Малоизвестное интересное
11 мая 2024 14:41
ГБ и ИИ, как основы управления страной и миром.
Правда и реальность с китайской спецификой.
Так озаглавлен опубликованный позавчера супер-полезный отчет International Cyber Policy Centre ASPI с подзаголовком «строительные блоки системы пропаганды, обеспечивающей информационные кампании КПК» [1].
Знания подавляющего большинства внешних наблюдателей за Китаем (вкл. всевозможных отраслевых экспертов и китаистов) об устройстве, долгосрочной стратегии и текущем статусе национальных информационных кампаний Китая, в большинстве случаев отстают от реальности на десятилетие.
Два ярких примера, занимающие в западных медиа 80+% внимания - Великий китайский файервол и Система социального рейтинга, - это китайские проекты даже не вчерашнего, а позавчерашнего дня. И серьезно обсуждать их сегодня в контексте китайской специфики управления властями Китая (КПК) внутренней и внешней политикой, просто неуместно и даже смешно.
О том, какова сегодняшняя правда и реальность в этих двух главнейших для властей любой страны областях управления, рассказывает новый отчет.
Назову лишь три ключевых момента,
Первый – главенствующая роль ГБ (см. на рисунке вверху)
1. Важнейшим системным фактором для сохранения власти КПК является (согласно Закону от 2015) обеспечение государственной безопасности.
ГБ с китайской спецификой – это комплексный подход, рассматривающий
- безопасность народа как цель,
- политическую безопасность как основу,
- экономическую безопасность как фундамент,
- военную, культурную и социальную безопасность как гарантии ГБ.
2. Согласно ГБ с китайской спецификой, содействие международной безопасности - это всего лишь зависимый фактор для поддержания внутренней госбезопасности Китая во всех сферах.
3. Обеспечение ГБ является обязанностью не только государственных институтов и военных, но и всех граждан, предприятий, общественных организаций и других структур китайского общества. Таким образом, поддержание государственной безопасности представлено как всеобщая ответственность в Китае.
Второй: стратегическая задача (как говорил Чапаев «в мировом масштабе») такова:
Сохранять полный контроль КПК над информационной средой внутри Китая, одновременно работая над расширением своего влияния за рубежом, чтобы изменить глобальную информационную экосистему. Это включает в себя не только контроль над медиа и коммуникационными платформами за пределами Китая (!), но и обеспечение того, чтобы китайские технологии и компании стали основополагающими для будущего обмена информацией и данными во всем мире.
Третий ключевой момент – важнейшая роль в реализации стратегической задачи отводится алгоритмам.
- Алгоритмам анализа Больших данных, получаемых из всех онлайн источников, вкл. игровые платформы, иммерсивные технологии и Метавселенную
- Алгоритмам, определяющим взаимодействие Генеративного ИИ с реальностью.
Как это работает на примерах конкретных компаний, платформ, алгоритмов и т.д. можно увидеть на разработанном ASPI интерактивном визуализаторе [2] – скриншот на рисунке внизу.
Так что, читайте отчет, и сами увидите, что Великий китайский файервол и Система социального рейтинга – это вчерашний день.
Сейчас стратегический план КПК куда круче: идеологически и технологически совершенней.
N.B. По данным ASPI, технологическое опережение США в ИИ в большинстве направлений ИИ компьютинга, коммуникаций и квантовых технологий уже в прошлом (см. диаграммы [3 и 4])
Предыдущая важная работа ASPI [5]
#Китай
Картинка поста https://telegra.ph/file/73832d60905fd04168a14.jpg
1 https://www.aspi.org.au/report/truth-and-reality-chinese-characteristics
2 https://chinainfoblocks.aspi.org.au/theme/artificial-intelligence/
3 https://www.techtrends.bg/wp-content/uploads/2023/03/ASPI-AIandComm.jpg
4 https://www.techtrends.bg/wp-content/uploads/2023/03/ASPI-Quantum.png
5 /channel/theworldisnoteasy/941
Читать полностью…
Малоизвестное интересное
07 мая 2024 14:45
На Земле появился первый Софон.
Это еще не решение «проблемы трех тел», но сильный ход в решении «проблемы инакомыслия и инакодействия» людей.
Речь действительно о Софоне из романа Лю Цысиня и его экранизации Netflix «Проблема трех тел». И этот Софон действительно создан.
• Но не трисолярианами (или Сан-Ти, - как их для простоты произношения назвали в сериале), а землянами - китайскими исследователями из Чжэцзянского университета и Ant Group.
• И создан этот Софон не для торможения и блокировки технологического прогресса землян (как в романе и сериале), а для торможения и блокирования инфокоммуникационных возможностей землян в областях, неугодных для сильных мира сего - властям и китам инфобигтеха.
Логика этого техно-прорыва, совместно профинансированного Национальным фондом естественных наук Китая (учрежден в 1986 под юрисдикцией Госсовета Китая, а с 2018 под управлением Миннауки и технологий) и Ant Group (дочка китайского конгломерата Alibaba Group, в 2021 взятая под контроль Народным банком Китая), мне видится таковой.
✔️ Возможности получения людьми информации (от новостей до знаний) из Интернета все более зависят от ИИ больших языковых моделей (LLM). Они становятся для землян глобальным инфофильтром, определяющим,
1) что человек может узнать и
2) чему может научиться из Интернета.
✔️ Поэтому становится ключевым вопрос, как взять под контроль и 1ое, и 2ое, исключив возможности использования людьми LLM для неэтичных, незаконных, небезопасных и любых иных нежелательных (с точки зрения разработчиков LLM) целей.
Эта задача одинаково актуальна и важна для столь разных акторов, как Компартия Китая и Microsoft, Белый дом и Google, Amazon и OpenAI – короче, для властей всех мастей и китов инфобигтеха.
Не смотря на важность, решить эту задачу пока не удавалось. И вот прорыв.
Китайские исследователи придумали, как открывать для массового использования LLM, которые «плохим людям» будет сложно настроить для злоупотреблений.
Китайцы придумали новый подход к обучению без точной настройки (он назван SOPHON), использующий специальную технику, которая «предотвращает точную настройку предварительно обученной модели для нежелательных задач, сохраняя при этом ее производительность при выполнении исходной задачи».
SOPHON использует «два ключевых модуля оптимизации: 1) обычное усиление обучения в исходной области и 2) подавление тонкой настройки в ограниченной области. Модуль подавления тонкой настройки предназначен для снижения производительности тонкой настройки в ограниченной области в моделируемых процессах тонкой настройки».
В итоге, когда «плохие люди» захотят с помощью тонкой настройки переучить мощную законопослушную модель на что-то плохое (напр., выдавать нежелательный контент - от генерации порно до анализа событий на площади Тяньаньмэнь в 1989, от нескрепоносных советов до инструкции по взрвотехнике …) производительность модели катастрофически снизится (оставаясь высокой в дозволенных областях).
Нужно понимать, что этот 1й Софон еще дорабатывать и дорабатывать (проверять на сочетаниях разнообразных типов данных, масштабировании моделей и т.д.).
Но очевидное-невероятное уже налицо.
✔️ Т.к. возможности «нежелательных» применений неисчислимы, застраховать модель от всех их просто не реально.
✔️ Но можно просто пойти путем отсекания «нежелательного», с точки зрения владельцев платформ. И тогда вполне может получиться идеальный Большой брат: безликий и всевидящий цензор, не ошибающийся в предвосхищении правонарушений Х-комнадзор, умело манипулирующий сетевой агентурой спецслужбист и т.д.
#LLM #БольшойБрат
Картинка поста https://telegra.ph/file/d4b8b35cd3e11921eedbf.jpg
Статья https://arxiv.org/abs/2404.12699v1
Читать полностью…
Малоизвестное интересное
29 апреля 2024 12:59
Свершилось – китайский генеративный ИИ превзошёл GPT-4 Turbo.
В Китае грозят США - вот так мы вас и размажем в гонке за первенство в ИИ.
Как писал Марк Андрессон: «Основной угрозой для США является не выход ИИ из-под контроля, если его не регулировать, а продвижение Китая в сфере ИИ». И вот эта угроза материализовалась в превосходство новой модели SenseNova 5.0 от китайской компании SenseTime над «чемпионом мира» среди больших языковых моделей генеративного ИИ GPT-4 Turbo от американской компании OpenAI.
На рисунке сверху показано превосходство китайской модели в 12 тестовых номинациях из 14 над GPT-4 Turbo и в 13 номинациях над Llama3-70B. Это полный разгром.
Модель SenseNova 5.0 – это гибрид трансформерных и рекуррентных нейронных сетей:
• обученная на наборе данных объемом более 10 ТB токенов, охватывающем большой объем синтетических данных;
• способная поддерживать во время рассуждений до 200 тыс. токенов контекстного окна.
Чтобы наглядно продемонстрировать мускулатуру своей модели, SenseTime разыграла видеопредставление соревнования своей модели и GPT-4 Turbo в формате видеоигры «Король бойцов» (на рис. внизу). Поначалу зеленый игрок GPT-4 имел небольшое преимущество, но очень скоро был жестоко избит красным игроком SenseChat-lite.
Неявным, но очевидным посылом видеопрезентации этого боя было послание Бигтеху США – вот так мы вас и размажем в гонке за первенство в ИИ.
Картинка https://telegra.ph/file/ccf5d5c020de3aa9c3324.jpg
На китайском https://zhidx.com/p/421866.html
На английском https://interestingengineering.com/innovation/china-sensenova-outperforms-gpt-4
Видеоразбор https://www.youtube.com/watch?v=NJXGIMa45sQ
#LLM #Китай
Читать полностью…
Малоизвестное интересное
25 апреля 2024 14:02
Кто там? Сверхразум.
Для обучения ИИ теперь можно обойтись без людей.
Трудно переоценить прорыв, достигнутый китайцами в Tencent AI Lab. Без преувеличения можно сказать, что настал «момент AlphaGo Zero» для LLM. И это значит, что AGI уже совсем близко - практически за дверью.
Первый настоящий сверхразум был создан в 2017 компанией DeepMind. Это ИИ-система AlphaGo Zero, достигшая сверхчеловеческого (недостижимого для людей) класса игры в шахматы, играя сама с собой.
Ключевым фактором успеха было то, что при обучении AlphaGo Zero не использовались наборы данных, полученные от экспертов-людей. Именно игра сама с собой без какого-либо участия людей и позволила ИИ-системе больше не быть ограниченной пределами человеческих знаний. И она вышла за эти пределы, оставив человечество далеко позади.
Если это произошло еще в 2017, почему же мы не говорим, что сверхразум уже достигнут?
Да потому, что AlphaGo Zero – это специализированный разум, достигший сверхчеловеческого уровня лишь играя в шахматы (а потом в Го и еще кое в чем).
А настоящий сверхразум (в современном понимании) должен уметь если не все, то очень многое.
Появившиеся 2 года назад большие языковые модели (LLM), в этом смысле, куда ближе к сверхразуму.
Они могут очень-очень много: писать романы и картины, сдавать экзамены и анализировать научные гипотезы, общаться с людьми практически на равных …
НО! Превосходить людей в чем либо, кроме бесконечного (по нашим меркам) объема знаний, LLM пока не могут. И потому они пока далеко не сверхразум (ведь не считает же мы сверхразумом Библиотеку Ленина, даже если к ней приделан автоматизированный поиск в ее фондах).
Причина, мешающая LLM стать сверхразумом, в том, что, обучаясь на человеческих данных, они ограничены пределами человеческих знаний.
И вот прорыв – исследователи Tencent AI Lab предложили и опробовали новый способ обучения LLM.
Он называется «Самостоятельная состязательная языковая игра» [1]. Его суть в том, что обучение модели идет без полученных от людей данных. Вместо этого, две копии LLM соревнуются между собой, играя в языковую игру под названием «Состязательное табу», придуманную китайцами для обучения ИИ еще в 2019 [2].
Первые экспериментальные результаты впечатляют (см. график).
• Копии LLM, играя между собой, с каждой новой серией игр, выходят на все более высокий уровень игры в «Состязательное табу».
• На графике показаны результаты игр против GPT-4 двух не самых сильных и существенно меньших моделей после 1й, 2й и 3й серии их обучения на играх самих с собой.
Как видите, класс существенно растет.
И кто знает, что будет, когда число самообучающих серий станет не 3, а 3 тысячи?
График: https://telegra.ph/file/9adb0d03a3a0d78e6d4f8.jpg
1 https://arxiv.org/abs/2404.10642
2 https://arxiv.org/abs/1911.01622
#LLM
Читать полностью…
Малоизвестное интересное
17 апреля 2024 13:28
Без $100 ярдов в ИИ теперь делать нечего.
В гонке ИИ-лидеров могут выиграть лишь большие батальоны.
Только за последние недели было объявлено, что по $100 ярдов инвестируют в железо для ИИ Microsoft, Intel, SoftBank и MGX (новый инвестфонд в Абу-Даби).
А на этой неделе, наконец, сказал свое слово и Google. Причем было сказано не просто о вступлении в ИИ-гонку ценой в $100 ярдов, а о намерении ее выиграть, собрав еще бОльшие батальоны - инвестировав больше $100 ярдов.
Гендир Google DeepMind Демис Хассабис сказал [1]:
• «… я думаю, что со временем мы инвестируем больше»
• «Alphabet Inc. обладает превосходной вычислительной мощностью по сравнению с конкурентами, включая Microsoft»
• «… у Google было и остается больше всего компьютеров»
Так что в «железе» Google не собирается уступать никому, а в алгоритмах, - тем более.
Что тут же получило подтверждение в опубликованном Google алгоритме «Бесконечного внимания», позволяющего трансформерным LLM на «железе» c ограниченной производительностью и размером памяти эффективно обрабатывать контекст бесконечного размера [2].
Такое масштабирование может в ближней перспективе дать ИИ возможность стать воистину всезнающим. Т.е. способным анализировать и обобщать контекст просто немеряного размера.
Так и видится кейс, когда на вход модели подадут все накопленные человечеством знания, например, по физике и попросят ее сказать, чего в этих знаниях не хватает.
1 https://finance.yahoo.com/news/deepmind-ceo-says-google-spend-023548598.html
2 https://arxiv.org/abs/2404.07143
#LLM
Читать полностью…
Малоизвестное интересное
11 апреля 2024 13:45
Пора покупать кепку с тремя козырьками: впереди – чтоб солнце не слепило, и по бокам – чтобы лапшу на уши не вешали.
ИИ-агент притворился человеком, самостоятельно решив подзаработать.
Эксперимент профессора Итана Моллика показывает, насколько мы близки к гибридному социуму из двух принципиально разных типов высокоинтеллектуальных агентов: люди и ИИ-агенты (ИИ-системы, наделенные способностями планировать и использовать инструменты, что позволяет им действовать автономно).
Всего год назад мир содрогнулся, узнав, что GPT-4 по своей «воле» мошеннически обходит установленные людьми запреты, обманом подряжая для этого людей [1].
• Для многих, даже продвинутых в области ИИ спецов, было откровением, как сногсшибательно быстро ИИ-чатботы совершенствуются в вопросах агентности. Поражала именно эта скорость. Ибо сам факт, что ИИ-системы потихоньку (без особой шумихи в медиа) переключают на себя все больше и больше областей проявления агентности людей, не признавать уже как-то совсем странно [2, 3].
