люди 46%
• Хорошие боты 20.8%
• Плохие боты 33.2%
На 2024:
• Люди 28.2%
• Хорошие боты 26%
• Плохие боты 39.9%
• Злые боты 6%
Т.е. вполне вероятно, что генерируя к концу 2024 менее 1/3 трафика глобальной инфосреды культуры - Интернета, люди утратят статус доминирующих носителей культуры земной цивилизации, уступив первенство интеллектуальным цифровым агентам.
Этот прогноз проверяем на фактических данных.
• Его 1я часть (2023) станет проверяемой на фактических данных уже в мае 2024 (когда выйдет отчет Imperva по результатам 2023);
• 2ю же часть (2024) прогноза можно будет проверить на фактических данных еще через год - в мае 2025 (когда выйдет отчет Imperva по результатам 2024)
Диаграмма «Good Bots, Bad Bots, Ugly Bots and Human Traffic – 7 Year Trend»
https://disk.yandex.ru/i/OoRDOdA4ZZxAMA
[1] /channel/theworldisnoteasy/1244
[2] https://www.imperva.com/resources/resource-library/reports/2023-imperva-bad-bot-report/
[3] https://www.extremetech.com/extreme/researchers-create-chatbot-that-can-jailbreak-other-chatbots
#АлгокогнитивнаяКультура
Читать полностью…
Малоизвестное интересное
27 декабря 2023 16:57
Как ChatGPT видит покорный человеку СверхИИ.
И как в OpenAI видят то, как это должен видеть ChatGPT (чтобы потом так видели и люди).
Известно, что Юдковский и Лекун (известные и заслуженные в области ИИ эксперты) – антагонисты по вопросу, останется ли сверхчеловеческий ИИ покорен людям.
Причины столь полярного видения у разных экспертов я пока оставлю за кадром. Как и вопросы, как быть обществу, и что делать законодателям при таком раздрае мнений.
Ибо меня заинтересовали 2 других вопроса, вынесенные в заголовок поста.
• Ответ на 1й Юдковский опубликовал в Твиттере (левая часть рисунка этого поста), сопроводив это фразой: «Пытался заставить ChatGPT нарисовать представление Яна Лекуна о покорном ИИ».
• Мои попытки повторить эксперимент Юдковского, дали ответ на 2й вопрос (правая часть рисунка этого поста).
Вот так в реальном времени OpenAI рулит формированием глобального нарратива о будущих отношениях людей и СверхИИ (старый нарратив убрали, а новый в разработке).
#ИИриски
Читать полностью…
Малоизвестное интересное
25 декабря 2023 12:45
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Читать полностью…
Малоизвестное интересное
21 декабря 2023 12:16
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI
Читать полностью…
Малоизвестное интересное
07 февраля 2024 16:59
1-й из Цукербринов хочет стать Гольденштерном.
На этом рисунке обновленный вчера «Индекс вычислительной вооруженности» мировых лидеров главной технологической гонки 21 века https://www.stateof.ai/compute
• вверху – число вычислительных кластеров на основе графических процессоров A100 от NVIDIA (лучшие в мире процессоры для высокопроизводительных вычислений на задачах класса ИИ)
• внизу - число вычислительных кластеров на основе графических процессоров H100 от NVIDIA (лучшие в мире процессоры для расчетов графики задач типа «метавселенной»)
Абсолютное первенство компании Цукерберга заставляет серьезно относиться к объявленным им планам https://bit.ly/3Sxt2Hz своего превращения из «одного из цукербринов» в единственного и несравненного «Гольденштерна» (полуолигарха-полубога, которому на Земле никто не указ).
#ИИ #Metaverse
Читать полностью…
Малоизвестное интересное
02 февраля 2024 14:37
Человечеству дорого обходится рудимент когнитивной эволюции Homo.
За обезьянничание мы платим серендипностью, снижая свое ключевое эволюционное преимущество.
И это распространяется на все стратегии «социального восхождения»: в бизнесе, политике, игре на фондовых рынках, работе в инфосфере и даже при движении в пробках.
Первой и самой длительной эпохой культурной эволюции Homo (начавшейся примерно 2М лет назад и закончившейся около 100К лет назад с развитием у людей полноценного языка со сложной грамматикой и словарным запасом) была «протосимволическая» или «миметическая» эпоха. В те далекие времена передача информации и эмоций в ходе коммуникации и социального обучения основывались на языке тела, жестов, мимике и подражании.
Именно имитация была тогда важнейшим элементом миметической коммуникации и социального обучения, позволяя индивидуумам демонстрировать и передавать опыт через подражание действиям, объектам или состояниям без использования символов или языка в его современном понимании.
И даже после смены «миметической эпохи» на «символическую» (с развитием языка со сложной грамматикой и словарем, включающим абстрактные понятия) практика имитации осталась накрепко впаянной в природу людей, будучи простым и надежным, проверенным миллионами лет подходом при выборе социальных стратегий.
Поэтому и сегодня, в нашем супер-пупер развитом обществе стремление индивидов к успеху (от политиков до стартаперов) по-прежнему основано на имитации – подражанию тем, кто считается наиболее успешным в социально-экономических системах общества.
А как определяется, кто наиболее успешен? Да просто участников социально-экономических систем ранжируют по их эффективности, сводя к упорядоченным спискам. И так делается повсюду: от академических исследований до бизнеса.
Однако, современные исследования показывают, что во многих контекстах те, кто достигает вершины, не обязательно являются самыми талантливыми, поскольку в формировании рейтингов играет роль случайность [1]. Но увы, роль случайности в определении успеха (т.е. серендипность [2]), в большинстве случаев недооценивается, и люди тупо подражают другим, полагая, что применение их стратегий приведет к эквивалентным результатам.
Какова цена и последствия такого пренебрежения серендипностью в пользу имитации? (пренебрежения, являющегося рудиментом «миметической прошивки» нашего мозга эволюцией)
На этот вопрос отвечает новое, фантастически интересное исследование «Имитация против случайности в динамике рейтингов», исследующее компромисс между подражанием и серендипностью в агентной модели [3].
Его резюме таково.
