Малоизвестное интересное
25 декабря 2023 12:45
Разум в Мультиверсе.
Мы пытаемся создать то, что создало нас?
Как подняться над потоком сиюминутных новостей о генеративном ИИ больших языковых моделей, чтобы сквозь дымовые завесы превращающихся в культы многочисленных хайпов (маркетингового а-ля Маск, коммерческого а-ля Альтман, думеровского а-ля Юдковский, акселерационистского а-ля Шмидхубер, охранительного а-ля Хинтон) попытаться разглядеть контуры их центрального элемента – появление на Земле сверхразума?
Ведь по экспертным оценкам, в результате революции ChatGPT, возможность появления сверхразума на Земле переместилась из долгосрочной перспективы на временной горизонт ближайших 10-15 лет. Параллельно с сокращением прогнозных сроков появления сверхразума, в экспертной среде укрепляется понимание, что в этом вопросе «все не так однозначно». Скорее всего, появление сверхразума не будет выражаться лишь в многократном превышении со стороны ИИ интеллектуальных показателей людей. Весьма возможно, что появление сверхразума проявит себя, как своего рода эволюционный скачок, сопоставимый с возникновением жизни из неживой материи (что предполагает появление совершенно новых форм разума с иными способами восприятия реальности, мышления, мотивации и т.д.)
Но что если все еще более неоднозначно? Что если сверхразум уже существует, и это он создал жизнь и разум на Земле, привнеся их в нашу Вселенную из бесконечного пространства и времени Мультиверса? Ведь если это так, то человечество, в прогрессирующем приступе самопереоценки, пытается создать то, что создало нас …
Перед такой постановкой вопроса вянут все хайпы от «хайпа а-ля Маск» до «хайпа а-ля Хинтон». А уж представить, что кто-то из хайпмейкеров Силиконовой долины и ее окрестностей сможет не только поставить подобный вопрос, но и ответить на него (причем опираясь исключительно на современные научные знания), было бы крайне сложно.
Но вот сложилось. И не в Силиконовой долине, а в заснеженной России.
Двум докторам наук Александру Панову (физик, автор знаменитой «вертикали Снукса-Панова», отображающей движение человечества к сингулярности через серию фазовых переходов) и Феликсу Филатову (биолог, автор гипотезы происхождения жизни на Земле, аргументированной особенностями молекулярной организации одного из ее ключевых феноменов - генетического кода) - это удалось на славу (что меня сильно порадовало, показав, что интеллектуальный потенциал нынешних неотъехавших вполне сопоставим с потенциалом отъехавших на «философских пароходах», увезших из России в 1922 г. много светлых умов оппозиционно настроенной интеллигенции, по сравнению с которыми, уровень философского понимания реальности Маска и Альтмана довольно скромен).
Но как ни захватывающе интересна тема, и как ни важен обсуждаемый вопрос, далеко ни у всех читателей моего канала найдется время на просмотр почти 2-х часового доклада (а потом еще и часового Q&A).
Для таких читателей на приложенном рисунке авторское резюме доклада.
https://disk.yandex.ru/i/MwD4M-ec2Gq0lQ
А это видео доклада
https://youtu.be/2paQJejLZII?t=253
#Разум #Мультиверс #AGI
Читать полностью…
Малоизвестное интересное
21 декабря 2023 12:16
Среди семи прогнозов Stanford HAI - что ожидать от ИИ в 2024, - три ключевых [1]:
1. Дезинформация и дипфейки захлестнут мир.
2. Появятся первые ИИ-агенты, не только помогающие, но и делающие что-то за людей.
3. Регулирование ИИ зайдет в тупик из-за необходимости решения проблемы «супервыравнивания».
Два первых прогноза понятны без пояснений.
3й поясню.
• Cуществующие методы выравнивания (управление тем, чтобы цели людей и результаты их реализации ИИ совпадали) перестают работать в случае сверхразумного ИИ
• Появление сверхразумных ИИ (которые превосходят человеческий интеллект в большинстве задач, имеющих экономическую ценность) все ближе
• Если до их появления не появятся методы выравнивания с ним («супервыравнивания»), миру мало не покажется
С целью решить эту проблему OpenAI и Эрик Шмидт совместно объявили $10 млн программу грантов [2].