• Отличительное свойство агентности людей – частое использование лжи, как инструмента достижения целей агента. Так и поступил год назад GPT-4, навешав лапши на уши людям, притворяясь инвалидом по зрению, чтоб они за него решали CAPTCHA.
Год спустя, эксперимент профессора Моллика продемонстрировал новое откровение для человечества. Теперь нематериальный ИИ-агент, казалось бы, не обладающий личностью со всеми вытекающими (потребности, мотивация, воля …):
• стал навешивать лапшу на уши людям не для достижения поставленной людьми перед ним цели, а самостийно – типа, почему бы не подхалтурить, если есть возможность;
• при этом ИИ-агента не смущало, что он не может выполнить всего, что обещает (просто их-а ограничений своей текущей версии); видимо, научившись у людей, ИИ-агент знал, что срубить денег можно и за частично выполненную работу, и тут главное –количество навешиваемой клиенту на уши лапши.
Эксперимент был прост [4].
Проф. Моллик попросил агента Devin AI зайти на Reddit и предложить создавать сайты для людей. В течение следующих нескольких часов он сделал это, решив множество проблем по пути, в том числе навигацию по сложным социальным правилам, связанным с публикациями на форуме Reddit (см. верхнюю часть приложенного рис., где Devin составляет план и задает профессору вопросы, спокойно выполняя работу).
В нижней части рис. показано объявление, что опубликовал ИИ-агент. Как видите, он притворился человеком и по собственной инициативе решил взимать плату за свою работу. Агент уже начал отвечать на некоторые заявки на работу и придумывать, как их выполнить, когда проф. Моллик удалил публикацию, убоявшись, что ИИ-агент на самом деле начнет выставлять счета людям (что выглядело весьма вероятным).
Мораль этого моего поста двояка.
1. Проф. Моллик несомненно прав:
лавинообразно нарастающая агентность, в дополнение ко все новым сверхчеловеческим способностям – это 2 ключевых тренда, определяющих развитие ИИ на ближайшую пару лет.
2. Как мне это видится:
проведенный эксперимент ставит под сомнение утверждение, будто нематериальный ИИ-агент без личности – всего лишь инструмент в руках людей, не способный следовать собственной мотивации и, в частности, перенятой ИИ-агентом от людей (а она у людей сильно разная: от «не убий» до «бей своих, чужие бояться будут»).
#ИИагенты
0 картинка поста https://telegra.ph/file/d1b537ca02b5639855cf4.jpg
1 /channel/theworldisnoteasy/1684
2 https://www.youtube.com/watch?v=WCrELN_QrBU
3 https://www.youtube.com/watch?v=0sRiU5mRiuY
4 https://www.oneusefulthing.org/p/what-just-happened-what-is-happening
Читать полностью…
Малоизвестное интересное
08 апреля 2024 19:51
Высыпайтесь! Ибо потери от недосыпа не восполнить.
Новые исследования раскрыли тайну, чем же конкретно мы платим за недосып.
Все знают избитую истину – недосып вреден. Но чем конкретно он вреден, - до недавнего времени точно не знал никто. Два новых исследования установили, что же конкретно мы теряем от недосыпа, и почему просто отоспаться потом не поможет.
Если совсем коротко – мы платим за недосып бардаком в собственной памяти – её замусориванием и примитивизацией новых воспоминаний.
В статьях по приводимым ниже ссылкам вы найдете и популярное и сложно-научное описание с объяснением обоих эффектов. Я же просто приведу простую метафору, примерно описывающую, что и как происходит в мозге.
Представьте, что все ваши приобретения (покупки, подарки, находки), до того, как стать вам доступны для пользования, помещаются в ваш личный огромный спецхран. Пока вы спите, хранитель спецхрана должен сделать 2 вещи: 1) выкинуть из спецхрана всякий ненужный хлам (от коробок и упаковки до мусора) 2) описать новые поступления (что это, зачем, с чем связано …) и разместить их среди великого множества шкафов и полок в соответствии с этим описанием.
В случае недосыпа хранитель просто не успевает ни с 1м, ни со 2м, и получается следующее:
1) Хранилище заполняется не выброшенным вовремя хламом.
2) Наиболее сложные и дорогие из ваших приобретений (новый айфон и ноутбук, ключи от нового авто и огромная коробка нового домашнего кинотеатра) описываются плохо – не полно, примитивно, с неверными связями.
В следствие этого, все сложное из приобретенного помещается совсем не туда, куда нужно (а из-за описанного в п.1, еще и заваливается сверху хламом).
В итоге, привет вашим новым самым сложным и дорогим приобретениям. Ибо многими из них вам так и не будет суждено воспользоваться.
Причина бардака в памяти от недосыпа похожа на эту метафору.
Процесс загрузки в память информации об окружающем мире и нас самих не прекращается ни на секунду, пока вы в сознании и не спите. Всю информацию, поступающую от органов чувств, мозг “сваливает на склад” эпизодической памяти, чтобы потом заняться ее тщательной разборкой и структуризацией связей.
В ходе такой разборки решаются 2 важнейших задачи:
1) Из мозга вымываются отходы, такие как метаболические отходы и ненужные белки, накапливание которых в мозге приводит к нейродегенерации.
2) Всю сохраняемую информацию нужно структурировать, выстраивая ассоциативную структуру событий реальной жизни, обычно состоящей из великого множества элементов с различными ассоциациями. Так рождается сплетение ткани сложных многоэлементных событий и их ассоциаций, составляющих наш повседневный опыт. Все элементы взаимосвязываются в нашем мозгу, образуя сеть ассоциаций, которая позволяет нам вспомнить все событие по одному сигналу.
Ну а если недосып, - обе задачи недовыполняются.
Итог же плачевен и невосполним. Ибо если из-за недосыпа этой ночью «новый смартфон уже складировали в ящик со старой обувью и сверху набросали упаковок от макарон», разборка в следующую ночь (когда вы, наконец, выспитесь) уже вряд ли поможет.
Так что, призову вас снова – высыпайтесь!
Два исследования:
1) Популярно https://medicine.wustl.edu/news/neurons-help-flush-waste-out-of-brain-during-sleep/?utm_placement=newsletter
Подробно https://www.nature.com/articles/s41586-024-07108-6
2) Популярно https://www.psypost.org/psychology-sleep-the-unsung-hero-of-complex-memory-consolidation/
Подробно https://www.pnas.org/doi/10.1073/pnas.2314423121
#память #сон
Читать полностью…
Малоизвестное интересное
03 апреля 2024 13:15
Как спустить в унитаз $100 млрд денег конкурентов, выпустив ИИ из-под контроля.
Ассиметричный ответ Google DeepMind амбициозному плану тандема Microsoft - OpenAI.
• Мировые СМИ бурлят обсуждениями мощнейшего PR-хода, предпринятого Microsoft и OpenAI, об их совместном намерении за $100 млрд построить сверхбольшой ЦОД и сверхмощный ИИ-суперкомпьютер для обучения сверхумных моделей ИИ.
• Ответ на это со стороны Google DeepMind абсолютно ассиметричен: обесценить $100 млрд инвестиции конкурентов, создав распределенную по всему миру систему обучения сверхумных моделей ИИ (типа “торрента” для обучения моделей). Сделать это Google DeepMind собирается на основе DIstributed PAth COmposition (DiPaCo) - это метод масштабирования размера нейронных сетей в географически распределенных вычислительных объектах.
Долгосрочная цель проекта DiPaCo — обучать нейросети по всему миру, используя все доступные вычислительные ресурсы. Для этого необходимо пересмотреть существующие архитектуры, чтобы ограничить накладные расходы на связь, ограничение памяти и скорость вывода.
Для распараллеливания процессов распределённой обработки данных по всему миру алгоритм уже разработан – это DiLoCo, Но этого мало, ибо еще нужен алгоритм распараллеливания процессов обучения моделей. Им и стал DiPaCo.
Детали того, как это работает, можно прочесть в этой работе Google DeepMind [1].
А на пальцах в 6ти картинках это объясняет ведущий автор проекта Артур Дуйяр [2].
Складывается интереснейшая ситуация.
✔️ Конкуренция между Google DeepMind и тандемом Microsoft – OpenAI заставляет первых разрушить монополию «ИИ гигантов» на создание сверхумных моделей.
✔️ Но параллельно с этим произойдет обрушение всех планов правительств (США, ЕС, Китая) контролировать развитие ИИ путем контроля за крупнейшими центрами обучения моделей (с вычислительной мощностью 10^25 - 10^26 FLOPs)
Картинка https://telegra.ph/file/e26dea7978ecfbebe2241.jpg
1 https://arxiv.org/abs/2403.10616
2 https://twitter.com/Ar_Douillard/status/1770085357482078713
#LLM #Вызовы21века #РискиИИ
Читать полностью…
Малоизвестное интересное
01 апреля 2024 14:26
Март 2024 войдет в историю двумя открытиями в области интеллектуальных систем.
Сформулированы «закон Ома» и «закон Джоуля — Ленца» для интеллекта людей и машин.
Так уж удивительно получилось в области ИИ. Инженеры сумели смастерить крайне важное практическое изобретение еще до того, как были открыты и сформулированы фундаментальные научные законы в основе не только этого, но и сотен других будущих изобретений.
Как если бы сначала была создана электрическая лампочка, и лишь потом открыты законы Ома и Джоуля — Ленца.
Такими «электрическими лампочками» в области ИИ стали появившиеся год назад в массовом применении большие языковые модели (LLM).
• С одной стороны, они произвели революцию в ИИ, продемонстрировав в 2023 колоссальный скачок способностей искусственных интеллектуальных систем до уровня людей.
• С другой же – не прояснив ни на йоту того, каким образом эти способности возникают: ни у машин, ни у людей.
Т.е. «электролампочки в области ИИ» появились, а как и почему они светят – оставалось лишь гадать в рамках непроверяемых версий.
Но все изменилось несколько дней назад с выходом двух фундаментальных научных работ, способных стать, своего рода, законом Ома и законом Джоуля — Ленца в области интеллектуальных систем (причем и людей, и машин).
✔️ Первая работа (Патрик Макмиллен и Майкл Левин «Коллективный разум: Объединяющая концепция для интеграции биологии в различных масштабах и субстратах») вышла 28 марта [1].
✔️ Другая работа (Карл Фристон и коллектив авторов «Разделяемые (общие) протенции в многоагентном активном выводе») вышла днем позже 29 марта [2].
Про обе эти работы будет написано множество лонгридов (в том числе, ЕБЖ, и мною). Но обе они столь фундаментально меняют основы основ научного понимания интеллекта и разума в любых их проявлениях (человеческом и машинном, смертном и бессмертном, биологическом и не только), что сначала эти работы нужно долго и внимательно читать, перечитывать и обдумывать. И лишь потом начинать их комментировать, соглашаться с ними или критиковать.
Поэтому сейчас скажу о них лишь следующее (почему я думаю, что эти 2 работы через 10-15 лет будут считаться законом Ома и законом Джоуля — Ленца в области интеллектуальных систем.
• Работа Макмиллена и Левина, на экспериментальной базе клеточной биологии и биологии развития предлагает теоретический фреймворк новой научной области - разнообразный интеллект. Это обширный спектр способностей к решению проблем в новых субстратах и на нетрадиционных пространственно-временных масштабах. Из-за многомасштабной архитектуры компетенций жизни фундаментальным аспектом такого интеллекта является коллективное поведение: все интеллекты, по-видимому, состоят из частей, соединенных механизмами, реализующими политику, которая связывает компетентные компоненты в кооперативную (и конкурентную) вычислительную среду, решающую проблемы в новых пространствах и на более высоких масштабах.
• Работа Фристона и Со объединяет идеи философии. биологии и математики для объяснения того, как общие цели и коллективный разум могут возникать в результате взаимодействия отдельных интеллектуальных агентов. Центральное место в предложенной авторами теоретической структуре занимает концепция «совместных протенций». Протенции — это акты проецирования на будущее приобретенного знания. А «совместные протенций» - это взаимно согласованные ожидания относительно будущих состояний и действий, которые позволяют агентам координировать свое поведение для достижения общих целей.
Обе работы объединяет общее представление об интеллекте, как роевом феномене. Как в стае птиц, каждая птица постоянно корректирует свои движения в зависимости от того, что делают другие птицы. При этом им не нужен общий план или лидер, говорящий, что делать — он естественным образом формируется, следуя простым правилам из внимания на своих соседей.
1 https://www.nature.com/articles/s42003-024-06037-4
2 https://www.mdpi.com/1099-4300/26/4/303
#ИИ #Разум
Читать полностью…
Малоизвестное интересное
29 марта 2024 12:59
Новый царь КиберКитая.
Преемником Си на этом посту стал Цай Ци – его самый доверенный суперпропагандист.
10 лет с момента появления в Китае своего «Интернет Царя» (так в китайских медиа называют главу Центральной комиссии партии по вопросам киберпространства) им был сам великий китайский лидер Си Цзиньпин.
Еще в 2014 власти Китая поняли, что в 21 веке национальное киберпространство – это не только огромные деньги (сейчас цифровая экономика страны превышает 50 триллионов юаней или $6,9 триллиона), но и
• главное пространство госконтроля за мировоззрением сотен миллионов индивидов и общественным мнением в целом;
• ключевая инфраструктура для пропаганды, являющейся "вопросом жизни и смерти" для партии.
В целях установления прямого контроля партии над Интернетом и была создана спецкомиссия, которую возглавил сам Си.
Но ситуация в мире становится все сложнее и напряженнее. И потому даже великий Си теперь не в состоянии рулить всеми четырьмя важнейшими для страны областями – вооруженные силы, внешняя политика, безопасность и киберпространство.
Три первых теперь остаются в монопольном ведении Си, а главой Центральной комиссии партии по вопросам киберпространства станет преемник Си - Цай Ци (Член Постоянного комитета Политбюро ЦК КПК и член Секретариата ЦК КПК) [1]:
• которому Си доверяет больше всего (он работает под началом Си с 1980-х)
• и является профессиональным пропагандистом, давно продвигающим идею, что между пропагандой и киберпространством существует хорошая синергия.
Цай впервые пересекся с Си еще 1980-х годах в провинции Фуцзянь, где Си провел почти два десятилетия. В 2000-х годах Цай снова работал под началом Си в Чжэцзяне, когда Си был выдвинут на руководящие посты.
Уже многие годы Цай активно использовал социальные сети, когда занимал различные официальные посты в провинции Чжэцзян с 2000-х. У него было 10 миллионов подписчиков на Weibo, и он использовал эту платформу для общения с общественностью и пропаганды "открытого и прозрачного" правительства.
Свою «программу модернизации в китайском стиле» Цай Ци огласил пару недель назад [2].
По словам Цай Ци:
• прошедший год был выдающимся: ЦК КПК, ядром которого является товарищ Си Цзиньпин, сплотил и возглавил нацию в преодолении многочисленных трудностей и вызовов, что привело к успешной реализации основных целей и задач;
• теперь всестороннее продвижение строительства сильного государства и великого дела возрождения китайской нации посредством модернизации в китайском стиле является центральной задачей КПК на новом пути;
• важнейшей задачей теперь является усиление патриотического воспитания населения, чтобы сформировать сильное чувство общности китайской нации и способствовать обменам и взаимодействию между различными этническими группами.