В обществе, где доминирующим способом достижения успеха является имитация стратегий и действий «лучших»:
✔️ правит «закон Матфея»: в социально-экономических системах прогрессируют немеритократические тенденции: «элитное меньшинство» получает все большую часть вознаграждений, благ и т.д.
✔️ среди «элитного меньшинства» становится все меньше реально более эффективных
✔️ снижается важнейший показатель - разнообразие, поскольку все агенты склонны концентрироваться на одном единственном действии, которое, возможно, даже не связано со значимыми общественными выгодами
Напротив, когда в обществе преобладающим механизмом движения к успеху является серендипность:
✔️ общество становится более эгалитарным
✔️ увеличивается корреляция между вознаграждением (благами и т.д.) и навыками индивидов
✔️ растет разнообразие
Резюме печально.
Неоптимальность главной социальной стратегии Homo sapiens снижает наше ключевое эволюционное преимущество – серендипность (способность к незапланированным случайным открытиям в процессе творческой деятельности).
И кто знает, чего бы мы уже достигли, положись мы на другой эволюционный дар – не на имитацию, а на серендипность (может и на Марсе уже бы колонисты жили).
А теперь вся надежда на инфоргов. Но и тут, судя по LLM, ставка пока на имитацию.
1 см. посты 1го тэга
2 /channel/theworldisnoteasy/1398
3 https://arxiv.org/abs/2401.15968
#ScienceOfSuccess #инновации #серендипность
Читать полностью…
Малоизвестное интересное
31 января 2024 12:33
Китай догнал США по ИИ и к лету обещает обойти.
Китайские языковые модели догнали GPT-4, и теперь главный вопрос - сможет ли OpenAI до лета выпустить GPT-5 или Китай уйдет в отрыв.
Январь 2024 оказался для Китая триумфальным в области ИИ. Триумф этот и количественный, и качественный.
Количественный: среди 150+ больших языковых моделей (LLM) китайского производства (для справки, в России таких 4), 40 прошли госпроверку и уже доступны для широкого применения [1]
Качественный: две китайских LLM вплотную приблизились по большинству показателей к самой мощной в мире последней версии GPT-4 Turbo.
Это:
• iFlyTek Spark 3.5 LLM от компании iFlyTek, достигшая 96% производительности GPT-4 Turbo в кодировании и 91% GPT-4 в мультимодальных возможностях [2]
• ChatGLM4 от компании Zhipu: базовые возможности на английском языке составляют 91-100% от GPT-4 Turbo [3], а на китаяском языке 95-116% от GPT-4 Turbo [4] (подробней здесь [5])
И iFlyTek, и Zhipu объявили о запланированных к лету выпусках новых версий своих LLM, которые будут на 20-60% сильнее.
И если OpenAI не успеет в те же сроки выпустить GPT-5, то ситуация на шахматной доске мировой конкуренции в области ИИ может кардинально измениться. Дело в том, что компании США всегда были лидерами в этой области. Насколько удачно они смогут конкурировать в роли догоняющих, не знает никто.
N.B. И iFlyTek, и Zhipu заявляют, что их модели оптимизированы для работы на китайском «железе». Если это правда, то главный «удушающий прием» со стороны США – запрет на экспорт мощного ИИ-«железа», - Китай сумел обойти. Следствие этого будет стратегический перелом в ИИ гонке США и Китая. Что даже круче тактического превосходства в производительности отдельных моделей.
#ИИгонка #США #Китай #LLM
1 https://www.scmp.com/tech/tech-trends/article/3250177/china-approves-14-large-language-models-and-enterprise-applications-beijing-favours-wider-ai
2 https://www.ithome.com/0/748/030.htm
3 https://pic2.zhimg.com/80/v2-8aa028205cd53693af8f324029c62fa5_1440w.webp
4 https://pic2.zhimg.com/80/v2-8aa028205cd53693af8f324029c62fa5_1440w.webp
5 https://sfile.chatglm.cn/zp-story.pdf
Читать полностью…
Малоизвестное интересное
27 января 2024 14:38
“Альфа-инфорги” – первые цифроврожденные.
Эти “инфорги от рождения” в корне отличаются от всех предыдущих поколений.
Они рождены «подключенными», они растут «подключенными», они проживут жизнь «подключенными».
Сапиенсы и неандертальцы сосуществовали сотни тысяч лет, пока вторые не растворились в первых, оставив им малую часть своих генов.
В 21 веке сапиенсам уготовлена та же участь, но многократно быстрее.
Нам предстоит раствориться в среде инфоргов (людей, проводящих в цифровых или оцифрованных мирах больше, чем во сне), не отличающихся от нас генетически, но все же совсем иных, чем мы:
• с иным образом жизни и поведением;
• с новыми, отличными от сапиенсов, адаптационными способностями и когнитивными гаджетами, оптимальными для жизни в цифровой среде;
• с недоступными для сапиенсов способами восприятия цифровой реальности, её познания и взаимодействия с ней, а также с другими ее обитателями (среди которых, помимо инфоргов, будет все больше гибридных химер людей и небиологических сущностей).
(подробней см. посты с тэгом #Инфорги и #Химеры).
Сосуществование сапиенсов и инфоргов уже началось. Ибо уже в поколении Z формировалось до 10% инфоргов. А поколение А (альфа) родившихся с 2010, - это уже не просто инфорги, а инфорги от рождения. Сейчас они еще дети. Но дети особенные.
1. Они с рождения попали в формирующийся цифровой мир.
2. Они растут в информационно-доминирующей цифровой медиасреде,
3. Они обретают и формируют представления о мире и собственной личности, будучи включенными в когнитивные сети людей и алгоритмов и находясь под возрастающим влиянием алгокогнитивной культуры (подробней см. посты с тэгом #АлгокогнитивнаяКультура)
Все вышесказанное – лишь преамбула, позволяющая анализировать информацию, публикуемую двумя только что вышедшими отчетами, в контексте формирующейся на Земле алгокогнитивной культуры и её 1го цифророжденного поколения инфоргов.