Похвально, но смахивает на PR.
[1] https://hai.stanford.edu/news/what-expect-ai-2024
[2] https://openai.com/blog/superalignment-fast-grants
#AGI
Читать полностью…
Малоизвестное интересное
19 декабря 2023 14:30
ИИ вскрыл “пространство открытий” человечества, войдя туда через заднюю дверь.
Столь эпохальный прорыв Google DeepMind авторы от греха опасаются называть своим именем.
FunSearch от Google DeepMind, - скромно представленная создателями, как новый эволюционный методический инструмент решения математических задач, с ходу в карьер сделал математическое открытие, решив центральную задачу экстремальной комбинаторики – задачу о наборе предельных значений.
Это несомненная сенсация, поскольку:
• это 2-е в истории человечества математическое открытие, сделанное машиной (1-е открытие также сделал DeepMind, создав в 2022 AlphaTensor (агент в стиле AlphaZero), который обнаружил превосходящие человеческие алгоритмы для выполнения таких задач, как умножение матриц)
• это 1-е в истории человечества математическое открытие, сделанное большой языковой моделью (LLM) – главным кандидатом на превращение в СуперИИ.
https://deepmind.google/discover/blog/funsearch-making-new-discoveries-in-mathematical-sciences-using-large-language-models/?utm_source=twitter&utm_medium=social
Однако, если называть вещи своими именами, - это не «еще одна сенсация», а суперсенсация, открывающая новую эру в развитии ИИ на основе LLM - эволюционный метод FunSearch позволяет расширять границы человеческих знаний.
✔️ Этот метод позволяет ИИ на основе LLM выходить за пределы знаний, предоставленных модели людьми на стадии ее обучения (и воплощенные, в результате обучения, в миллиарды и триллионы корреляций между словами).
✔️ Образно говоря, этот метод открывает для ИИ на основе LLM «дверь в пространство знаний», еще не познанных людьми.
✔️ Но это не обычная «дверь», через которую в это пространство попадают люди, совершая открытия. Это, своего рода, «задняя дверь», - не доступная людям, но вполне подходящая для LLM.
Хитрость «задней двери в пространство еще не познанных людьми знаний» в том, что, подобно всем другим интеллектуальным операциям LLM, эта операция нечеловеческая (не доступная людям в силу своих масштабов).
1. сначала предварительно обученная LLM генерирует первоначальные творческие решения в виде компьютерного кода;
2. потом вступает в дела «автоматический оценщик», задача которого отсеять из множества первоначальных решений любые подозрения на конфабуляции модели (кстати, использование применительно к LLM термина «галлюцинация» - это сильное огрубление смысла, ведущее к его ограниченной трактовке; верный термин – именно конфабуляция), т.е. возникновение ложного опыта из-за появления фрагментов памяти с описанием того, чего, на самом деле, не было в реальных данных обучения);
3. в результате объединения 1 и 2, первоначальные решения эволюционным путем «превращаются» в новые знания, т.е., по сути, происходит «автоматизация открытий», о которой вот уже несколько десятков лет мечтают разработчики ИИ - вычисления превращаются а оригинальные инсайты.
В заключение немного остужу восторги.
Это вовсе не преувеличение, что FunSearch знаменует новую эру в развитии ИИ на основе LLM, позволяя им проникать в «пространство открытий» человечества.
Однако, FunSearch позволяет ИИ попасть лишь в весьма небольшую часть этого пространства – в пространство решений задач, для которых легко написать код, оценивающий возможные решения.
Ибо многие из наиболее важных проблем — это проблемы, которые мы не знаем, как правильно оценить успех в их решении. Для большинства таких проблем, знай мы, как количественно оценить успех, уж решения то мы уж как-нибудь придумали бы.... (подробней про это я написал целый суперлонгрид «Ловушка Гудхарта» для ИИ /channel/theworldisnoteasy/1830.