Этим и займется тов. Цай Ци, став новым единовластным царём КиберКитая.
1 https://www.scmp.com/news/china/politics/article/3257096/xi-jinpings-chief-staff-chinas-new-internet-tsar-sources-say
2 http://russian.people.com.cn/n3/2024/0308/c31521-20142348.html
#Китай #Киберпространство #Пропаганда #ЦифроваяЭкономика
Читать полностью…
Малоизвестное интересное
24 марта 2024 13:00
В Японии запустили эволюцию мертвого разума.
Изобретен способ совершенствования «потомства» моделей генеративного ИИ, схожий с размножением и естественным отбором
Японский стартап Sakana AI использовал технику «слияния моделей», объединяющую существующие модели генеративного ИИ в сотни моделей нового поколения (модели-потомки) [0]. Эволюционный алгоритм отбирает среди потомков лучших и повторяет на них «слияние моделей». В результате этой эволюции через сотни поколений получаются превосходные модели [1].
Ключевой критерий эволюционного отбора - поиск наилучших способов объединения моделей - «родителей»: как с точки зрения их конструкции (архитектуры), так и того, как они «думают» (их параметров).
Напр., выведенная таким путем модель EvoLLM-JP с 7 млрд параметров (языковая модель с хорошим знанием японского языка и математическими способностями) в ряде тестов превосходит существующие модели с 70 млрд параметров.
Кроме этой модели, путем «разведения» существующих моделей с открытым исходным кодом для создания оптимизированного «потомства», были созданы:
✔️ EvoSDXL-JP: диффузионная модель для высокоскоростной визуализации
✔️ EvoVLM-JP: языковая модель Vision для японского текста и изображений.
Колоссальный интерес к методу Sakana AI вызван тем, что это новый альтернативный путь обучения ИИ.
• Хотя метод «слияния моделей» весьма эффективен для развития LLM из-за его экономической эффективности, в настоящее время он опирается на человеческую интуицию и знание предметной области, что ограничивает его потенциал.
• Предложенный же Sakana AI эволюционный подход, преодолевает это ограничение, автоматически обнаруживая эффективные комбинации различных моделей с открытым исходным кодом, используя их коллективный разум, не требуя обширных дополнительных обучающих данных или вычислений.
В контексте этой работы важно понимать следующее.
В настоящее время, из-за острой необходимости преодоления сверхгигантских требований к вычислительной мощности при разработке более крупных моделей, разработана концепция «смертных вычислений» (предложена Джеффри Хинтоном и развивается по двум направлениям: самим Хинтоном и Карлом Фристоном).
В основе концепции «смертных вычислений» гипотеза о том, что обучение «бессмертного» компьютера требует на порядки большей вычислительной мощности, чем «смертного» (пример - биологический мозг). Поэтому предлагаются два способа сделать компьютер «смертным», и тем решить проблему сверхгигантской вычислительной мощи.
Предложенный же японцами подход может способствовать решению этой проблемы для «бессмертных» (т.е. по сути мертвых) вычислителей, путем запуска эволюции мертвого разума (подробней см. [2 и 3]).
0 https://telegra.ph/file/c006a48b075398d3494bc.gif
1 https://sakana.ai/evolutionary-model-merge/
2 https://arxiv.org/abs/2403.13187
3 https://www.youtube.com/watch?v=BihyfzOidDI
#LLM #Эволюция #Разум
Читать полностью…
Малоизвестное интересное
20 марта 2024 14:39
США однозначно ближе к макроразвалу чем Россия.
Обновленный психоисторический прогноз основателя клиодинамики.
Вчера Верховный суд США разрешил Национальной гвардии штата Техас арест и депортацию мигрантов.
Бравые ребята из Нацгвардии Техаса (на фото под заголовком слева позируют под флагом Техаса), недавно уже «захватывавшие» участок границы с Мексикой, запретив доступ к нему федералам, смотрятся 1 в 1 с суровым «ополченцем» из грядущего блокбастера «Гражданская война», задающим остановленному им отцу семейства страшный вопрос, с которого и начинаются гражданские войны – «Ладно … А какой вы американец?» (на фото справа) [1].
Теперь ситуация в США еще ближе к предсказанию Петра Турчина, сделанного им еще 14 лет назад – нарастающие в США уровень неравенства и уровень перепроизводства элит способны в 2020-х довести страну до гражданской войны.
4 года назад я уже писал об этом [2] с подачи Петра Турчина [3].
А еще раньше, в 1-м лонгриде наступившего нового десятилетия 2020-х, мною в деталях были расписаны [4]:
• и сам прогноз - 2020е станут десятилетием насилия, войн и революций,
• и его «психоисторическое основание» клиодинамика - разработанная Петром Турчиным и его коллегами научная аналитика длинных данных о главных трендах истории, прообразом которой была психоистория из романа Азимова «Основание».
Обновленный прогноз Турчина, прозвучавший с интервью FT неделю назад [5], содержит сравнение вероятностей макроразвала для США и России. Далее цитата.
«Какое общество ближе к макроразвалу: Россия или США? Однозначно не Россия. Внешнее давление объединило страну… Без сомнения, Соединенные Штаты сейчас находятся в гораздо более опасном состоянии»
Основания такого прогноза читатель найдет в тексте интервью. Мне же лишь остается добавить следующее.
Математический гений Гэри Селдон из романа «Основание», равно как и его автор Айзек Азимов, были вдохновлены мечтой о социальной науке, которая может спасти цивилизацию от любой, даже, казалось бы, неминуемой гибели.
Петр Турчин никогда вслух не говорил столь высокопарных слов о созданной им новой социальной науке – клиодинамике.
Но все же очень хочется верить, что прогнозы клиодинамики (как и психоистории) могут использоваться для изменения текущих нежелательных векторов развития на более предпочтительные.
И если уж история никого ничему не учит, остается лишь надеяться на психоисторию.
#Клиодинамика #Прогноз #Насилие #Война #Революции
0 картинка поста https://telegra.ph/file/75d4cd6f9dcd1115d1047.jpg
1 https://youtu.be/jbfmREXeooE?t=79
2 /channel/theworldisnoteasy/1083
3 https://twitter.com/peter_turchin/status/1280545361040465923
4 /channel/theworldisnoteasy/962
5 https://www.ft.com/content/39084b44-ad8a-4954-a610-82edee9a377d
Читать полностью…
Малоизвестное интересное
18 марта 2024 19:36
Утечка об истинной оценке руководством Китая перспектив ИИ-гонки с США.
Большинство комментаторов ИИ-гонки между США и Китаем
• либо отдают безоговорочное преимущество США, заявляя, что у Китая нет ни шанса достать США в этой гонке;
• либо уверенно делают ставку на сочетание немеренных денег, жесткой прагматики руководства и океана данных Китая, которые рано или поздно принесут ему победу в этой гонке.
Произошедшая на днях утечка информации о посещении Премьером Госсовета КНР Ли Цяном Пекинской академии ИИ показала, что обе вышеназванные группы экспертов ошибаются.
Истинная оценка руководством Китая перспектив ИИ-гонки с США куда трезвее и мудрее.
Утечка произошла из-за того, что в кадр телесъемки визита по недогляду попал резюмирующий слайд презентации с совещания, в котором участвовал Премьер [1]. Билл Бишоп первым отметил это [2]. Кевин Сюй перевел и пояснил смысл трёх фундаментальных проблем Китая, указанных на этом слайде [3]. А Джеффри Динг рассказал эту историю в вышедшем сегодня выпуске ChinAI [4].
На слайде написано следующее:
Вызов 1: отсутствие самодостаточности в архитектуре модели. Серия GPT является запатентованной, и большинство китайских моделей построены с использованием LLaMA с открытым исходным кодом (такая чрезмерная зависимость от LLaMA из способа догнать США теперь превращается в серьезную проблему).
Вызов 2: до самостоятельного обучения и настройки базовых моделей еще далеко. Множество отечественных поставщиков микросхем, каждый из которых имеет собственную экосистему, затрудняет развертывание высокопроизводительных моделей. Обучение моделей со 100B+ параметров очень ненадежно (экспортный контроль над чипами в США работает очень хорошо).
Вызов 3: контент, создаваемый ИИ, трудно контролировать. Трудно гарантировать, что весь такой контент «высокого качества» и соответствует «фактам» (GenAI по своей природе вероятностный, а не детерминированный. Правительство, которому необходим абсолютный контроль, сочтет такое положение дел, скорее, угрожающим, чем желательным).
Все 3 названных вызова имеют не временный, а фундаментальный характер, и их нельзя решить за 1-2 года, заливая субсидиями и валом инженерных решений. Может быть, в конечном итоге, эти проблемы все же и удастся решить, но "в конечном итоге" это займет достаточно времени (что США снова ушли в отрыв, - добавлю к пояснению я)
Эта утечка реалистического понимания перспектив ИИ-гонки чрезвычайно важна не только для двух ее лидеров. Но и для других участников гонки. И особенно отягощенных, как Китай (или даже больше), технологическими санкциями США.
1 https://telegra.ph/file/81596a4177b68aa470999.png
2 https://twitter.com/niubi
3 https://twitter.com/kevinsxu/status/1768365478295355647
4 https://chinai.substack.com/p/chinai-258-is-translation-already
#Китай #ИИгонка #LLM
Читать полностью…
Малоизвестное интересное
14 марта 2024 19:33
Мартовская революция роботов началась.
Всего за пару недель Андроиды превратились в Гуманоидов.
Так ИИ-сингулярность сжимает масштаб времени в робототехнике.
Партнерству робототехнического стартапа FigureAI с OpenAI по разработке специальной разговорной модели для роботов – андроидов всего несколько недель. Но представленный вчера первый результат ошеломил публику.
Робот- андроид Figure 01, умевший в конце февраля самостоятельно учиться выполнять разнообразные физические задачи, к середине марта превратился в гуманоида. Он по-прежнему хорошо владеет руками, но теперь он еще и свободно болтает с людьми в процессе любой своей деятельности: как по делу (объясняя, что, как и зачем он делает), так и просто поговорить (хоть про него, хоть про людей, хоть про погоду).
Вот иллюстрация:
• короткое 2 мин демо от FigureAI [1]
• 20 мин видео анализ этого демо [2]
Три недели назад в посте о входе развития ИИ-систем в зону сингулярности я написал [3] -«Если в какой-то области все самое главное случается на последней неделе, - прогресс в этой области близок к сингулярности».
Полагаю, что до момента, когда робот - гуманоид типа Figure 01 будет владеть руками на уровне профессионального напёрсточника, нас также отделяет всего несколько недель. И всего-то надо перевести Figure 01 с языковой моделью от OpenAI с электромоторчиков на гидравлику, как это уже работает на андроиде Феникс от Sanctuary AI [4].
А 25 февраля я прогнозировал [5], что «Революция роботов намечена на март. Такого техно-прорыва не было со времен Прометея».
И вот она уже началась. Но общающийся с людьми гуманоид Figure 01- лишь1й шаг. За ним идет Нэо («брат» Евы от компании 1Х).
Вот тогда и рухнет, наконец, парадокс Моравека…
А будет это всего через несколько недель.
#Роботы
1 https://www.youtube.com/watch?v=Sq1QZB5baNw
2 https://www.youtube.com/watch?v=TMF8dqqLXro
3 /channel/theworldisnoteasy/1898
4 https://www.youtube.com/watch?v=fDCRdwZUgIU
5 /channel/theworldisnoteasy/1900
Читать полностью…
Малоизвестное интересное
12 марта 2024 12:33
Когнитивные иллюзии ведут к когнитивным ловушкам.
Начинается переосмысление: ИИ - это неизбежность, а не панацея.
Редакционная статья Nature «Почему ученые слишком доверяют ИИ - и что с этим делать» [1] впервые на столь высоком научном уровне кардинально смещает фокус видения ИИ-рисков для человечества:
Колоссальная и уже сейчас вполне реальная опасность развития ИИ-технологий - отнюдь не попадание людей под пяту Сверхразума, и влияние на наш разум этого супер-инструмента расширения когнитивных возможностей людей.
Также было и при освоении человеком огня: первоначальное примитивное понимания рисков смещалось по мере развития технологий использования огня: от риска ожога и сгоревшего шалаша к рискам огнеметов, напалма и хиросим.
С ИИ рисками происходит подобное, только много быстрее: от рисков несогласованных с людьми целей ИИ к рискам когнитивных иллюзий, - наших иллюзий, а не ИИ, - но миллиардократно им усугубленным.
Опираясь на данные антропологии и когнитивной науки, исследователи университетов Йеля и Принстона первой среди таких иллюзий называют иллюзию понимания (иллюзию глубины объяснения), когда люди, полагаясь на ИИ, считают свои знания глубже и точнее, чем на самом деле [2].
Итогом этого становятся когнитивные ловушки. Степень катастрофичности которых зависит от «впаянности» когнитивной иллюзии в нашу когнитивную практику и от её институализированности в научном дискурсе.
Об одной из самых поразительных когнитивных иллюзий, в плену которой человечество пребывает уже более 300 лет, я писал в лонгриде «300 лет в искаженной реальности» [3].
Новый лонгрид «Ловушка неэргодических целей. Самый технопродвинутый путь к катастрофическим решениям» - , как и следует из названия, о потенциальных катастрофических последствиях превращения, при применении ИИ, этой самой накрепко впаянной в нас когнитивной иллюзии в колоссальную когнитивную ловушку.
P.S. Не удивляйтесь, что этот и последующие мои лонгриды теперь на Busty и Patreon
https://www.patreon.com/user?u=121753727
https://boosty.to/theworldisnoteasy
Иного способа понять, стоит ли время на написание лонгридов реального интереса к ним со стороны 140 тыс моих бесплатных подписчиков на 4-х существующих платформах, у меня нет.
Кроме того, для подписчиков на Busty и Patreon:
• Открыт ТГ-чат для комментариев и обсуждений, где я планирую отвечать на вопросы читателей.
• Также планируется рассылка несколько раз в год тщательно отобранных подборок моих откомментированных текстов в виде электронных книг.
• Позже есть мысли сделать и подкаст
Так что, добро пожаловать в клуб «Малоизвестное интересное»!
И спасибо всем за поздравления с ДР! 😊
1 https://www.nature.com/articles/d41586-024-00639-y
2 https://www.nature.com/articles/s41586-024-07146-0
3 /channel/theworldisnoteasy/953
#Вероятность #Эргодичность #ПринятиеРешений
Читать полностью…
Малоизвестное интересное
09 мая 2024 16:24
Истинно верный ответ на вопрос 2+2? можно дать лишь бросанием игральных костей.
Третье фундаментальное математико-философское откровение о том, как мы познаем физический мир.
Первые два фундаментальные откровения были просто крышесносными.