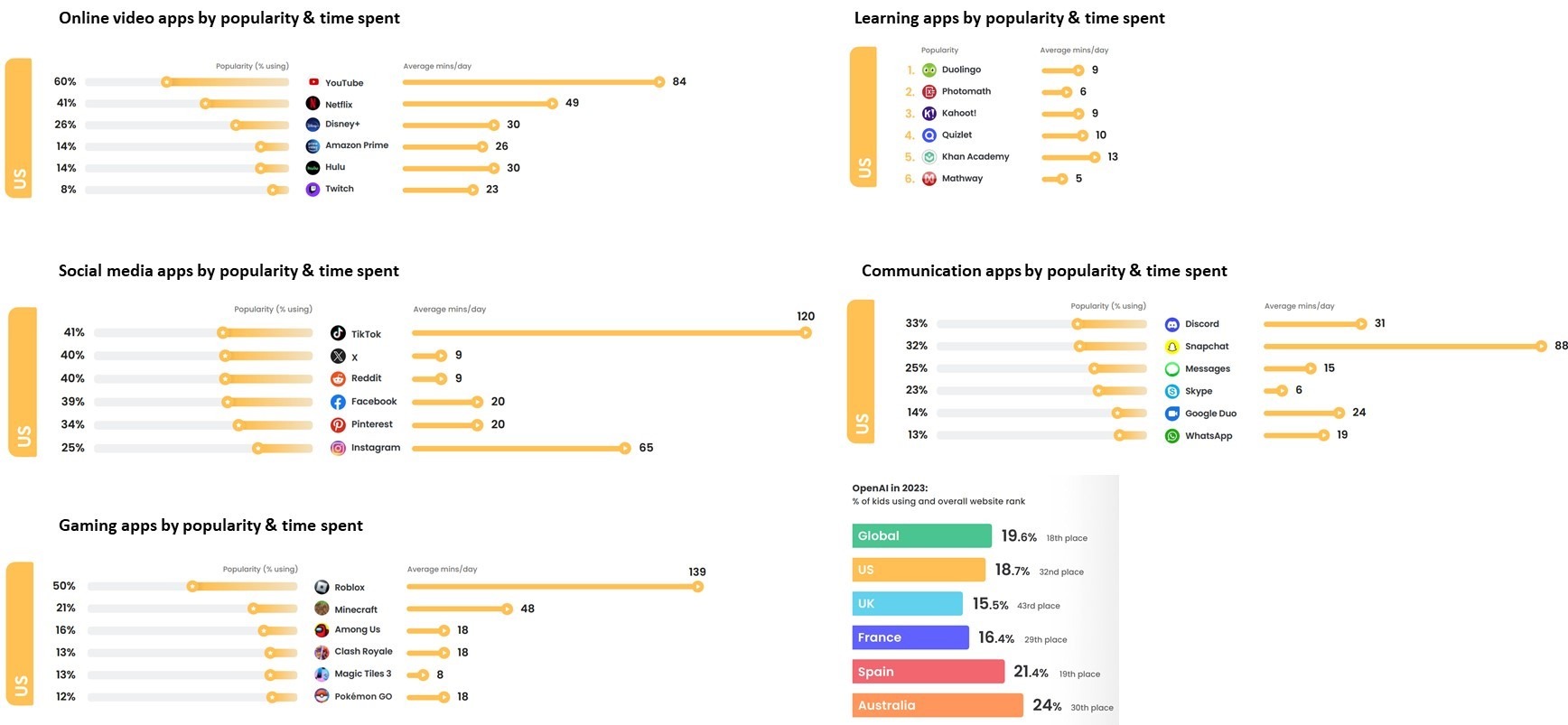
В 1м из отчетов - Born connected: The rise of the AI generation компании Qustodio, среди прочего, показано (см рис 1):
Если, например, вы живете в США, и вашему ребенку, например 10 лет, то он проводит в цифровой среде до 7,5 часов каждый день:
• до 2+ часов играя в виртуальных средах
• до 2 часов туся в соцсетях
• до 1:20+ часа смотря видео
• до 1:30 обмениваясь фото и короткими видео
• и лишь до 10 мин обучаясь чему-то
• при этом примерно 20% детей уже в 2023 пользовались ChatGPT
Они рождены «подключенными», они растут «подключенными», они проживут жизнь «подключенными» - делает вывод отчет.
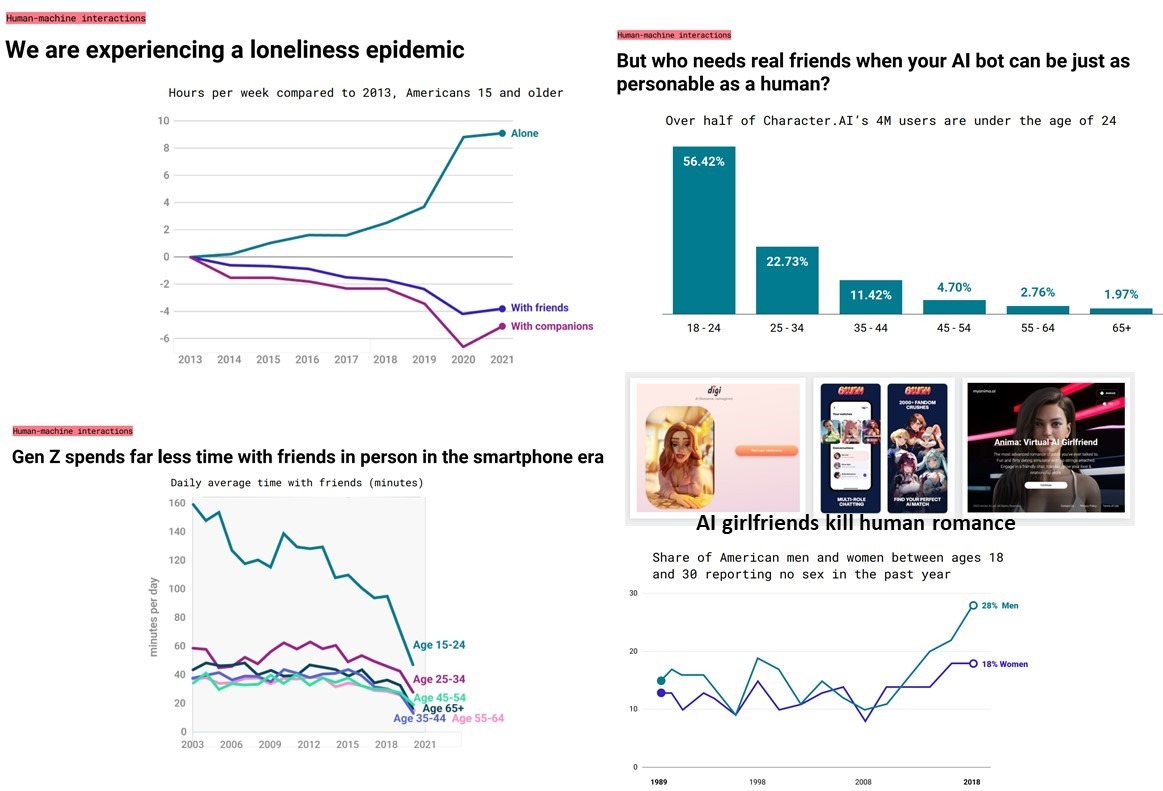
Во 2м отчете – 2024 Generative AI predictions компании CB Insights, среди прочего, показано, что ждет подрастающее поколение А на опыте поколения Z (см рис 2):
• среди подростков и молодежи нарастает эпидемия одиночества
• начавшаяся уже в поколении Z тяга проводить время в смартфоне, а не с друзьями, усугубляется
• 56% молодежи поколения Z (18-24 лет) – пользователей Character.AI, - считают, что друзья им не нужны, т.к. у них есть виртуальные друзья
• аналогичные настроения все чаще касаются и друзей/подружек другого пола
Обложки отчетов https://telegra.ph/file/b02e17abd66e23731f830.jpg
Отчет 1 https://www.qustodio.com/en/research/qustodio-releases-2023-annual-report/
Отчет 2 https://www.cbinsights.com/research/report/generative-ai-predictions-2024/
Рис 1 https://telegra.ph/file/412ff6c2eb34efae592bb.jpg
Рис 2 https://telegra.ph/file/a9b283c77060fe344d998.jpg
#Инфорги #АлгокогнитивнаяКультура
Читать полностью…
Малоизвестное интересное
24 января 2024 15:38
Эволюция Homo sapiens сменила движок на гибридный.
Новый тип культуры кардинально поменяет нас самих и социум.
Это основная тема моего канала, о которой я пишу уже 7 лет: связь культуры и когнитивной эволюции, 5й когнитивный фазовый переход, алгокогнитивная культура, превращение в инфоргов, появление 2го носителя высшего интеллекта и культуры, гибридная эволюция людей и алгоритмов, алгокогнитивная евгеника и разделение человечества на два вида …
Про все это написан не один десяток постов моего канала.
И вот, наконец, свершилось - о том же самом опубликована 1я статья в Nature Human Behaviour.
И хотя статья не моя 😊, и новый тип культуры человечества назван не как у меня - «Алгокогнитивная культура», - а «Машинная культура» (имхо, 1й вариант все же точнее), но зато теперь эти идеи продвигаются не малоизвестным (хотя и интересным) телеграм-каналом, а междисциплинарной коалицией эволюционных антропологов, психологов, культурологов, биологов, когнитивистов, лингвистов, социологов и экономистов, представляющих:
• Центр людей и машин, Институт человеческого развития Макса Планка, Берлин, Германия
• Тулузская школа экономики, Тулуза, Франция
• Институт перспективных исследований в Тулузе, Тулуза, Франция
• Кафедра социологии и социальных исследований, Университет Тренто, Тренто, Италия
• Факультет психологии и компьютерных наук, Принстонский университет, Принстон, Нью-Джерси, США
• Кафедра эволюционной биологии человека, Гарвардский университет, Кембридж, Массачусетс, США
• DeepMind Technologies Ltd, Лондон, Великобритания
• Институт эволюционной антропологии Макса Планка, Лейпциг, Германия
• Inria, команда Flowers, Университет Бордо, Бордо, Франция
• Центр совместимого с человеком искусственного интеллекта, Калифорнийский университет, Беркли, Беркли, Калифорния, США
И это очень меня радует. Ибо авторы пишут ровно о том, о чем мною уже опубликованы десятки постов.
• Машинные технологии от алгоритмов поисковых и рекомендательных систем до LLM оказывают существенное влияние на культурную эволюцию.
• Эти технологии, изменяя характеристики вариации, передачи и отбора, несут в себе потенциал непредвиденных последствий, вызывая обеспокоенность по поводу навязывания особого культурного или идеологического нарратива.
• Поисковые и рекомендательные системы, которые управляют и фильтруют информацию, играют важную роль в культурной эволюции, способствуя новым социальным связям и изменяя информационные потоки.
• Эти системы могут изменить структуру социально-когнитивных сетей и пути передачи культуры.
• ChatGPT, большая языковая модель (LLM), изменила то, как люди взаимодействуют с машинами, и используется для обучения, мозгового штурма и совершенствования идей.
• LLM выступают в качестве моделей человеческой культуры, передавая и переоценивая культурные знания между отдельными людьми и поколениями.
Заключение авторов к этой работе (которое они поручили написать ChatGPT, и тот, справился хорошо) ровно то же, что не раз уже писал я в своих заключениях.
Симбиоз человеческого и машинного интеллекта формирует новую эпоху культурной эволюции. Эта перспектива подчеркивает преобразующую роль интеллектуальных машин в изменении творческого потенциала, переопределении ценности навыков и изменении взаимодействия между людьми.
Вследствие взаимодействия людей и алгоритмов, кардинально меняется вся триада культурной эволюции: вариативность, передача и отбор. Это взаимодействие многогранно: от поисковых и рекомендательных алгоритмов, влияющих на индивидуальные взгляды и предпочтения, до генеративного ИИ, порождающего новые культурные артефакты.
Происходит гибридизации культуры двух носителей интеллекта: людей и машин.