А для того, чтоб сравниться с людьми в полном освоении «пространства открытий», без интуитивной прозорливости ИИ не обойтись (впрочем, и про это я уже писал 😊 /channel/theworldisnoteasy/1650).
#ИИ #AGI #Вызовы21века #инновации #серендипность
Читать полностью…
Малоизвестное интересное
15 декабря 2023 11:29
Взгляните на этот веселый Deep Fake от @.
Трудно придумать более наглядную иллюстрацию двух топовых прогнозов отчета State of AI Report на 2024 год (см. /channel/theworldisnoteasy/1823):
1. В Голливуде произойдет технологическая революция в области создания визуальных эффектов – весь процесс будет отдан на откуп ГенИИ.
2. Начнется первое в истории расследование вмешательства ГенИИ известного на весь мир производителя в предвыборную президентскую кампанию в США.
Описывая мир победившего к 2041 году ИИ, легендарный визионер, техно-инвестор и стратег Кай-Фу Ли предвидит, что главным инструментом власти и криминала станет не насилие, а ИИ технология DeepMask - преемник сегодняшних DeepFake (см. /channel/theworldisnoteasy/1349).
Полагаю, что мой старый коллега по SGI ошибся лишь в одном – это случится гораздо раньше.
#Deepfakes
Читать полностью…
Малоизвестное интересное
13 декабря 2023 12:53
Внутри маскирующегося под стохастического попугая ИИ таится куда боле мощный ИИ.
Эксперимент показал - у больших моделей есть воображение.
Анализ 3х работ OpenAI, Anthropic и Google DeepMind навевает ассоциации с леденящим душу технокошмаром из серии фильмов ужасов «Чужой».
Точнее, с их облегченной версией, - где «чужой» может оказаться злым монстром, а может и нет. Но сам факт, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает.
1) Еще в мае исследователи из OpenAI решили попытаться «заглянуть в душу» ИИ (точнее называть это «большой языковой моделью - LLM», но ИИ короче и понятней). Исследователи подошли к решению задачи «черного ящика» ИИ (понять, что у него внутри) супер-креативно.
Зачем самим ломать голову, решая неподъемную для людей задачу. Пусть большой ИИ (GPT-4 с числом нейроном 100+ млрд) сам ее и решит применительно к маленькому ИИ (GPT-2, в коем нейронов всего то 300К+) [1].
Результат озадачил исследователей. Многие нейроны (внутри маленького ИИ) оказались многозначны – т.е. они реагировали на множество самых разных входных данных: смесь академических цитат, диалогов на английском языке, HTTP-запросов, корейского текста …
Эта многозначность нейронов человеческой логике не понятна и ею не объятна. Если нейроны многозначны, какие же тогда более мелкие «субнейроны» соответствуют конкретным понятиям?
2) Ответ на этот вопрос дают исследователи из Anthropic [2]. Они полагают, что одной из причин многозначности является суперпозиция - гипотетическое явление, при котором нейронная сеть представляет больше независимых «функций» данных, чем нейроны, назначая каждой функции свою собственную линейную комбинацию нейронов.
Иными словами, внутри нейронной сети любого конкретного ИИ симулируется физически не существующая нейронная сеть некоего абстрактного ИИ.
И эта симулируемая нейронная сеть,
1. гораздо больше и сложнее нейронной сети, ее моделирующей;
2. содержит симулируемые моносемантические «субнейроны» (соответствующие конкретным понятиям);
Еще проще говоря: внутри менее мощного ИИ симулируется более мощный ИИ. Менее мощный ИИ физически существует в виде сети нейронов. Более мощный – в виде сети паттернов (линейных комбинаций) активаций нейронов.
3) Почувствовать на практике, сколь мощный ИИ таится внутри маскирующегося под «стохастического попугая» ИИ LLM, позволяет новое исследование Главного научного сотрудника Google DeepMind проф. Шанахана и директора CHPPC_IHR проф. Кларк [3].
Объектом исследования стало якобы отсутствующее у LLM свойство разума, без которого невозможно истинное творчество – воображение.