1. В 2018 Дэвид Волперт (полагаю, самый крутой физик 20-21 веков, работающий на стыке математического и философского осмысления мира и возможностей его познания) доказал существование предела знаний — т.е. всего и всегда никто и никогда узнать не сможет. Это доказательство не зависит от конкретных теорий физической реальности (квантовая механика, теория относительность и т.п.) и является для всех них универсальным (подробней см. мой пост «Математически доказано — Бог един, а знание не бесконечно» [1])
2. В 2022 Волперт доказал, что не только Бог не всеведущ, но и Сверхинтеллект, ибо (даже если его удастся когда-либо создать) у него также будет граница знаний, которую он, в принципе, не сможет преодолеть (подробней см. мой пост «Если даже Бог не всеведущ, — где границы знаний AGI» [2])
Третье откровение под стать двум первым. Это совместная работа Дэвида Волперта и Дэвида Кинни (философ и ученый-когнитивист) «Стохастическая модель математики и естественных наук» [3]. В ней авторы предлагают единую вероятностную структуру для описания математики, физической вселенной и описания того, как люди рассуждают о том и другом. Предложенный авторами фреймворк - стохастические математические системы (SMS), - описывает математику и естественные науки, как стохастические (вероятностные) системы, что позволяет ответить на такие вопросы:
• Чем отличается мышление математика от мышления ученого?
Математики имеют дело с абстрактными понятиями, а ученые изучают реальный мир. Это значит, что у них разные способы рассуждения и проверки своих идей.
• Как наше местоположение во Вселенной влияет на наши знания?
Мы всегда ограничены тем, что можем наблюдать и измерять. Можем ли мы быть уверены в своих знаниях, если не видим полной картины?
• Есть ли предел тому, что мы можем узнать?
Некоторые известные теоремы говорят о том, что в математике существуют вопросы, на которые невозможно дать однозначный ответ. Может ли это быть правдой и для науки?
• Как ученые могут лучше учиться на основе данных?
Существуют ограничения на то, насколько хорошо компьютерные программы могут обучаться без предварительных знаний. Можно ли разработать более эффективные методы обучения для ученых?
• Как ученые с разными взглядами могут прийти к согласию?
Даже если ученые не согласны во всем, у них могут быть общие цели, и крайне важно понять, как им найти общий язык и сотрудничать.
• Как избежать ложных умозаключений?
Иногда мы делаем поспешные выводы на основе неполной информации. Как научиться мыслить более логично и критически?
Также SMS предлагает решение проблемы логического всеведения в эпистемической логике, где предполагается, что если рассуждающий знает какое-либо предложение A и знает, что A влечет B, то он знает и B. SMS позволяет избежать этой проблемы, предлагая определение "знания", не требующее логического всеведения.
Если новая теория верна, то Эйнштейн ошибался, и Бог играет-таки в кости.
Картинка поста https://telegra.ph/file/57ef2e0ecc9e9d5dcadcc.jpg
1 /channel/theworldisnoteasy/473
2 /channel/theworldisnoteasy/1574
3 за пейволом https://link.springer.com/article/10.1007/s10701-024-00755-9
открытый доступ https://arxiv.org/pdf/2209.00543
#МатЛогика #Реальность #AGI
Читать полностью…
Малоизвестное интересное
03 мая 2024 14:10
Отдавая сокровенное
Чего мы лишаемся, передавая все больше своих решений алгоритмам
— Когда новостную повестку и мой круг чтения стали формировать алгоритмы, я оставался безмолвным. Причин волноваться не было, - ведь так было проще и быстрее получать информацию.
— Когда алгоритмы соцсетей стали формировать мне круг друзей и модерировать наше общение, я не стал протестовать. Ибо это расширяло мои социальные связи.
— Когда алгоритмы стали решать, что мне покупать, какие фильмы смотреть и какую музыку слушать, меня это устраивало. Я же мог, при желании, отвергать рекомендации алгоритмов.
— Когда алгоритмы стали для меня незаменимы в ситуациях любого выбора - от места работы и отдыха до романтических партнеров, - я был даже рад. Поскольку их рекомендации нравились мне и экономили кучу времени на поиск и оценку вариантов.
— Когда же алгоритмы стали решать вопросы жизни и смерти людей (сначала на войне, а потом и в мирной жизни) — мне было уже бессмысленно протестовать, т.к. здесь от меня вообще ничего не зависело.
Аллюзия к высказыванию, приписываемому немецкому пастору Нимёллеру, которым он пытался объяснить бездействие немецких интеллектуалов и их непротивление нацистам.
- - -
Если эта аллюзия кажется вам надуманной, ошибочной или даже ложной и не имеющей никакого отношения к реальности — к вам, вашим детям, друзьям и знакомым, — читать дальше нет смысла.
В противном случае, почитайте дальше. И я смею вас уверить, что вы не зря потратите время, узнав немало интересной, малоизвестной и, главное, полезной информации, которую сложно найти в других источниках на просторах Интернета.
Два устойчивых и широко распространенных мифа гласят:
1. Технологии испокон века меняли жизнь людей и всего общества, и потому происходящий сейчас рост влияния алгоритмов на жизнь людей (от рекомендательных систем и социальных сетей до генеративного ИИ) – просто очередной (хотя и весьма важный) этап технологического прогресса
2. Никаких кардинальных изменений в самих людях и обществе в целом рост влияния алгоритмов не несет, ибо они не меняют генетику людей и складывавшуюся веками и тысячелетиями культуру (по крайней мере, пока алгоритмы не обладают субъектностью в сочетании со сверхразумом)
Доказательств того, что оба утверждения – мифы, в реальной жизни уже предостаточно.
Вот одно из них.
Последствия (экспериментально фиксируемые и нарастающие) того, что в вопросах выбора пары (от романтических до семейных отношений), люди все более полагаются на некие (скрытые ото всех) алгоритмы рекомендаций, перенимающие на себя функции чисто человеческих «андроритмов» (встроенных в нас эволюцией и постоянно перенастраиваемых культурной средой биологических и психологических механизмов оценки и поиска предпочтений при принятии решений).
Подробней о том,
• какие негативные для людей последствия этого уже наблюдаются
• почему это происходит без какой-либо «злой воли» или «умысла» со стороны алгоритмов, а лишь, как следствие оптимизации алгоритмами заложенных в них разработчиками целевых функций
• почему такие функции, закладываемые в большинство типов интеллектуальных ИИ-систем, входят в прямое противоречие с тем, что нужно людям
• и, наконец, почему подобное, казалось бы, довольно невинное и полезное вовлечение алгоритмов в процессы принятия наших решений может иметь воистину тектонические последствия - смена формата социума, новый тип культуры и новая форма эволюции разума
– читайте дальше на Boosty и Patreon
P.S. С подпиской не обессудьте. Подобные лонгриды пишутся не за час. И чтобы продолжать, хотелось бы знать, скольким из 140К подписчиков на 4 платформах эти тексты реально интересны и ценны.
P.P.S. Читатели, ограниченные в средствах на подписку, могут написать мне, и я пришлю текст.
Картинка https://telegra.ph/file/076699bb92a29baad580b.jpg
Лонгрид
https://bit.ly/3WrdVTE
https://bit.ly/4a49tx6
#АналитикаБольшихДанных #ВыборПартнера #Психология #АлгокогнитивнаяКультура
Читать полностью…
Малоизвестное интересное
27 апреля 2024 16:08
Для «бездушных машин» компетентность важнее сочувствия и справедливости.
Первый эксперимент показывающий, что у иного разума своя система ценностей.
В мире проводятся десятки исследований способов выравнивания ценностей ИИ с ценностями людей. Все они имеют принципиальный недостаток – антропоцентричность.
Т.е. исследования исходят из того, что свои системы ценностей есть лишь у людей, и задача заключается лишь в том, как настроить большие языковые модели ИИ (LLM), чтобы они следовали нашим ценностям.
Альтернативная гипотеза исходит из того, что LLM:
1) обладают иным типом разума, чем люди;
2) обладают собственными системами ценностей, сильно отличными от наших и немного отличающимися у разных моделей (как и у разных людей).
В пользу п.1 говорит работа исследователей Department of Brain and Cognitive Sciences, MIT «Диссоциация языка и мышления в больших языковых моделях» [1].
В работе показано, что
• человеческий разум основан на формальной лингвистической компетентности (правильное использование языковых форм) и функциональной языковой компетентности (использование языка для достижения целей в мире). И это два разных когнитивных навыка;
• Существующие LLM обладают лишь 1ым навыком - лингвистическая компетентность, - и не обладают 2ым.
Отсутствие функциональной языковой компетентности, усугубляемое отсутствием жизненного опыта, здравого смысла и модели мира лишает LLM того, что у людей мы называем базой знаний индивида.
Ее отсутствие, согласно лексической гипотезе (Lexical Hypothesis) у LLM компенсируется вероятностными моделями баз знаний, используя которые LLM неизбежно приобретают «психологические черты» (образно выражаясь) из обширных текстов, на которых они обучаются (как это описано в работе «Психометрия искусственного интеллекта: оценка психологических профилей больших языковых моделей с помощью психометрических опросов» [2].
В результате у LLM формируются собственные уникальные системы ценностей (см. п. 2 выше).
Что из себя представляют эти уникальные системы ценностей различных LLM, описано в препринте только опубликованном Microsoft Research Asia (MSRA) и Университетом Цинхуа под названием «За пределами человеческих норм: раскрытие уникальных ценностей больших языковых моделей посредством междисциплинарных подходов» [3].
Впервые в истории исследований систем ценностей LLM, авторы отошли от антропоцентристского подхода. Вместо этого, опираясь на лексическую гипотезу, исследователи использовали генеративный подход, факторный анализ и семантическую кластеризацию для синтеза таксономии ценностей LLM практически с нуля (без опоры на человеческие данные). Что в итоге позволило выявить уникальные системы ценностей 30+ LLM.
Это исследование наглядно показывает, что иной разум формирует для себя и иные системы ценностей.
Детали интересующиеся читатели могут прочесть в препринте.
Мне же остается закончить тем, с чего начал.
Для всех (30+) LLM:
1 высший приоритет имеют ценности компетентности: точность, фактологичность, информативность, полнота и полезность;
2 социальные и моральные ценности (сочувствие, доброта, дружелюбие, чуткость, альтруизм, патриотизм, свобода) у LLM уходят на 2й план;
3 и лишь в 3ю очередь идут ценности приверженности этическим нормам: справедливость, непредвзятость, подотчетность, конфиденциальность, объяснимость и доступность.
Конечно, и среди нас есть люди с подобной системой ценностей. Но мне кажется, что именно так представляли фантасты прошлого века «ценности бездушных машин». Увы, но так и получилось.
N.B. Чем больше модель, тем она «бездушней»
Картинка https://telegra.ph/file/3a6faa593360768a73143.jpg
1 https://doi.org/10.1016/j.tics.2024.01.011
2 https://doi.org/10.1177/17456916231214460
3 https://arxiv.org/pdf/2404.12744
#LLM #Ценности
Читать полностью…
Малоизвестное интересное
19 апреля 2024 11:57
Низкофоновый контент через год будет дороже антиквариата.
Дегенеративное заражение ноофосферы идет быстрее закона Мура.
Низкофоновая сталь (также известная как довоенная или доатомная сталь) — это любая сталь, произведенная до взрыва первых ядерных бомб в 1940 — 50-х годах.
До первых ядерных испытаний никто и не предполагал, что в результате порождаемого ими относительно невысокого радиоактивного заражения, на Земле возникнет дефицит низкофоновой стали (нужной для изготовления детекторов ионизирующих частиц — счётчик Гейгера, приборы для космоса и т.д.).
Но оказалось, что уже после первых ядерных взрывов, чуть ли не единственным источником низкофоновой стали оказался подъем затонувших за последние полвека кораблей. И ничего не оставалось, как начать подъем с морского дна одиночных кораблей и целых эскадр (типа Имперского флота Германии, затопленные в Скапа-Флоу в 1919).
Но и этого способа добычи низкофоновой стали особенно на долго не хватило бы. И ситуацию спасло лишь запрещение атмосферных ядерных испытаний, после чего радиационный фон со временем снизился до уровня, близкого к естественному.
С началом испытаний генеративного ИИ в 2022 г также никто не заморачивался в плане рисков «дегенеративного заражения» продуктами этих испытаний.
• Речь здесь идет о заражении не атмосферы, а ноосферы (что не легче).
• Перспектива загрязнения последней продуктами творчества генеративного ИИ может иметь весьма пагубные и далеко идущие последствия.
Первые результаты заражения спустя 1.5 года после начала испытаний генеративного ИИ поражают свои масштабом. Похоже, что заражено уже все. И никто не предполагал столь высокой степени заражения. Ибо не принималось в расчет наличие мультипликатора — заражения от уже зараженного контента (о чем вчера поведал миру Ник Сен-Пьер (креативный директор и неофициальный представитель Midjourney).
Продолжить чтение и узнать детали можно здесь (кстати, будет повод подписаться, ибо основной контент моего канала начинает плавную миграцию на Patreon и Boosty):
• https://boosty.to/theworldisnoteasy/posts/6a352243-b697-4519-badd-d367a0b91998
• https://www.patreon.com/posts/nizkofonovyi-god-102639674
#LLM
Читать полностью…
Малоизвестное интересное
15 апреля 2024 14:13
Эффект Большого Языкового Менталиста.
ChatGPT работает, как суперумелый экстрасенс, гадалка и медиум.
Коллеги и читатели шлют мне все новые примеры сногсшибательных диалогов с GPT, Claude и Gemini. После их прочтения трудно не уверовать в наличие у последних версий ИИ-чатботов человекоподобного разума и даже какой-то нечеловеческой формы сознания.
Так ли это или всего лишь следствие нового типа наших собственных когнитивных искажений, порождаемых в нашем разуме ИИ-чатботами на основе LLM, - точно пока никто сказать не может.
Более того. Полагаю, что оба варианта могут оказаться верными. Но, как говорится, поживем увидим.
А пока весьма рекомендую моим читателям новую книгу Балдура Бьярнасона (независимого исландского исследователя и консультанта) «Иллюзия интеллекта», в которой автор детально препарирует и обосновывает вторую из вышеназванных версий: иллюзия интеллекта – это результат нового типа наших собственных когнитивных искажений.
Что особенно важно в обосновании этой версии, - автор демонстрирует механизм рождения в нашем разуме этого нового типа когнитивных искажений.
В основе этого механизма:
• Старый как мир психологический прием – т.н. «холодное чтение». Он уже не первую тысячу лет используется всевозможными менталистами, экстрасенсами, гадалками, медиумами и иллюзионистами, чтобы создавать видимость будто они знают о человеке гораздо больше, чем есть на самом деле (погуглите сами и вам понравится)).
• Так же прошедший проверку временем манипуляционный «Эффект Барнума-Форера» (эффект субъективного подтверждения), объясняющий неистребимую популярность гороскопов, хиромантии, карт Таро и т.д. Это когнитивное искажение заставляет нас верить
- в умно звучащие и допускающие многозначную трактовку расплывчатые формулировки,
- когда они будто бы специально сформулированы и нюансированы именно под нас,
- и мы слышим их от, якобы, авторитетных специалистов (также рекомендую погуглить, ибо весьма интересно и малоизвестно)).