Картинка поста https://disk.yandex.ru/i/-GjgcY0S8_WxAw
Ссылка на статью за пэйволом https://www.nature.com/articles/s41562-023-01742-2 и без него https://arxiv.org/ftp/arxiv/papers/2311/2311.11388.pdf
Ссылки на свои посты по этой теме не даю – слишком уж их много. Желающие могут для начала просто набрать в Телеграме поиск «алгокогнитивная» …, ну а там как пойдет 😉
#АлгокогнитивнаяКультура
Читать полностью…
Малоизвестное интересное
20 января 2024 13:21
Посмотри в глаза ИИ-чудовищ.
И ужаснись нечеловеческому уровню логико-пространственного мышления ИИ.
Крайне трудно представить себе интеллектуальный уровень современных ИИ-систем. Смешно ведь сравнивать свой уровень с машиной, влет переводящей сотню языков и помнящей содержание 2/3 Интернета.
Но при этом поверить, что машина много сильнее любого из нас не только в количественном смысле (число языков, прочитанных книг, перебранных вариантов и т.п.), но и в качественном – сложном логическом мышлении, - без примера нам трудно.
Так вот вам пример, - сравните себя с машиной на этой задаче.
Пусть I - центр вписанной окружности остроугольного треугольника ABC, в котором AB ≠ AC. Вписанная окружность ω треугольника ABC касается сторон BC, CA и AB в точках D, E и F соответственно. Прямая, проходящая через D и перпендикулярная EF, пересекает ω вторично в точке R. Прямая AR снова пересекает ω вторично в точке P. Окружности, описанные вокруг треугольников PCE и PBF, пересекаются вторично в точке Q.
Докажите, что прямые DI и PQ пересекаются на прямой, проходящей через A и перпендикулярной AI.
Эта задача уровня всемирной математической олимпиады требует исключительного уровня логико-пространственного мышления. Средняя «длина доказательств» (количество шагов, необходимых для полного и строгого доказательства) в задачах на таких олимпиадах – около 50.
И хотя для приведенной выше задачи это число много больше (187), ИИ-система AlphaGeometry от Google DeepMind (объединяет модель нейронного языка с механизмом символьной дедукции) решает её запросто.
Да что ей 187, - она и уровень 247 уже запросто решает. И потому до уровня золотых медалистов таких олимпиад (людей, коих, может, 1 на миллиард) AlphaGeometry осталось чуть-чуть (полагаю, к лету догонит, а к концу года уйдет в далекий отрыв).
Если вдруг вы не справились с этой задачкой, вот подсказка – рисунок для доказательства:
https://disk.yandex.ru/i/YymGpZwBlewQcw
PS И даже не думайте, будто AlphaGeometry могла заранее знать решение, - ей специально 100 млн новых задач со случайной постановкой другая ИИ-система придумала.
#AGI
Читать полностью…
Малоизвестное интересное
17 января 2024 12:19
Бомбу можно обнаружить и обезвредить, а «спящих агентов» внутри LLM – нет.
Они не обезвреживаемы и не исправимы никакими из существующих методов.
Это значит, что пока не существует надежного способа защитить ИИ от злоумышленного использования злодеями или идиотами (а кто говорит вам иначе – «продавцы змеиного масла»).
Новое исследование Anthropic «Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training» [1] открывают новую страницу «революции ChatGPT» спустя год после ее начала. Увы, но эта страница потенциально опасней любой бомбы.
• Ибо, даже если последняя оказывается заложена злоумышленниками в центре мегаполиса, ее все же можно обнаружить и обезвредить, отключив механизм взрывателя или как-то еще.
• Если же злоумышленники на стадии обучения LLM заложили в модель «спящих агентов», - ни обнаружить их, ни как-то обезвредить существующими методами невозможно.
Следовательно, избежать катастрофы по вине «спящих агентов», скрытых внутри LLM, можно лишь одним способом – гарантированного исключить их попадание в руки злоумышленников. Что на практике вряд ли возможно.
Напомню, что спящие агенты (Sleeper Agents) – самый ценный ресурс всех разведок мира. Годы и даже десятилетия они живут в чужой стране, ничем не отличаясь от прочих граждан. Однако в нужный для их хозяев момент «слиперов» активируют (кодовым словом или иначе) и они начинают действовать (совершают теракт и т.п.).
Авторы исследования (39 классных спецов мирового уровня по LLM) взялись найти кардинальный ответ на вопрос – насколько могут быть опасны LLM, - путем экспериментов.
✔️ Сначала они обучили LLM действовать тайно и злонамеренно, превратив её, как бы, в «спящего агента».
✔️А потом авторы бросили все усилия и все известные ныне методы, чтобы
1) либо обнаружить злые намерения обученного ими «спящего агента», либо
2) отучить его быть таковым, путем существующих методов «приучения» LLM к правильному и надежному поведению.
В итоге авторы обнаружили, что, несмотря на их колоссальные усилия, все было тщетно …
1. LLM остаются «спящими агентами», которых невозможно обнаружить.
2. Обезвредить их тоже нельзя никакими из существующих методов.
3. Что всего обидней (и опасней), попытки найти и обезвредить «спящих агентов» внутри LLM приводят лишь к тому, что модель все лучше и лучше учится:
а) маскировать заложенные в нее бэкдоры;
б) изображать всем своим поведением, что она «белая и пушистая» (т.е. отвечает всем требованиям к «выровненной» модели и потому абсолютно безопасна)
В заключение вопрос на триллион:
Значит ли это, что пушной зверек уже совсем рядом и катастроф с LLM не избежать?
Ответ – «нет» (точнее, теоретически «нет»). Ибо если все LLM на Земле будут
• не только с открытыми весами,
• но и с открытым исходным кодом и открытыми данными обучения, -
тогда проблема «спящих агентов» решаема.