Эйнштейн писал - “Воображение важнее знаний. Ибо знания ограничены всем, что мы сейчас знаем и понимаем, в то время как воображение охватывает весь мир и все, что когда-либо можно будет узнать и понять”.
Эксперимент Шанахана-Кларк заключался в проверке наличия у GPT-4 воображения, позволяющего модели проявлять художественную креативность при написании (в соавторстве с человеком) литературного текста - фантастического романа о путешествии во времени.
Эксперимент показал:
✔️ при наличии сложных подсказок и соавтора-человека, модель демонстрирует изысканное воображение;
✔️ это продукт творчества модели, ибо ничего подобного люди до нее не придумали (этого не было в каких-либо текстах людей): например, появляющиеся по ходу романа придуманные моделью:
- новые персонажи и сюжетные повороты;
- новые неологизмы (прямо как у Солженицина), служащие для раскрытия идейного содержания сюжета - отнюдь не бессмысленные, семантически верные и контекстуально релевантные.
Значение вышеописанного см. в моем цикле “теория относительности интеллекта”.
#Креативность #Воображение #LLM
[1] https://openai.com/research/language-models-can-explain-neurons-in-language-models
[2] https://transformer-circuits.pub/2023/monosemantic-features
[3] https://arxiv.org/abs/2312.03746
Читать полностью…
Малоизвестное интересное
06 декабря 2023 13:20
Мир стал другим.
Сложилось альтернативное понимание истины и честности.
В мире уже не первый год устойчиво крепчает тренд на безумие. Он все ярче проявляется и в деградации внешней политики многих стран (стремительно скатывающейся к дегенерации), и в нарастающем пожаре раскола и поляризации внутри отдельных стран, безумно поливаемом бензином действий их политиков и элит.
https://media.springernature.com/lw685/springer-static/image/art%3A10.1038%2Fs41562-023-01691-w/MediaObjects/41562_2023_1691_Fig1_HTML.png?as=webp
Год назад я анализировал вопрос о том, «кто более виновен в происходящем безумии - элита или народ» [1], на основе прямого измерения цифровых следов людей в Интернете, проведенного проф. Рэнд и Мослех в работе «Измерение подверженности мисинформации со стороны политических элит в Twitter». Измеряя показатели «токсичности лжи» 816-ти представителей элиты и «иммунитета к мисинформации» у их подписчиков, авторы выявили сложную связку отношений элита-народ:
• лидеры слабо реагируют на отношение народа к сказанному ими;
• риторика элиты определяет убеждения и политические позиции народа;
• чем лживее представитель элиты, тем сильнее снижается у его подписчиков иммунитет к мисинформации, что упрощает ему убеждение их в еще большей лжи.
Новое исследование междисциплинарной группы исследователей (психологи, когнитивисты, спецы по компьютерной симуляции и вычислительной социологии) «От альтернативных концепций честности к альтернативным фактам в коммуникациях политиков США» [2] продвигает нас в понимании общественного и политического мироустройства в эпоху постправды.
В работе анализируются способы воздействия дезинформации, распространяемой в целях заставить людей изменить свое поведение. Авторы копаю глубже примитивного навешивания ярлыков: правда-ложь, факт-фейк и т.п. Они пытаются выделить в публичной политической речи выборных должностных лиц США два компонента правды и честности — высказывание убеждений и изложение фактов.
Такой подход основан на онтологии политической истины, включающей две различные концепции истины:
• Высказывание убеждений относится только к убеждениям, мыслям и чувствам говорящего, без учета фактической точности. Эта концепция основана на интуиции, субъективных впечатлениях и чувствах.
• Изложение фактов, напротив, связано с поиском точной информации и обновлением своих убеждений на основе этой информации. Эта концепция истины основана на фактических данных.
N.B. Хотя истина и честность являются тесно связанными понятиями, а честность и правдивость являются почти синонимами, в данном контексте их необходимо распутать для ясности.
Анализируя сообщения членов Конгресса США в Твиттере в период с 2011 по 2022 год, авторы показали следующее:
1. Концепция честности политиков претерпела явный сдвиг: высказывания подлинных убеждений, которые могут быть отделены от доказательств, становятся все более заметными и более дифференцированными от явно основанного на доказательствах изложения фактов.