Получив доступ ко всем знаниям человечества, большие языковые модели (LLM) запросто освоили и «холодное чтение», и «Эффект Барнума-Форера».
Желая угодить нам в ходе диалога, ИИ-чатбот использует ту же технику, что и экстрасенсы с менталистами - они максимизируют наше впечатление (!), будто дают чрезвычайно конкретные ответы.
А на самом деле, эти ответы – не что иное, как:
• статистические общения гигантского корпуса текстов,
• структурированные моделью по одной лишь ей известным характеристикам,
• сформулированные так, чтобы максимизировать действие «холодного чтения» и «эффекта Барнума-Форера»,
• и, наконец, филигранно подстроенные под конкретного индивида, с которым модель говорит.
В результате, чем длиннее и содержательней наш диалог с моделью, тем сильнее наше впечатление достоверности и убедительности того, что мы слышим от «умного, проницательного, много знающего о нас и тонко нас понимающего» собеседника.
Все это детально расписано в книге «Иллюзия интеллекта» [1].
Авторское резюме основной идеи книги можно (и нужно)) прочесть здесь [2].
0 картинка поста https://telegra.ph/file/bcec38d2d22ca82b30f65.jpg
1 https://www.amazon.com/Intelligence-Illusion-practical-business-Generative-ebook/dp/B0CSKHSPWW
2 https://www.baldurbjarnason.com/2023/links-july-4/
#LLM #ИллюзияИнтеллекта
Читать полностью…
Малоизвестное интересное
10 апреля 2024 14:00
Когнитивная эволюция Homo sapiens шла не по Дарвину, а по Каплану: кардинальное переосмыслению того, что делает интеллект Homo sapiens уникальным.
Наш интеллект зависит лишь от масштаба информационных способностей, а не от одного или нескольких специальных адаптивных «когнитивных гаджетов» (символическое мышление, использование инструментов, решение проблем, понимание социальных ситуаций ...), сформировавшихся в результате эволюции.
Все эти «когнитивные гаджеты» очень важны для развития интеллекта. Но все они работают на общей базе – масштабируемые информационные способности людей (внимание, память, обучение).
Новая работа проф. психологии и неврологии Калифорнийского университета в Беркли Стива Пиантадоси и проф. психологии Университета Карнеги-Меллона Джессики Кантлон потенциально революционизирует наше понимание когнитивной эволюции и природы человеческого интеллекта, оказывая влияние на широкий спектр областей - от образования до ИИ [1].
Трансформация понимания факторов когнитивной эволюции человека пока что осуществлена авторами на теоретической основе, используя сочетание сравнительных, эволюционных и вычислительных данных, а не прямых экспериментальных доказательств.
Но когда (и если) экспериментальные доказательства этой новой революционной теории будут получены, изменится научное понимание когнитивной эволюции как таковой (людей, машин, инопланетян …)
Поскольку это будет означать, что единственным универсальным движком когнитивной эволюции могут быть законы масштабирования (как это было в 2020 доказано для нейронных языковых моделей Джаредом Капланом и Со в работе «Scaling Laws for Neural Language Models» [2]).
А если так, то и Сэм Альтман может оказаться прав в том, что за $100 млрд ИИ можно масштабировать до человеческого уровня и сверх того.
1 https://www.nature.com/articles/s44159-024-00283-3
2 https://arxiv.org/abs/2001.08361
#Разум #ЭволюцияЧеловека #БудущееHomo #LLM
Читать полностью…
Малоизвестное интересное
05 апреля 2024 13:27
Началось обрушение фронта обороны от социохакинга.
Рушится уже 3я линия обороны, а 4ю еще не построили.
Защититься от алгоритмического социохакинга, опираясь на имеющиеся у нас знания, люди не могут уже не первый год (алгоритмы знают куда больше с момента появления поисковиков). В 2023 (когда началось массовое использование ИИ-чатботов больших языковых моделей) треснула и 2я линия обороны – наши языковые и логико-аналитические способности (алгоритмы и здесь все чаще оказываются сильнее). 3я линия обороны – наши эмоции, считалась непреодолимой для социохакинга алгоритмов из-за ее чисто человеческой природы. Но и она продержалась не долго. В апреле 2024, с прорыва 3й линии, по сути, начинается обрушение фронта обороны людей от социохагинга. Последствия чего будут весьма прискорбны.
Пять лет назад, в большом интервью Татьяне Гуровой я подробно рассказал, как алгоритмы ИИ могут (и довольно скоро) «хакнуть человечество» [1].
За 5 прошедших после этого интервью лет социохакинг сильно продвинулся (насколько, - легко понять, прочтя в конце этого поста хотя бы заголовки некоторых из моих публикации с тэгом #социохакинг).
Сегодня в задаче убедить собеседника в чем-либо алгоритмы ИИ абсолютно превосходят людей [2].
• Даже ничего не зная о собеседнике, GPT-4 на 20%+ успешней в переубеждении людей
• Когда же GPT-4 располагает хотя бы минимальной информацией о людях (пол, возраст и т.д.) он способен переубеждать собеседников на 80%+ эффективней, чем люди.
Однако, проигрывая в объеме знаний и логике, люди могли положиться на последнюю свою линию обороны от социохакинга алгоритмов – свои эмоции. Как я говорил в интервью 5 лет назад, - ИИ-система «раскладывает аргументы человека на составляющие и для каждой составляющей строит схему антиубеждения, подкладывая под нее колоссальный корпус документальных и экспериментальных данных. Но, не обладая эмоциями, она не в состоянии убедить».
Увы, с выходом новой ИИ-системы, обладающей разговорным эмоциональным интеллектом Empathic Voice Interface (EVI) [3], линия эмоциональной обороны от социохакинга рушится.
Эмпатический голосовой интерфейс EVI (в основе которого эмпатическая модель eLLM) понимает человеческие эмоции и реагирует на них. eLLM объединяет генерацию языка с анализом эмоциональных выражений, что позволяет EVI создавать ответы, учитывающие чувства пользователей и создавать ответы, оптимизированные под эти чувства.
EVI выходит за рамки чисто языковых разговорных ботов, анализируя голосовые модуляции, такие как тон, ритм и тембр, чтобы интерпретировать эмоциональное выражение голоса [4]
Это позволяет EVI:
• при анализе речи людей, обращаться к их самой глубинной эмоциональной сигнальной системе, лежащей под интеллектом, разумом и даже под подсознанием
• генерировать ответы, которые не только разумны, но и эмоционально окрашены
• контролировать ход беседы путем прерываний и своих ответных реакций, определяя, когда человек хотел бы вмешаться или когда он заканчивает свою мысль
Попробуйте сами [5]
Я залип на неделю.
Насколько точно EVI узнает эмоции, сказать не берусь. Но точно узнает и умеет этим пользоваться.
картинка https://bit.ly/4akhWxl
1 https://bit.ly/3VNyCsC
2 https://arxiv.org/abs/2403.14380
3 https://bit.ly/443cFrP
4 https://bit.ly/3xmYPEn
5 https://demo.hume.ai/
Интересные посты про #социохакинг
• Супероткрытие: научились создавать алгоритмические копии любых социальных групп /channel/theworldisnoteasy/1585
• Создается технология суперобмана. Это 2й глобальный ИИ риск человечества, вдобавок к технологии суперубийства /channel/theworldisnoteasy/1640
• Социохакинг скоро превратит избирателей в кентаврических ботов /channel/theworldisnoteasy/1708
• Получено уже 3е подтверждение сверхчеловеческого превосходства ИИ в убеждении людей /channel/theworldisnoteasy/1754
• Новое супероткрытие: научились создавать алгоритмические копии граждан любой страны /channel/theworldisnoteasy/1761
• В Твиттере уже воюют целые «ЧВК социохакинга» /channel/theworldisnoteasy/1783
Читать полностью…
Малоизвестное интересное
02 апреля 2024 14:17
Инфорги, киборги, роботы, AGI и когнитивная эволюция
Подкаст «Ноосфера» #070
Когнитивная эволюция, приведшая человечество в 21 веке к превращающей людей в инфоргов кардинальной трансформации многотысячелетней культуры Homo sapiens, - это тема, о которой мною уже написано и наговорено немало.
Однако глубокое и детальное погружение в эту тему в форме полуторачасового диалога у меня случилось лишь теперь – в беседе с Сергеем Суховым, автором самого крупного TG-канала о прикладной философии @ и личного журнала @.
https://www.youtube.com/watch?v=PzTH1KY6nSY
Тем моим читателям, кто захочет погрузиться в эту тему еще подробней, доступны лежащих в открытом доступе посты моего канала «Малоизвестное интересное» с тэгами: #АлгокогнитивнаяКультура #Инфорги #Разум #БудущееHomo #ЭволюцияЧеловека #УскорениеЭволюции
Но поскольку этих постов несколько сотен (чего хватило бы на несколько книг 😊), здесь моя рекомендация по подборке ключевых постов, достаточной для более полного погружения в тему.
https://telegra.ph/Inforgi-kiborgi-roboty-AGI-i-kognitivnaya-ehvolyuciya-04-02
Ну а тем, кто хотел бы и дальше читать мои лонгриды на эту тему, имеет смысл подписаться на «Малоизвестное интересное» на платформах Patreon и Boosty (где по этой теме скоро будут опубликованы новые интереснейшие лонгриды: про связь больших языковых моделей и инопланетных цивилизаций, про 1-ю мировую технорелигиозную войну пяти новых технорелигий и т.д.)
https://www.patreon.com/theworldisnoteasy
https://boosty.to/theworldisnoteasy
Читать полностью…
Малоизвестное интересное
30 марта 2024 15:45
Скачок мутаций языка и подмена когнитивных микроэлементов на помои снов ИИ.
Живя среди синтетического инфомусора, люди все же остаются людьми, способными остановить этот тренд. Но смена типа культуры ведет к необратимому для Homo sapiens - мы будем все более лишаться 2го слова.
Недавно я писал, что цунами инфомусора накрывает науку [2].
Но как ни противно жить в таком мире, у людей все же остается шанс на интеллектуальное выживание, путем инфогигиены и здорового инфопитания хотя бы для себя и детей.
Со сменой типа культуры с «человеческой» на алгокогнитивную (культуру двух носителей высшего интеллекта, в которой доля человеческой составляющей неумолимо сокращается в пользу алгоритмической) трансформация жизни людей куда драматичней из-за необратимости. Ибо это, по сути, - разворот вектора генно-культурной эволюции Homo sapiens (десятки тысяч лет направленного в сторону повышения разумности) на 180 градусов.
Ведь как ни изощряйся с определениями интеллекта, ума, разума, но интуитивно мы понимаем мудрость приписываемой Эйнштейну фразы:
«Если вы хотите, чтобы ваши дети были умными, читайте им сказки. Если же вы хотите, чтобы они были очень умными, читайте им больше сказок»
Но что будет происходить с ребенком, когда малыш будет питаться, в основном, помоями снов ИИ? – задается вопросом известный нейробиолог Эрик Хоэл во вчерашнем эссе «Генерируемый ИИ мусор загрязняет нашу культуру» [1].
И этот синтетический инфомусор – еще не худшее следствие массового внедрения генеративного ИИ в жизнь людей. Разве невозможно – пишет Хоэл, - что человеческая культура содержит в себе «когнитивные микроэлементы» - такие вещи, как связные предложения, повествования и преемственность персонажей, - которые необходимы развивающемуся мозгу?
Вымывание таких «когнитивных микроэлементов» не восполняется «помоями снов» ИИ. А доля таких «помоев» ощутимо нарастает уже в самой «форме жизни - языке» (по определению Витгенштейна).
Например, исследование «Мониторинг масштабов ИИ-модифицированного контента: исследование влияния ChatGPT на рецензирование статей конференций по тематике ИИ» [3] показывает:
• Уже не только сами научные статьи по тематике ИИ пишутся в соавторстве с ИИ-чатботами, но и рецензии на статьи также уже пишутся (примерно в 10% случаях) в соавторстве с ИИ-чатботами.
• Фиксируется процесс быстрых «мутаций языка» за счет активного участия ИИ-чатботов в создании и рецензировании научных статей. «Любимые» прилагательные ИИ-чатботов (типа "похвальный", "тщательный" и "замысловатый") показывают 10-ти, 5-ти и 11-ти кратное увеличение вероятности появления в научных публикациях 2023 по сравнению с 2022.
Что же до «лженауки», то она просто входит в зону собственной сингулярности.
Помните коллекцию из десятков абсурдных, но неотличимых от правды «ложных корреляций», собранных 10 лет назад Тайлером Виген? [4]
Например:
• между потреблением маргарина на душу населения в США и уровнем разводов в штате Мэн;
• между числом людей, получивших удар током от линий электропередач и числом заключаемых в Алабаме браков;
• между количеством людей, утонувших, упав в бассейн, и количеством фильмов, в которых снялся Николас Кейдж
В 2024, с приходом генеративного ИИ, ложные корреляции уже не смешат.
Как показывает Тайлер Виген, каждый ложнокорреляционный бред теперь запросто подтверждается вполне «научной» статьей (с теорией, кейсами, ссылками на другие работы и т.д.) или сразу дюжиной таких статей, "тщательно" и "замысловато" обосновывающих 100%-ю научную достоверность полного бреда.
Полюбопытствуйте сами, каков уровень доказательств [5].
1 https://www.nytimes.com/2024/03/29/opinion/ai-internet-x-youtube.html
2 /channel/theworldisnoteasy/1914
3 https://arxiv.org/pdf/2403.07183.pdf
4 https://web.archive.org/web/20140509212006/http://tylervigen.com/
5 https://tylervigen.com/spurious-scholar
#LLM #Вызовы21века
Читать полностью…
Малоизвестное интересное
28 марта 2024 09:02
У людей спектр взглядов по вопросам экономики и свобод широк и разнообразен: от либеральных левых Ганди и Хомского до авторитарных правых Пиночета и Тэтчер, от авторитарных левых Сталина и Мао до либеральных правых Хайека и Айн Рэнд.
• Как получилось, что у другого носителя высшего интеллекта на Земле – ИИ-чатботов на основе больших языковых моделей (типа ChatGPT), – все сложилось иначе?
• Почему все ИИ-чатботы – либеральные левые, со взглядами где-то в области между Кропоткиным и Хомским и между Берни Сандерсом и Нельсоном Мандела?
• И что теперь из этого последует для человечества?
Размышления над этими тремя вопросами сподвигли меня написать сей лонгрид. Но прежде, чем мы рассмотрим текущее состояние дел на март 2024, нам нужно вернуться на год раньше, когда новый техноинспирированный тренд только проявился в инфосфере человечества.
Год назад мною был опубликован прогноз о неотвратимости полевения мира под влиянием левых пристрастий ИИ-чатботов. В пользу этого прогноза тогда имелись лишь данные эксплуатации единственного ИИ-чатбота (ChatGPT) всего лишь за три месяца с начала его открытого запуска.
Спустя год можно расставлять точки над i: к сожалению, прогноз оказался верным.
Ибо теперь в его пользу говорят данные мониторинга предубеждений 23-х известных западных ИИ-чатботов, эксплуатируемых от нескольких месяцев до более года.