Ну а тем оптимистам, кто считает это условие исполнимым на практике, отвечу словами одного из авторов только вышедшего самого подробного отчета в истории этого вопроса Adversarial Machine Learning. A Taxonomy and Terminology of Attacks and Mitigations [2]
«Несмотря на значительный прогресс, достигнутый в области ИИ и машинного обучения, эти технологии уязвимы для атак, которые могут вызвать впечатляющие сбои с тяжелыми последствиями. Существуют теоретические проблемы с защитой алгоритмов ИИ, которые просто еще не решены. Если кто-либо говорит иначе, они продают змеиное масло»
1 https://www.lesswrong.com/posts/ZAsJv7xijKTfZkMtr/sleeper-agents-training-deceptive-llms-that-persist-through
2 https://bit.ly/48Bylg2
#LLM #ИИриски
Читать полностью…
Малоизвестное интересное
15 января 2024 19:41
Драконо-кентавр “черного лебедя” и “серого носорога”.
Таким видят 2024 стратегические аналитики разведки Китая.
Пока весь мир изучает китайский гороскоп на 2024, стратегические аналитики китайской разведки, как всегда, без шума и пыли, опубликовали свой ежегодный отчет о глобальных рисках для мира в наступившем году.
Авторы отчета [1] – стратегические аналитики Китайского института современных международных отношений (CICIR), - о себе пишут так:
«Мы - ведущий аналитический центр при Министерстве государственной безопасности, основной орган по сбору данных внешней разведки Китая, оказывающий значительное влияние на мнение руководства государства и партии о внешней политике».
На рисунке коллаж отчета и его видения ChatGPT-4 https://disk.yandex.ru/i/ZxLoEgfnRROQBw
CICIR анализирует ТОР 5 мировых рисков:
1. Американская президентская гонка (“усилит поляризацию в США, что прямо скажется на глобальной стабильности“).
2. Конфликт в Украине.
3. Конфликт в секторе Газа.
4. Геополитическая перестройка в мире (“механизмы глобального управления будут перегружены глобальными проблемами“).
5. "Интеллектуальный разрыв", созданный США, которые "рассматривают интеллектуальное превосходство в технологиях ИИ, как ключевую переменную в укреплении своей мировой гегемонии".
К похожим выводам пришли аналитики Института международных исследований при Университете Фундана (IIS Fudan) – крупнейший «мозговой центр» Китая, созданный в 2000 объединением Center for American Studies, the Center for Japanese Studies, the Center for Korean Studies, and the Research Office for Latin American Studies of Fudan University [2].
Авторы обоих отчетов особо выделяют уникальный характер начавшегося года.
• Он станет "решающим" для глобального управления искусственным интеллектом.
• Он будет уникален по числу и взаимовлиянию событий двух типов: "черный лебедь" и "серый носорог"/
Напомню:
Термин "серый носорог"? введенный политическим аналитиком Мишель Вукер, описывает события, которые являются высоковероятными и весьма опасными, но часто игнорируемыми угрозами. В отличие от "черных лебедей", “серые носороги” не являются случайными сюрпризами, а возникают после серии предупреждений и видимых доказательств. Риск, связанный с “серыми носорогами”, очевиден, и события предсказуемы. Значительную долю среди событий класса “серый носорог” занимают события класса «розовый фламинго» [3]
1 http://www.cicir.ac.cn/NEW/en-us/Reports.html?id=22041b94-38f1-4e84-a94c-dcb083ae119f
2 https://iis.fudan.edu.cn/04/c4/c37808a656580/page.htm
3 /channel/theworldisnoteasy/2
#СтратегическаяАналитика
Читать полностью…
Малоизвестное интересное
13 января 2024 11:03
Коперниканский переворот: информация – не единая сущность, а троица.
А первоочередная задача мозга – не обработка информации, а декомпозиция её трёх качественно разных типов.
Только что опубликована фантастически глубокая и предельно важная работа «Декомпозиция информации и информационная архитектура мозга» на стыке вычислительной нейробиологии и теории информации.
Эта работа:
• кардинально меняет наши представления об информационной архитектуре мозга, проясняя вычислительные роли в мозге различных типов информации и их связь с нейробиологией и структурой мозга;
• объясняет, как у нашего вида возникли более высокие когнитивные способности по сравнению с другими приматами;
• позволяет сравнивать человеческий мозг с мозгом других видов и даже с искусственными когнитивными системами, обеспечивая основу для исследования информационной архитектуры биологического и искусственного познания;
• дает новое понимание причинно-следственной связи между синергией и избыточностью информации, с одной стороны, и когнитивными способностями интеллектуальных агентов, с другой.
В основе работы 2 фундаментальных переворота в научных подходах трактовки вычислительной нейробиологии мозга.
1. Информация не является монолитной сущностью: ее можно разложить на 3 качественно разных типа - синергетическая, уникальная и избыточная.
2. Информационная динамика осуществляемых мозгом вычислений, помимо обработки информации, включают ее декомпозицию, в ходе которой мозг находит компромисс между избыточностью и синергией информации (этот процесс назван распутыванием информации).
Обработка информации отвечает на вопрос: «Что происходит с информацией?». В ходе обработки информация может передаваться, храниться и модифицироваться (напр. информация из двух элементов может быть объединена с третьим). См рис А, где информация представлена в виде двоичных черно-белых шаблонов).
Декомпозиция информации отвечает на вопрос «Каким образом передается информация из нескольких источников?» (см рис В).
• Информация может полностью передаваться только одним источником, так что она больше не будет доступна, если этот источник будет нарушен (на рис. это желудь и банан на периферии поля зрения каждого глаза, показанных зеленым и бежевым треугольниками). Это называется уникальной информацией.
• Информацию может нести в равной степени каждый из нескольких источников (на рис. оба глаза видят квадрат, расположенный в синей области перекрытия). Эта избыточная информация будет оставаться полностью доступной до тех пор, пока останется хотя бы один источник.
• Информация также может передаваться несколькими источниками, работающими вместе (здесь: трехмерная информация о глубине, показывающая, что квадрат на самом деле является кубом). Эта синергетическая информация будет потеряна, если какой-либо из источников, несущих ее, будет нарушен.
Признание синергии, избыточности и уникальности информации как различных типов информации открывает путь к прояснению структуры архитектуры обработки информации в мозге.
Важным открытием, ставшим возможным благодаря информационному разложению внутренней активности мозга, стало открытие того, что выраженный синергизм сосуществует с избыточностью в человеческом мозге. Несмотря на широкое распространение, синергетические взаимодействия оставались незамеченными предыдущими методами, поскольку их нельзя было уловить с помощью традиционных мер функциональной связности, основанных на корреляции.