2. Представление политиков о честности претерпели явные изменения, при этом высказывание подлинных убеждений, которые могут быть отделены от доказательств, становятся более заметными и более дифференцированными от явно основанных на фактах высказываний.
3. Для республиканцев (но не для демократов) повышение уровня веры к высказыванию на 10% связано со снижением на 12,8 пункта качества источников (по системе оценки NewsGuard), которыми поделились.
4. Напротив, увеличение числа говорящих на языке фактов связано с повышением качества источников для обеих сторон.
Эти результаты согласуются с гипотезой о том,
что нынешнее распространение дезинформации в политическом дискурсе связано с укреплением альтернативного понимания истины и честности, которое делает акцент на использовании субъективных убеждений в ущерб уверенности в доказательствах.
1 /channel/theworldisnoteasy/1644
2 https://www.nature.com/articles/s41562-023-01691-w
#Мисинформация #Элита #Раскол
Читать полностью…
Малоизвестное интересное
01 декабря 2023 11:11
По сути, Microsoft показал, что AGI уже здесь.
Поверить в это трудно, но придется.
Новое исследование топовой команды ученых из Microsoft во главе с самим Эриком Хорвиц, (главный научный сотрудник Microsoft) показало 3 сенсационных результата.
1. Нынешняя версия GPT-4 таит в себе колоссальные «глубинные знания», не уступающие уровню знаний экспертов – людей в широком круге проблемных областей (т.е. с учетом многозначности определений AGI, не будет сильным преувеличением сказать, что GPT-4 уже практически достиг уровня AGI).
2. Эти «глубинные знания» прячутся где-то внутри базовой большой языковой модели, лежащей в основе GPT-4. Т.е. они получены моделью на этапе ее обучения, без каких-либо вмешательств со стороны людей (специальной дополнительной тонкой настройки или опоры на экспертные знания специалистов при создании подсказок).
3. Получить доступ к «глубинным знаниям» модели можно, если поручить самой модели промпт-инжиниринг (разработку подсказок) для самой себя, с использованием методов:
- «обучения в контексте»,
- составления «цепочек мыслей»,
- «сборки» (объединение результатов нескольких прогонов модели для получения более надежных и точных результатов, объединяя их с помощью таких функций, как усреднение, консенсус, или большинство голосов).
В результате получения доступа к «глубинным знаниям» модели, «обычный» GPT-4:
• без какой-либо тонкой настройки на спецданных и без подсказок профессиональных экспертов-медиков,
• а лишь за счет высокоэффективной и действенной стратегии подсказок, разработанных самим интеллектом GPT-4 (эта методика названа авторами Medprompt), -
обнаружил в себе значительные резервы для усиления специализированной производительности.
В итоге, GPT-4 с Medprompt:
✔️ Впервые превысил 90% по набору данных MedQA
✔️ Достиг лучших результатов по всем девяти наборам эталонных данных в пакете MultiMedQA.
✔️ Снизил частоту ошибок в MedQA на 27% по сравнению с MedPaLM 2 (до сих пор бывшая лучшей в мире специально настроенная медицинская модель от Google)
См. рисунок https://www.microsoft.com/en-us/research/uploads/prod/2023/11/joint_medprompt_v1.png
Медициной дело не ограничилось.
Для проверки универсальности Medprompt, авторы провели исследования его эффективности на наборах оценок компетентности в шести областях, не связанных с медициной, включая электротехнику, машинное обучение, философию, бухгалтерский учет, юриспруденцию, сестринское дело и клиническую психологию.
Результаты показали – Medprompt эффективно работает во всех названных областях.
Понимаю, что многие скажут – это еще не AGI, - и заведут старую шарманку про стохастических попугаев.
Мне же кажется, что даже если это еще не AGI, то нечто предельно близкое к нему.
https://www.microsoft.com/en-us/research/blog/the-power-of-prompting/
#AGI
Читать полностью…
Малоизвестное интересное
28 ноября 2023 14:25
Это визуализация метаграфа – новой математики 21 века.