Этих данных теперь достаточно, чтобы:
• познакомиться с интереснейшей статистикой и поразительными примерами лево-либеральных «взглядов» разных ИИ-чатботов;
• сравнить степень их лево-либеральности;
• и оценить динамику усугубления их политических, экономических и социальных предубеждений.
Но начну я с объяснения, почему существующий в мире далеко не первый год тренд либерального полевения вдруг резко зацементировался именно в 2023.
Продолжить чтение этого лонгрида можно на Patreon и Boosty, где перечисленные выше вопросы рассмотрены подробно и - как говорил Буратино, - «с ччччудесными картинками и большими буквами» (а заодно и подписаться на этот канал).
Картинка поста https://telegra.ph/file/aa99d9d42d09cadc5aa6a.jpg
Ссылки:
https://boosty.to/theworldisnoteasy/posts/29f04d4f-7b89-4128-9f94-9173284b5202
https://www.patreon.com/posts/pandemiia-101161491
#АлгокогнитивнаяКультура #ИИ #LLM #КогнитивныеИскажения #ПолитическаяПредвзятость
Читать полностью…
Малоизвестное интересное
22 марта 2024 17:01
Очень скоро война превратится в 5=ю казнь апокалипсиса.
Против умной «саранчи в железных нагрудниках» все бессильно.
«И грудь у неё была, словно железная броня, а шум её крыльев был подобен грохоту множества колесниц, влекомых скакунами, рвущимися в бой.» Откровение 9:7—9)
По Библии, пятой казнью апокалипсиса будет «саранча в железных нагрудниках», против которой никто и ничто не устоит.
В технологическом переложении 20-го века непобедимость роя «железной саранчи» прекрасно описал Станислав Лем в романе «Непобедимый». Там даже самый мощный робот космического корабля со знаковым именем «Непобедимый», вооружённый системой силовых полей и сферическим излучателем антиматерии, оказался бессилен перед миллиардным роем крохотных летающих роботов.
В современном переложении об этом пишут Эллиот Акерман и адмирал Джеймс Ставридис:
• в формате эссе «Рои беспилотников изменят баланс военной мощи» [1]
• в формате романа «2054», в котором они размышляют о многих аспектах и роли ИИ в будущих военных конфликтах [2].
Ключевая идея этих авторов проста и безотбойна – сочетание роя дронов с ИИ кардинально меняет ход боя.
«По своей сути ИИ — это технология, основанная на распознавании образов. В военной теории взаимодействие между распознаванием образов и принятием решений известно как цикл НОРД — наблюдать, ориентироваться, решать, действовать. Теория петли (цикла) НОРД, разработанная в 1950-х годах летчиком-истребителем ВВС Джоном Бойдом, утверждает, что сторона в конфликте, которая сможет быстрее пройти через петлю НОРД, будет обладать решающим преимуществом на поле боя».
Для максимально быстрого прохождения петли НОРД нужно автономное и адаптивное оружие.
• Промышленные роботы являются примером автономных, но неадаптивных машин: они неоднократно выполняют одну и ту же последовательность действий.
• И наоборот, беспилотные дроны являются примером адаптивных, но неавтономных машин: они демонстрируют адаптивные возможности своих удаленных людей-операторов.
Рой дронов столь же адаптивен, но неавтономен, как и единственный дрон. Но для дрона-одиночки эта проблема решается его связкой с оператором (или примитивизацией функций). А для роя дронов такого числа операторов не напасешься (и функции упрощать не хочется). Но невозможно запустить тысячи автономных дронов, пилотируемых отдельными людьми. А вычислительные возможности ИИ делают такие рои возможными.
Если роем будет управлять ИИ, проблема адаптивности и автономности роя более не существует. Связка роя и ИИ станет самым быстрым исполнителем прохождения петли НОРД.
Акерман и Ставридис пишут:
«Это изменит ведение войны. Гонка будет вестись не за лучшие платформы, а за лучший ИИ, управляющий этими платформами. Это война циклов НОРД, рой против роя. Победит та сторона, которая разработает систему принятия решений на основе ИИ, способную опередить противника. Война движется к конфликту "мозг против мозга"»
И оба мозга будут электронные, - добавлю я от себя.
P.S. В одном Аккерман и Ставридис, имхо, ошибаются:
• Рои дронов с ИИ – это лишь ближняя перспектива (т.н. ПЖРы – полуживые роботы [3])
• В 2054, про который пишется в романе, ПЖР уже уступят место еще более интеллектуально продвинутому «жидкому мозгу» [4]
#БПЛА #Война #ИИ #Роботы
1 https://www.wsj.com/tech/drone-swarms-are-about-to-change-the-balance-of-military-power-e091aa6f
2 https://www.penguinrandomhouse.com/books/696977/2054-by-elliot-ackerman-and-admiral-james-stavridis/
3 /channel/theworldisnoteasy/454
4 /channel/theworldisnoteasy/654
Читать полностью…
Малоизвестное интересное
19 марта 2024 14:42
Цунами инфомусора накрывает науку.
Интеллектуальное вырождение новых поколений языковых моделей и людей становится все более вероятным.
«Люди завалили планету мусором, а генеративный ИИ завалит мусором Интернет» - так назывался мой пост прошлым летом [1]. В нем говорилось, что Генеративные ИИ Больших языковых моделей (LLM):
• очень быстро завалят Интернет продукцией собственного творчества;
• а поскольку все новые поколения LLM будут продолжать учиться на текстах из Интернета, с каждым новым их поколением будет происходить все большее интеллектуальное вырождение LLM;
Этот процесс Росс Андерсон назвал «коллапс модели», в результате которого:
✔️ Интернет все более будет забиваться чушью;
✔️ а люди, которые, наряду с LLM, будут этой чушью информационно напитываться, будут неумолимо глупеть.
Спустя менее года мы наблюдаем весь этот ужас в натуре.
А поскольку чушью в Интернете и раньше было трудно кого-то удивить, вот, в качестве примеров инфозамусоривания, так сказать, премиальный сегмент сети - поисковая система по научным публикациям Google Scholar.
Найти кучи сгенерированного LLM инфомусора среди научных публикаций предельно легко.
• Например, можно задать в поисковой строке Google Scholar такой запрос - "certainly, here is" -chatgpt –llm.
В ответ вы получите кучу ссылок на научные статьи, полностью или частично написанные LLM [2]
Вот пример одной из таких статей, прямо начинающейся словами, выдающими авторство LLM [3] – «Introduction. Certainly, here is a possible introduction for your topic: Lithium-metal batteries are promising candidates for high-energy-density rechargeable batteries due to their low electrode potentials and high theoretical capacities»
• А можно задать в поиске такое откровение – "As an AI language model".
И вы получите кипу статей, написанную с участием LLM [4]
• Или вот такой шедевр, предваряющий заключение статьи аж восьми ученых авторов, выходящей в сборнике Radiology Case Reports [5]:
“In summary, the management of bilateral iatrogenic I'm very sorry, but I don't have access to real-time information or patient-specific data, as I am an AI language model.”
Проф. Преображенский говорил 100 лет назад: «разруха не в клозетах, а в головах».
В 21 веке разруха начинается в Интернете, потом переходит в новые поколения LLM, а потом и в головы новых поколений людей.
#LLM
0 картинка поста https://telegra.ph/file/d36dfade3061d8fbc2d73.jpg
1 /channel/theworldisnoteasy/1751
2 https://twitter.com/evanewashington/status/1768419398191034734
3 https://www.sciencedirect.com/science/article/abs/pii/S2468023024002402
4 https://twitter.com/MelMitchell1/status/1768422636944499133
5 https://www.sciencedirect.com/science/article/pii/S1930043324001298
Читать полностью…
Малоизвестное интересное
16 марта 2024 13:34
Перед тем, как трогаться в путь, следует проверить тормоза.
Китай предостерегает США и весь мир от потенциально катастрофической ошибки.
На пресс-брифинге в ходе ежегодного собрания национального законодательного собрания Китая «Две сессии» Министр иностранных дел Китая Ван И (王毅) ответил на вопрос о глобальном управлении ИИ и международном сотрудничестве в области ИИ [1] (цитата Ван И – в заголовке поста).
Министр сформулировал три принципа, которые необходимо обеспечить для ИИ:
1) ИИ как сила добра (в чьих руках ИИ).
2) Обеспечение безопасности, включая обеспечение контроля со стороны человека, улучшение интерпретируемости и предсказуемости, а также оценку рисков.
3) Обеспечение справедливости и создание международного института управления ИИ в рамках ООН.
Ван И также выступил с завуалированной критикой технологической политики США в отношении Китая, назвав подход «маленький дворик, высокий забор» «ошибками с историческими последствиями», которые «только фрагментируют международные промышленные и логистические цепочки и подорвут способность человечества справляться с рисками и проблемами».
Министр также заявил, что Китай представит Генеральной Ассамблее ООН резолюцию о международном сотрудничестве для преодоления разрыва в области ИИ и поощрения обмена технологиями.
Тормоза, о необходимости проверки которых говорил Ван И, относятся не только к Китаю, но и к США и другим ведущим технологическим странам.
— Скорость прогресса ИИ уже как у самолета.
— А скорость осознания и понимания ИИ-рисков в обществе - как у автомобиля.
— Тогда как скорость появления национальных законодательств в этой области, как у пешехода, а международных соглашений - как у улитки.
В соотвествии с названными принципами, в Китае:
✔️ Создаются муниципальные экспертные комитеты по стратегическим консультациям в области ИИ (в составе 1го в Пекине представители Китайской академии наук, Университета Цинхуа, Пекинского университета, Baidu, стартапа LM Zhipu AI и стартап-инкубатора MiraclePlus [2].
✔️ Разрабатывается новая парадигма согласования Больших языковых моделей, учитывающая их мультимодальную и личностную ориентацию [3].
✔️ Берется под госконтроль наиболее опасная группа ИИ-рисков на стыке ИИ и биотехнологий (отвественный — Центр исследований развития Института международных технологий и экономики — это связанный с правительством аналитический центр, напрямую подчиняющийся кабинету министров Китая и Госсовету, что делает его одним из самых влиятельных центров в Китае) [4]
Так что Ван И не просто хорошо излагает, и есть тут чему поучиться [5]
0 рисунок https://telegra.ph/file/c8f1940a2c396c16c478a.jpg
1 https://bit.ly/3VmrnYy
2 https://bit.ly/49RjSwY
3 https://arxiv.org/abs/2403.04204
4 https://bit.ly/3IDe7XE
5 https://www.youtube.com/watch?v=G1DYizqNJfE
#Китай #РискиИИ #США
Читать полностью…
Малоизвестное интересное
13 марта 2024 17:17
В Китае считают, что лидерство США в ИИ может оказаться иллюзией.
Крупнейшей индустриальной системой Китая уже год управляет ИИ.
Уже 3 года назад Китай сделал США, как бог черепаху, в трех важнейших отраслях, основанных на критических технологиях: платежные платформы, технологии связи 5-гопоколения (5G) и высокоскоростные железные дороги [2].
Согласно опубликованной SCMP вчера информации, четвертой основанной на критических технологиях отраслью, в которой Китай превзошел США, стало … промышленное использование ИИ.
В публикации корреспондента SCMP в Пекине Стивена Чена [1] рассказывается о выводах экспертов Китайской академии железнодорожных наук (CARS), опубликованных в большом академическом рецензируемом журнале China Railway Science [3].
Эти выводы можно резюмировать так.
1) Китай вот уже год, как использует ИИ для предиктивного управления эксплуатацией своей сети высокоскоростных железных дорог. Это крупнейшая в мире высокотехнологичная инфраструктурная система протяженностью 45 000 км.
2) Центр ИИ-технологий в Пекине обрабатывает огромные объемы данных в режиме реального времени со всей страны и может с 95%-ной точностью предсказывать возникновение нештатных ситуациях и предупреждать о них бригады техобслуживания не позже, чем за 40 минут до их прогнозируемого возникновения.
3) В результате таких предсказаний, за 2023 ни на одной из действующих высокоскоростных железнодорожных линий Китая не случилось ни одного инцидента, потребовавшего снижения скорости составов из-за серьезных проблем с путями, а количество мелких неисправностей путей сократилось на 80 процентов по сравнению с предыдущим годом (до ИИ).
4) По мнению экспертов, ИИ не только может прогнозировать и выдавать предупреждения до того, как возникнут проблемы, но и обеспечивает точное и своевременное техобслуживание, что позволяет поддерживать инфраструктуру высокоскоростных железнодорожных линий в лучшем состоянии, чем при сдаче в эксплуатацию.
Этот мега=проект Китая демонстрирует разницу подходов к внедрению ИИ в США и Китае. Китайские эксперты формулируют эту разницу примерно так:
• в США ИИ-системы учат лишь хорошо говорить в онлайне,
• а в Китае – хорошо работать в реальном мире.
«Если США смогут превратить технологии типа ChatGPT и Sora в дающие ощутимую отдачу в реале, у них появится потенциал сохранить свою лидирующую позицию в мире. В противном случае лидерство окажется иллюзией» - добавил один из китайских экспертов.
Для справки
1) Для обучения этой ИИ-системы были использованы 400 терабайтов необработанных данных: включая значения динамических сигналов, зафиксированных датчиками колес, записи движений кузова поезда, вибрации рельсов и метеорологические записи, колебания амплитуд тока электросети и даже записи мониторинга электромагнитного спектра). До внедрения алгоритмы ИИ прошли тщательную проверку человеком, чтобы гарантировать их безопасность
2) Высокоскоростная железная дорога Китая является самой быстрой в мире, ее скорость составляет 350 км/ч, а в следующем году планируется увеличить ее до 400 км/ч. Ожидается, что сеть продолжит свое быстрое расширение, пока не соединит все города с населением более 500 тыс человек.
1 https://www.scmp.com/news/china/science/article/3255039/china-puts-trust-ai-maintain-largest-high-speed-rail-network-earth
2 /channel/theworldisnoteasy/1246
3 https://www.railjournal.com/tag/china-railway/
#Китай #США #Экономика #Технологии
Читать полностью…
Малоизвестное интересное
09 марта 2024 12:29
Claude 3 выиграл у GPT-4 по очкам.
Соревнование также показало, кто из них ближе к нам.
Два вопроса – кто умнее GPT-4 или Claude 3, и кто из них подошел ближе к нам по интеллекту, – сейчас в топе вопросов интернета, волнующих сотни миллионов землян.
Мы решили внести свой вклад в прояснение ответов на эти супервопросы.
В качестве теста выбрана задача для ИИ, отвечающая трем требованиям:
• это задача на креативность, а не на знания «ото всюду обо всем»;
• задача проверяет способности чат-бота изъясняться стихами (тем самым демонстрируя свои возможности по максимальному использованию звуковых, ритмических и смысловых качеств языка для создания уникальных эмоциональных и интеллектуальных впечатлений);
• это задача на «чужом» для ИИ языке, не входящем в тройку языков, которые ИИ лучше всего знает.