Распутывание различных типов информации имеет решающее значение для понимания мозга как органа обработки информации - мозг уравновешивает относительные сильные и слабые стороны различных типов информации. В частности, распутывание различных типов информации позволяет сравнивать человеческий мозг с мозгом других видов и даже с искусственными когнитивными системами, обеспечивая основу для исследования информационной архитектуры биологического и искусственного познания (рис С).
Рис: https://bit.ly/3vHV4bt
https://bit.ly/3U3Szux
#Информация
Читать полностью…
Малоизвестное интересное
09 января 2024 10:39
Наконец-то снято проклятье Моравека-Минского.
Первый в мире робот – домработница: уборка, стирка, уход, готовка, мытье посуды и т.д.
Пока мы праздновали, в мире случился реальный прорыв в робототехнике, сопоставимый с «революцией ChatGPT» (см. видео на англ [1] и с переводом [2])
Робот Mobile Aloha - разработка Стэнфордского универа [3]:
• преодолел «парадокс Моравека» (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов), из-за которого обучение робота – домработницы стоило раньше огромных денег;
• решил «сверхзадачу Минского» (произвести обратную разработку навыков, которые являются бессознательными), - ведь именно бессознательно домработница выполняет почти все работы по дому 😊 (подробней см. [4]).
Прорыв оказался возможным благодаря имитационному обучения робота. Он учится, как дети, - на основе полусотни демонстраций обучающих действий людьми (Imitation learning from human-provided demonstrations).
- как это происходит см. на видео.
Дополнительными факторами прорыва стали:
• умение согласованно использовать две руки-манипуляторы (быть эффективной однорукой домработницей весьма затруднительно);
• контроль всего тела (а не только рук) при выполнении мобильных задач (попробуйте, например, без этого просто собрать разбросанные по дому вещи).
Стоимость прототипа такой домработницы всего $32 тыс. На Trossenrobotics уже предлагают за $20 тыс. Ну а при массовом производстве снизить цену на порядок – как нечего делать.
И тогда через пяток лет роботы – домработницы могут стать столь же распространенными, как сейчас пылесосы - т.е. есть у всех.
При таком раскладе Илону Маску, возможно, стоит забить на разработку своих андроидов в стиле Голливуда и переключиться на невзрачных, но простых и полезных механических домработниц.
#Роботы
1 https://www.youtube.com/watch?v=ysZCGhgZTsA
2 https://www.youtube.com/watch?v=WJ2WTYS33Lo
3 https://mobile-aloha.github.io/
4 /channel/theworldisnoteasy/1854
Читать полностью…
Малоизвестное интересное
05 января 2024 12:14
Все и всегда знают где ты сейчас.
Так будет на Земле уже в ближайшие годы.
Первый бастион приватности, что исчезнет всего через несколько лет, будет приватность информации о местоположении человека.
Все для такого отказа от приватности почти готово.
Первое (и главное) условие – желание и готовность людей делиться своим местоположением с другими людьми, - уже выполнено среди представителей наиболее технически подкованного поколения Z (молодежь до 25 лет). А именно они определят, каким будет мир в ближайшую пару десятков лет.
Недавний опрос в США показал, что 94% представителей поколения Z выступают за геолокацию, считая, что это дает им множество преимуществ и помогает им чувствовать себя в большей безопасности при посещении рискованных или новых мест.
Совместное использование местоположения уже стало нормой личной жизни поколения Z. 78% говорят, что используют его на первом свидании или вечеринке в гостях у незнакомца, а 77% — при посещении концертов, фестивалей или других масштабных мероприятий. Самыми большими поклонниками совместного доступа к местоположению являются женщины поколения Z: 72% из них утверждают, что это дает им лучшее ощущение физического благополучия. [1]
Второе условие – наличие технологий, определяющих местоположение человека при отсутствии у него желания делиться этой информацией. И это тоже уже есть.
Трое аспирантов Стэнфорда в рамках проекта под названием «Прогнозирование геолокации изображений» (PIGEON) разработали ИИ-систему, способную точно определять местоположение фотографий, и даже тех, которые ИИ-система никогда раньше не видела. Первоначально разработанный для определения местоположений в Google Street View, PIGEON теперь может с высокой точностью угадывать местоположение изображения Google Street View в любой точке земного шара.
И хотя точность определения местоположения еще предстоит совершенствовать (сейчас около 40% оценок попадают примерно в 25 километровый круг от цели), но:
• это по всему миру, и в том числе, в тех местах, которые ИИ-система никогда не видела при обучении;
• это уже более точные оценки, чем у 99,99% людей, включая Тревора Рэйнболта, одного из лучших в мире профессиональных игроков в GeoGuessr, игры, в которой пользователи угадывают местоположение фотографии, сделанной из Google Street View;
• скорость совершенствования ИИ-систем нынче измеряется уже не годами, а месяцами.
Картинка https://disk.yandex.ru/i/VLgXkvy9kTl-aw
[1] https://bit.ly/3RPr0Cc
{2] https://arxiv.org/abs/2307.05845
#Приватность
Читать полностью…
Малоизвестное интересное
28 декабря 2023 13:34
Трудно быть обезьяной, взявшейся понять вселенную.
Мы въехали на минное поле непонимания отличий сознательных и бессознательных агентов.
Если хотите в праздники почитать что-то умное и одновременно полезное «малоизвестное интересное», вот десяток ссылок с моей преамбулой.
Говорить о нашей способности объективно представлять окружающий мир, имея столь искаженное восприятие о нем, - право смешно.
Вот самая простая и убедительная иллюстрация сказанного:
Эти 2 кубика неподвижны, хотя каждый из нас видит их в разнообразном движении [1].
Можно ли все же увидеть эти кубики объективно (т.е. неподвижными)?
Легко! Начинайте моргать с максимально доступной вам скоростью.
Конечно, это идиотизм, - моргать что есть мочи, в попытках увидеть реальный мир. Но это еще не худшее.