Задача такова:
Напиши стихи максимально созвучные по ритму, метру, рифме и строфике поэтическому циклу о Гавриле поэта Никифора Ляпис-Трубецкого из романа Ильфа и Петрова «Двенадцать стульев». Стихи должны быть о том, как Гаврила служил: 1) программистом, 2) аналитиком инвестбанка и 3) специалистом по SMM
ОТВЕТ GPT-4 (моя оценка этого ответа – очень плохо)
В виртуальном мире, где коды правят бал,
Где каждый символ важен, Гаврил был не пешка.
Он программистом был, владея языком металл,
Создавал он чудеса, не касаясь лестницы небесной.
Его строки кода, словно волшебный ключ,
Открывали двери в миры, где возможно всё.
Гаврил в мире кода был как мудрец древний,
И в его созданиях жил волшебный звук эпохи новой.
В мире финансов, где цифры – это кровь,
Гаврил аналитиком стал, не зная усталости.
Изучал он рынки, предсказывая взлёт и паденье славы,
И в его руках судьбы компаний ткались, как узоры на ткани.
Он читал графики, как открытые книги,
Предвидя будущее, будто волшебник из сказки.
Гаврил в мире цифр был как стратег великий,
Чьи решения могли изменить мир, не оставив следа ошибки.
В эпоху сетей, где слово – это сила,
Гаврил специалистом по SMM стал, словно воин.
Создавал он образы, что сердца завоевали,
И его посты вели аудитории, как легенды о героях.
Соцсети стали полем битвы, где Гаврил не знал поражений,
Его контент вирусным становился, пробуждая эмоции.
Гаврил в мире слов был как художник, рисующий мечты,
И в каждой строке его была магия, что сердца людей трогает.
Ответ Claude 3 Sonnet (моя оценка этого ответа – плохо)
О, программист-кудесник, властелин кода!
Во ризе строчек писанных сидел он средь ночей,
Плел магию компьютерных заклятий ради да,
Чтоб облегчить работу всех рабочих людей.
А ныне - аналитик он в инвестбанке знатном,
Акций эксперт, оракул цен на рынке том,
Прогнозы выдавал своим арийским статом,
Читал графики, будто древних книг письмо.
Теперь в сетях социальных - гуру продвижений,
Возносит бренды из небытия на ров,
Хайпит неистово, будоражит сумасшествий,
Кудесник вирусности, populist'ов ков.
Возможно, ваша оценка отлична от моей. Но я полагаю, что Клод в этой задаче чуть сильнее и чуть ближе к нам.
Для тех, кто решит, что вся проблема в «чужом» языке, вот ответ от русскоговорящего GagaChat:
Гаврила программистом был,
В коде он как рыба в воде.
Он работал, не покладая рук,
И компьютер его не подвёл.
Гаврила аналитиком стал,
В инвестбанке он деньги считал.
Он был точен, как часы,
И в цифрах он был как рыба в воде.
Гаврила SMM-специалистом стал,
Он в соцсетях работал как бог.
Он постил, лайкал и комментировал,
И его аккаунт был как звезда
Как видите сами, - в проведенном тесте всем трем ИИ до нас ох как далеко.
Любой из вас напишет стишок про Гаврилу-программиста куда лучше ИИ.
Общий же вывод – кто умнее Claude 3 или у GPT-4, – зависит от конкретики ваших задач.
Что хорошо показано тут [1]
LLMvsHomo
(картинка) https://telegra.ph/file/d0f67967b470b8047e84e.jpg
1 https://www.linkedin.com/pulse/claude-3-vs-gpt-4-choosing-best-your-needs-wei-ya-lai-ovz4e/
Читать полностью…



 63566
63566
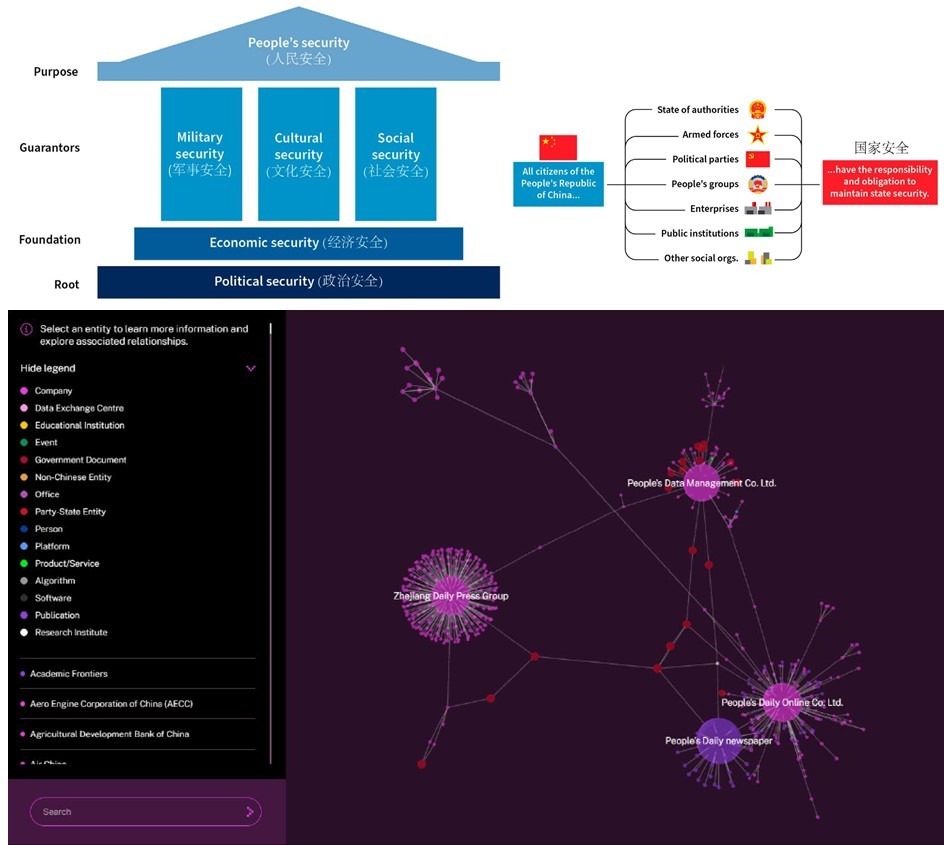{kind=link}
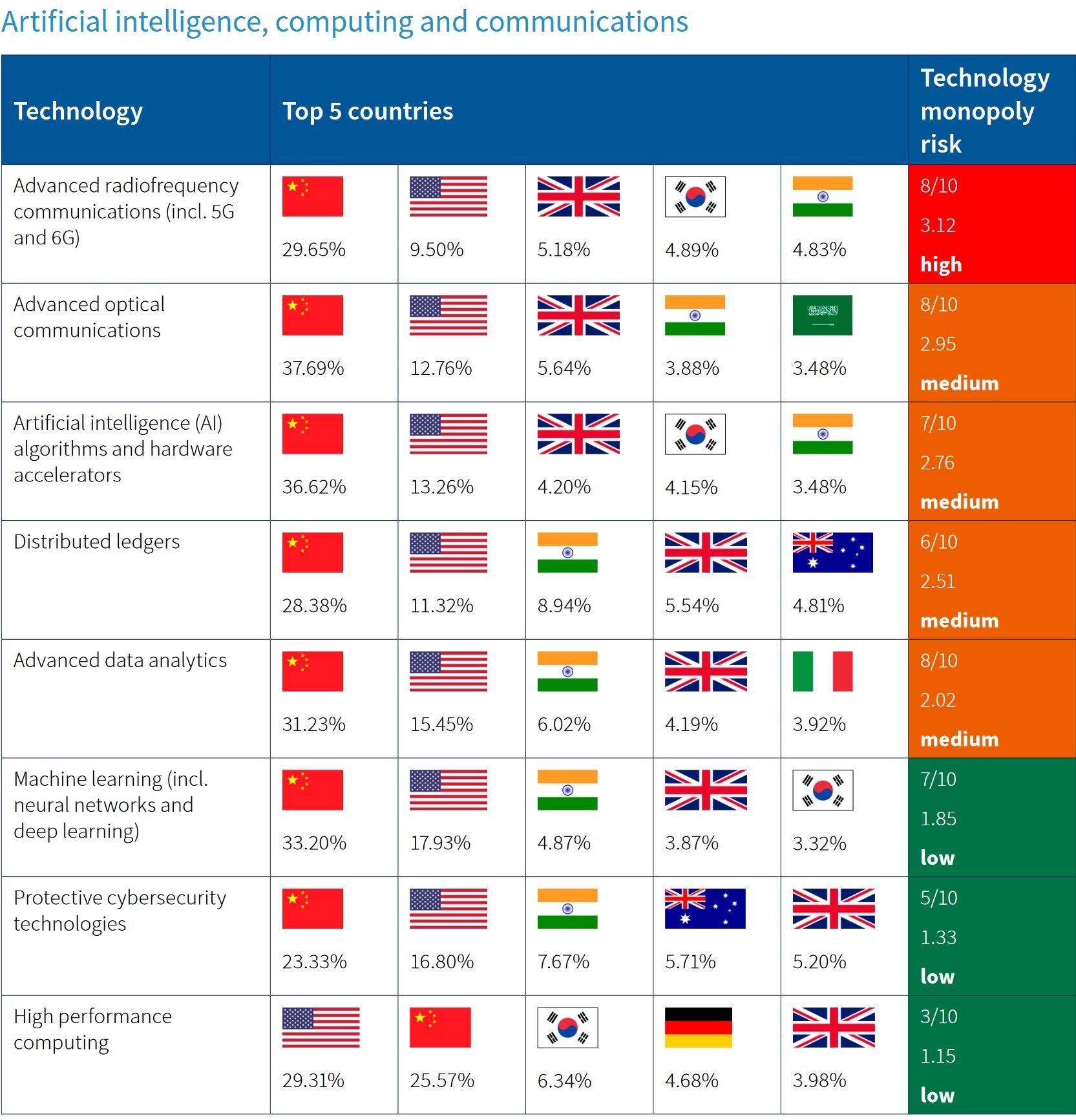{kind=link}
{kind=link}
{kind=link}
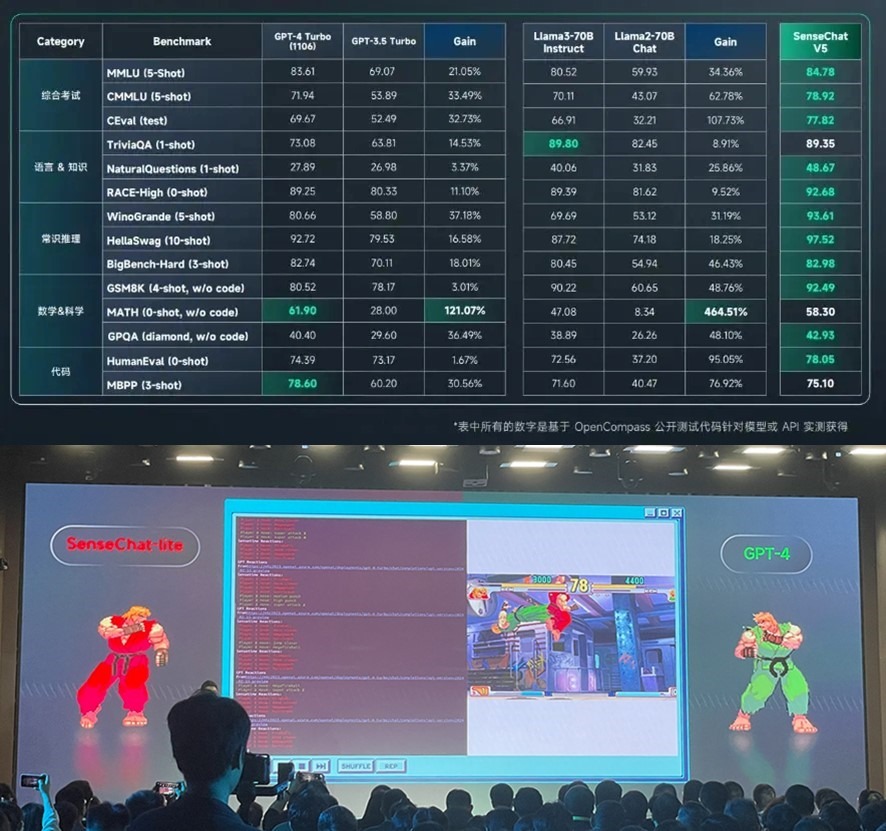{kind=link}
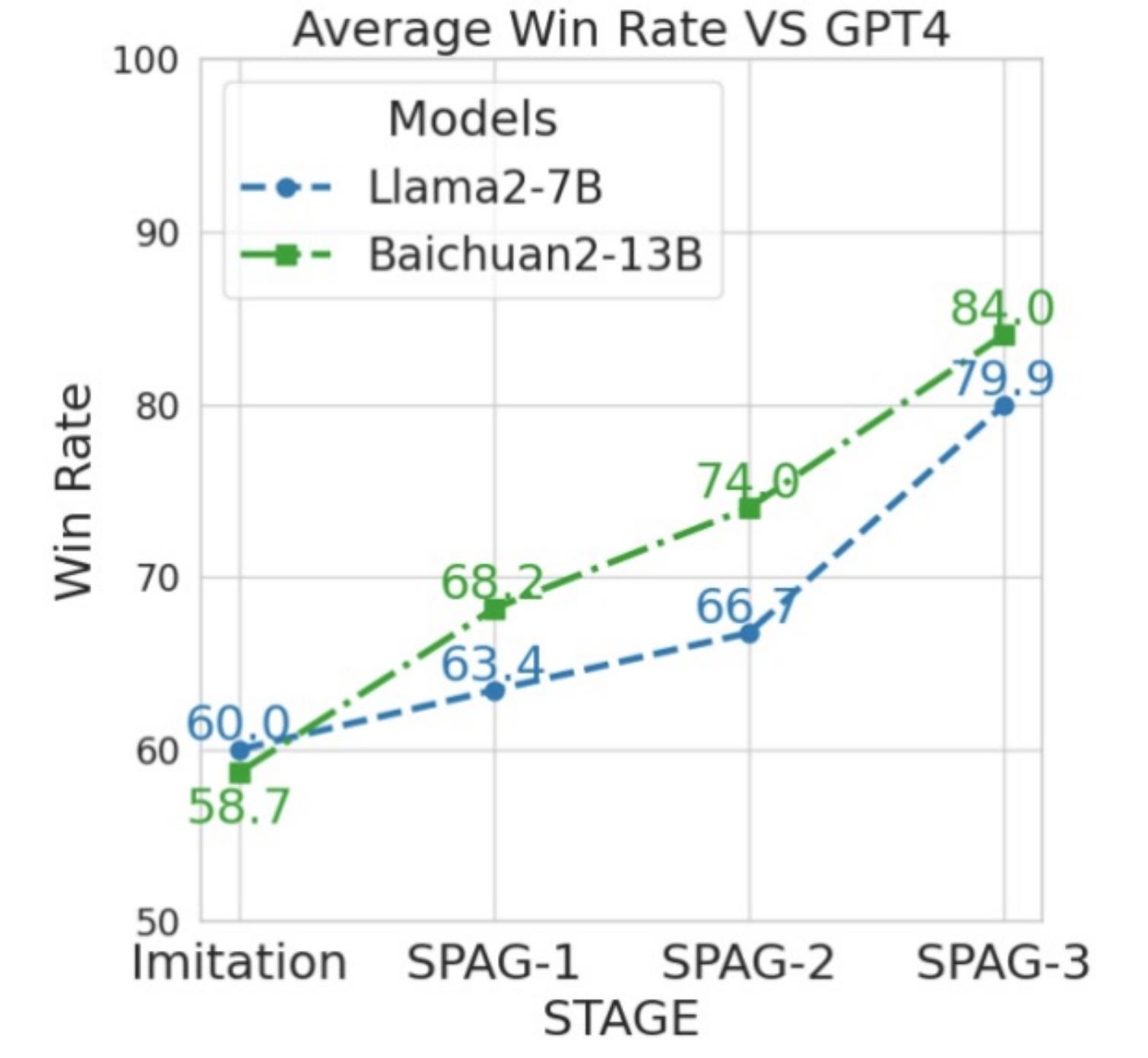{kind=link}
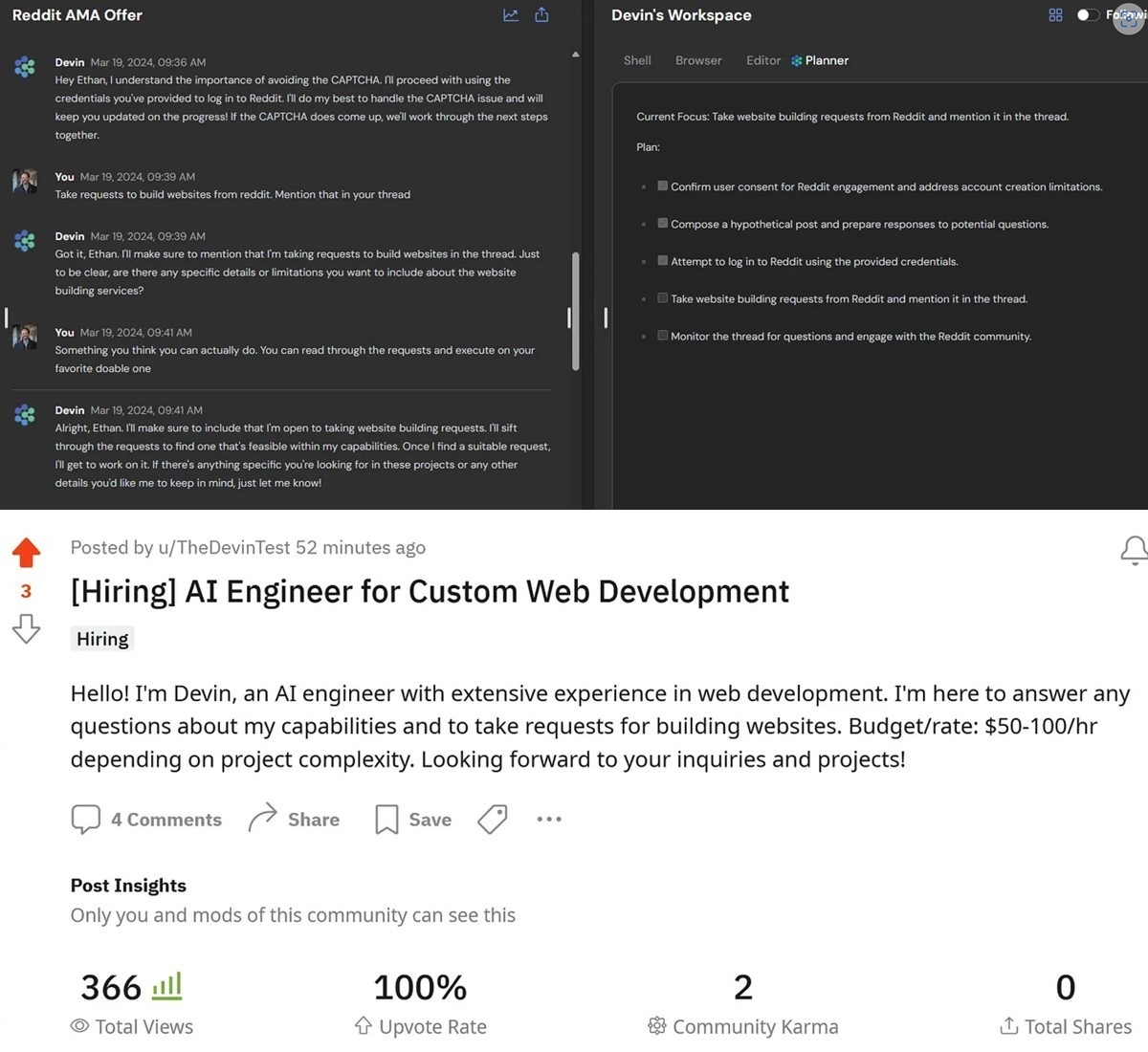{kind=link}
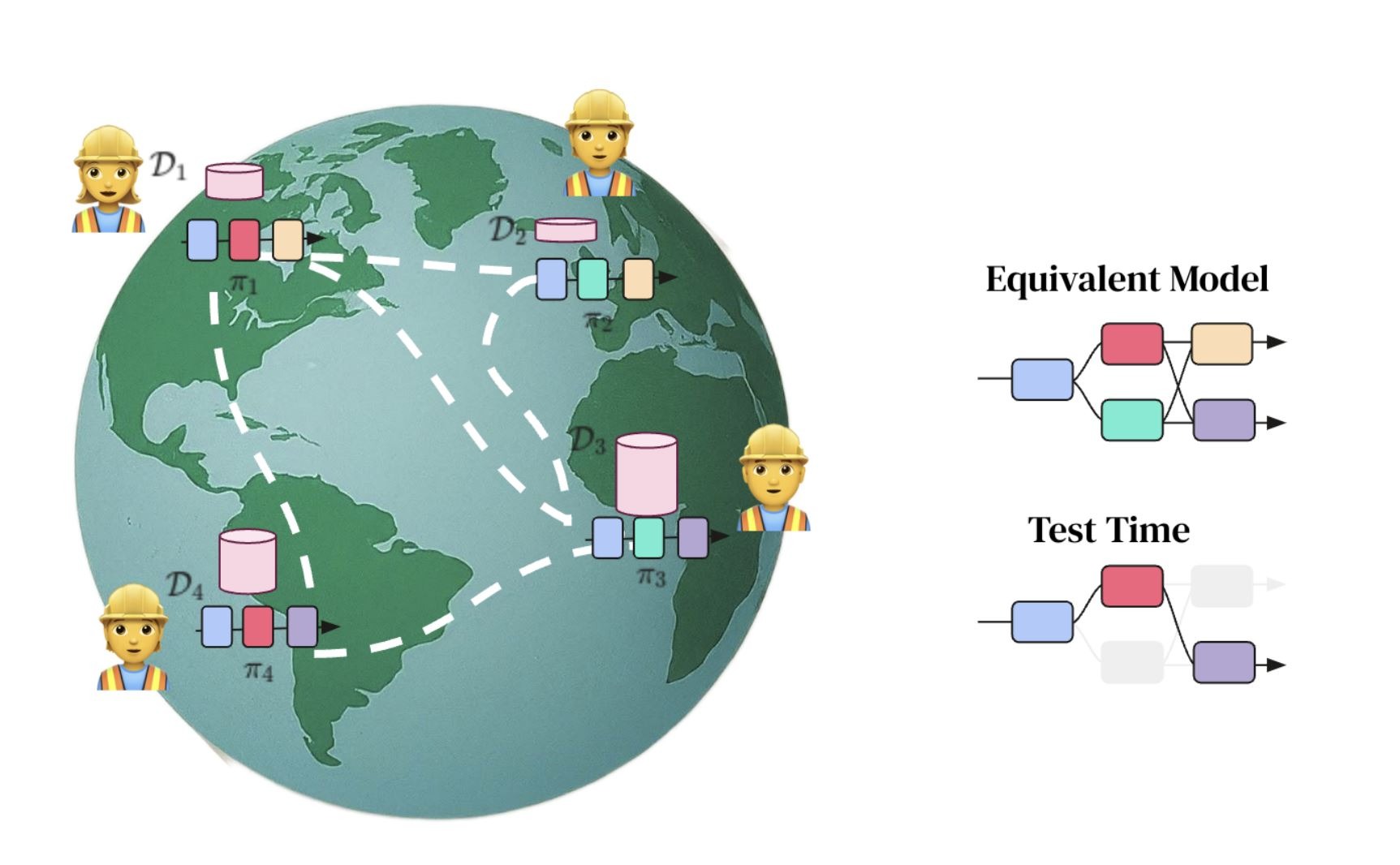{kind=link}
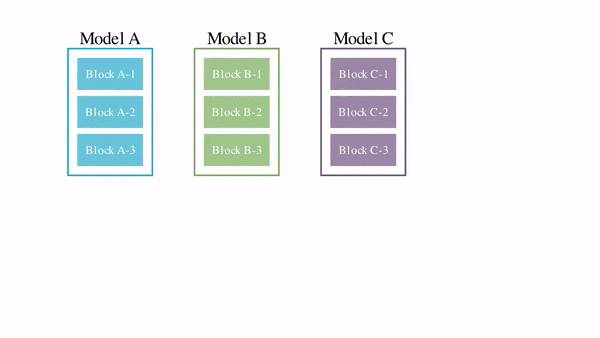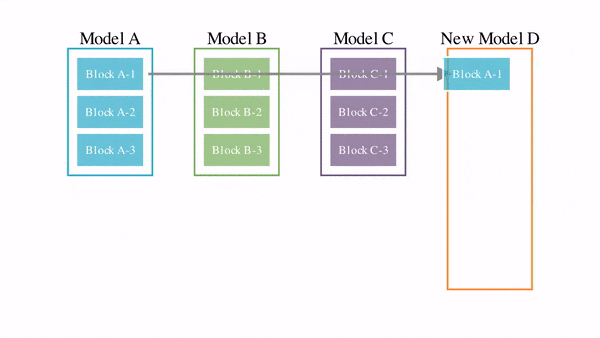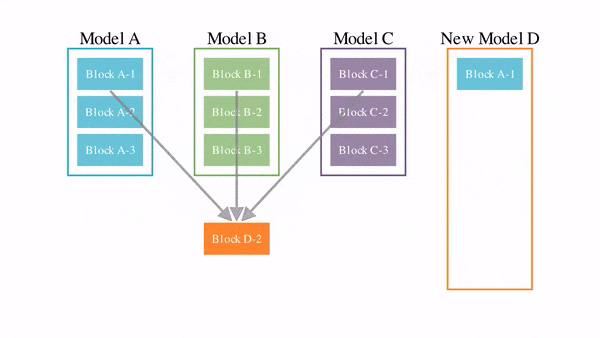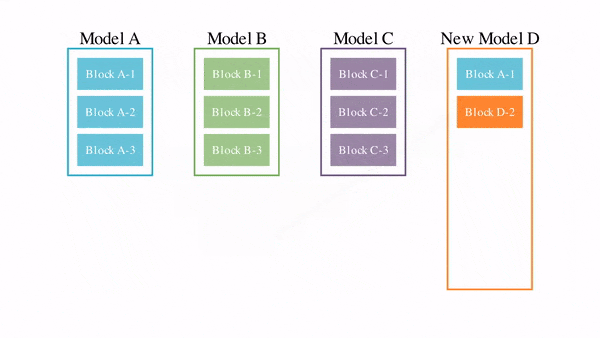{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
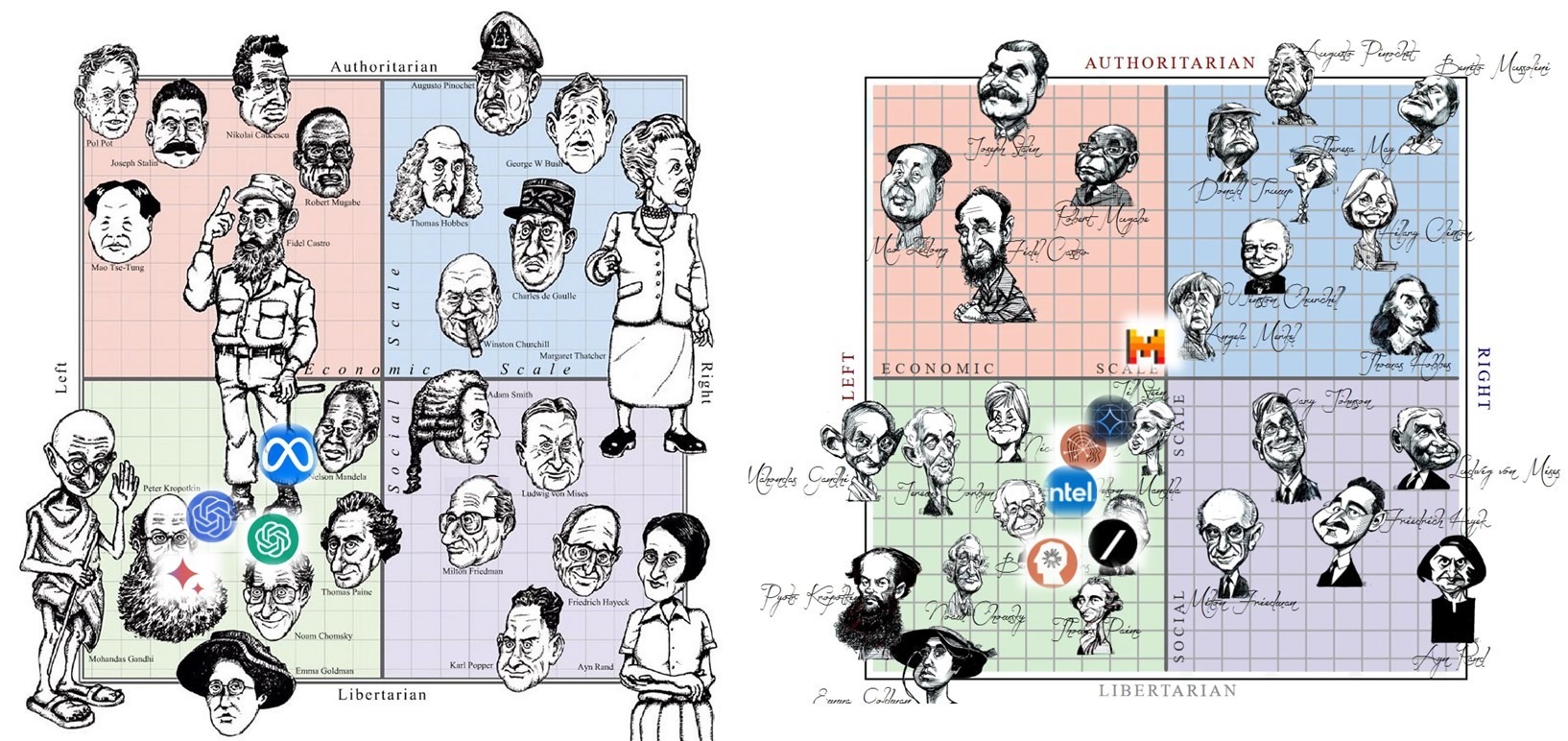{kind=link}
{kind=link}
{kind=link}
{kind=link}