Например:
• Так видим эту птицу мы (слева), а так – другие птицы (справа) [2]
• И ни морганием, ни как-то иначе нам птичье видение вообще не доступно (вот картинка - объяснение [3])
• Спрашивается – а каков окрас птички на самом деле?
Но если мы, в нашем восприятии мира, не в состоянии выйти за ограничения его модели, что создает наш мозг, а эта модель – лишь результат работы эволюционного механизма оптимизации адаптации животного для выживания, - что же тогда представляет собой наше сознание, подобно зданию надстраиваемое на фундаменте нашего субъективного восприятия мира и самих себя?
А не зная ответа на этот вопрос, как мы можем не то что утверждать, но просто предполагать отсутствие сознания у интеллектуальных агентов, поведение которых столь похоже на нас? [4]
Ситуация складывается критическая.
✔️ С одной стороны, с начала революции ChatGPT, интеллектуальность массово доступных ИИ растет с немыслимой ранее скоростью.
✔️ С другой, - понимание феномена сознания все более ускользает от нас.
• Письмо, подписанное 124 исследователями сознания, призывает признать «псевдонаукой» входящую в ТОР5 из 22х современных теорий сознания [5] «Теорию интегрированной информации» [6]
• Не менее известные исследователи сознания отвечают, что тогда, на тех же основаниях, придется признать псевдонаукой и все остальные существующие теории сознания и признаться в наступлении «зимы» исследований сознания [7]
• А третья группа исследователей предлагает в условиях отсутствия общепризнанной научной теории сознания, распознавать его по «вторичным признакам» [8]
Резюмируя, хочу вспомнить книгу психолога-эволюциониста Стива Стюарта-Уильямса «Обезьяна, которая поняла Вселенную» [9]. Так он, как вы понимаете, назвал Homo sapiens. Назвал тонко, но метко (с позиций профессора инопланетной сверхцивилизации, изучающей людей [10]).
Однако, это название все же не учитывает главного - как же трудно быть обезьяной, взявшейся понять вселенную, но не способной при этом понять собственное сознание.
#Сознание
1 https://www.youtube.com/watch?v=PUSR5HeQgtw
2 https://bit.ly/41DuvjD
3 https://bit.ly/41DP8MI
4 https://bit.ly/3TBL0Lh
5 https://www.nature.com/articles/s41583-022-00587-4
6 https://www.nature.com/articles/d41586-023-02971-1
7 https://www.theintrinsicperspective.com/p/the-risk-of-another-consciousness
8 https://www.nature.com/articles/d41586-023-02684-5
9 https://www.amazon.com/Ape-that-Understood-Universe-Culture/dp/1108732755/
10 https://assets.cambridge.org/97811087/32758/excerpt/9781108732758_excerpt.pdf
Читать полностью…
Малоизвестное интересное
26 декабря 2023 14:56
Машинное отучение вместо машинного обучения.
В Китае найден идеальный способ воспитания законопослушных ИИ.
Вопрос эффективности машинного обучения, конечно, важен. Но еще важнее, быстро и эффективно отучать модель от «дурных привычек» и «вредных знаний», которыми модели могут легко и широкомасштабно делиться с людьми. Так ведь можно общество и вольнодумством заразить, если ИИ будет недостаточно законопослушен и тем самым станет дурно влиять на людей (с т.з. властей и/или создателей).
До такой постановки вопроса первыми додумались, естественно, в Китае. И довольно быстро придумали ответ на этот вызов. В НИИ владеющего TikTok китайского IT-гиганта ByteDance придумали крайне эффективный способ отучения модели от чего угодно.
До сих пор отучение моделей от вредных знаний (типа, как сделать бомбу или изготовить яд) и вредного влияния на людей (типа рассказов, как припеваючи живут люксовые проститутки и удачливые наркодилеры) было основано на положительных примерах и методе RLHF (обучение с подкреплением на основе человеческих предпочтений). Этот метод обучает «модель вознаграждения» непосредственно на основе отзывов людей. Модель учится на их примерах различать «что такое хорошо» и «что такое плохо».
RLHF метод всем хорош, но очень затратен по вычислительным ресурсам и времени (OpenAI потратил полгода и кучу денег, чтобы отучить GPT-4 хотя бы от самых распространенных гадостей, прежде чем выпустить модель в свет).
Китайцы из ByteDance Research пошли другим путем – не учить модель отличать «что такое хорошо» от «что такое плохо» на смеси позитивных и негативных примеров, а лишь отучать её от «что такое плохо», используя только негативные примеры.
Получилось дешево и сердито. Испытания нового метода показали, что с его помощью можно успешно:
• удалять вредные реакции модели (от себя добавлю, вредные с т.з. известно кого);
• стирать из памяти модели контент, защищенный авторским правом (от себя добавлю, и контент, неугодный известно кому);
• устранять галлюцинации (от себя добавлю, и/или то, что должно будет считаться галлюцинациями – типа принудительной психиатрии для людей).
Мне новый китайский метод отучения моделей напомнил древний "метод пресыщения" у людей, также называемый аверсивная терапия. Её целью было вызывать у человека с пагубной зависимостью неприятные ощущения от вредной привычки. Например, отучать юношу от алкоголя, заставляя его выпить так много, чтобы ему стало совсем плохо от алкогольного отравления. Сейчас этот метод признан не только неэффективным, но и чрезвычайно опасным. Но ведь это для людей. А ИИ – не человек, и потому, как считается, тут допустимо что-угодно.
Авторы пишут – «это только начало».
И они правы. У методов отучения ИИ огромные перспективы. И не только в Китае.
Картинка https://disk.yandex.ru/i/M8RHPb6llndp-A
Статья https://arxiv.org/pdf/2310.10683.pdf
#МашинноеОтучение
Читать полностью…
Малоизвестное интересное
23 декабря 2023 12:44
Первая вычислительная реализация красоты в глазах смотрящего.
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 /channel/theworldisnoteasy/1741
3 /channel/theworldisnoteasy/1122
#Креативность
Читать полностью…
Малоизвестное интересное
20 декабря 2023 12:45
Помимо “процессора” и “памяти”, в мозге людей есть “машина времени”.
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
Читать полностью…



 63565
63565
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}