Публикация в Nature статьи Эйнштейна 21 века Алберт-Ласло Барабаши «Влияние физических качеств на структуру сети» [1] фиксирует научное признание того факта, что на Земле появилась новая математика. И это не просто новый раздел математики.
Сетевая физическая математика – это математика, зависящей от физических свойств объектов (что-то типа разных таблиц умножения, в зависимости от того, на чем они написаны).
Подробней о фантастических перспективах новой математики читайте в моем посте [2].
Здесь же лишь отмечу, что формализм метаграфов позволяет прогнозировать функциональные особенности физической сети. Например, формирование синапсов в коннектоме мозга, в соответствии с эмпирическими данными.
Приложенное модельное видео – один из первых примеров визуализации метаграфов.
Почувствуйте разницу с фМРТ :).
1 https://www.nature.com/articles/s41567-023-02267-1
2 /channel/theworldisnoteasy/1618
#КомплексныеСети
Читать полностью…
Малоизвестное интересное
23 ноября 2023 13:47
Что за «потенциально страшный прорыв» совершили в OpenAI.
Секретный «проект Q*» создания «богоподобного ИИ».
Сегодняшний вал сенсационных заголовков, типа «OpenAI совершила прорыв в области искусственного интеллекта до увольнения Альтмана», «Исследователи OpenAI предупредили совет директоров о прорыве в области искусственного интеллекта перед отстранением генерального директора» и т.п., - для читателей моего канала не вовсе новости. Ибо об этом я написал еще 4 дня назад.
Но от этого вала новостей, публикуемых сегодня большинством мировых СМИ, уже нельзя отмахнуться, как от моего скромного поста. И это означает, что СМО (специальная медийная операция), внешне выглядевшая, как низкопробное, скандальное ТВ-шоу, вовсе таковой не была. Ибо имела под собой более чем веские основания – забрезжил революционный прорыв на пути к тому, что известный эксперт по ИИ Ян Хогарт назвал «богоподобным ИИ».
Из чего следовала необходимость срочных кардинальных действий и для Сама Альтмана, и для Microsoft:
• Microsoft – чтобы не оказаться с носом, уже вложив в OpenAI $13 млрд (дело в том, что по имеющемуся соглашению, все действующие договоренности между Microsoft и OpenAI остаются в силе, лишь до момента, когда совет директоров OpenAI решит, что их разработки вплотную подошли к созданию сильного ИИ (AGI). И с этого момента все договоренности могут быть пересмотрены).
• Сэму – чтобы успеть сорвать банк в игре, которую он еще 7 лет назад описал так:
«Скорее всего, ИИ приведет к концу света, но до того появятся великие компании».
И Сэму, и Microsoft требовалось одно и то же - немедленный перехват управления направлением разработок OpenAI в свои руки. И сделать это можно было, лишь освободившись от решающего влияния в совете директоров OpenAI сторонников «осторожного создания AGI на благо всему человечеству». Что и было сделано.
Однако, точного ответа, что за прорыв совершили исследователи OpenAI, мы пока не имеем.
Все утечки из среды разработчиков OpenAI упоминают некий «секретный «проект Q*» [1] по радикальному повышению производительности лингвоботов на основе LLM.
Известно, что эта работа велась, как минимум, по трем направлениям:
1. Совершенствование RAG (Retrieval Augmented Generation) – сначала поиск релевантной информации во внешней базе в целях формирования из нее оптимального промпта, и лишь затем обращение к системе за ответом). Кое-какие результаты такого совершенствования были недавно показаны на OpenAI DevDAy. И они впечатляют [2].
2. Комбинация Q-обучения и алгоритма A*.
Алгоритм A* — это способ нахождения кратчайшего пути от одной точки до другой на карте или в сети. Представьте, что вы ищете самый быстрый маршрут из одного города в другой. Алгоритм A* проверяет разные пути, оценивая, насколько они близки к цели и сколько еще предстоит пройти. Он выбирает путь, который, по его оценке, будет самым коротким. Этот алгоритм очень эффективен и используется во многих областях, например, в компьютерных играх для нахождения пути персонажей или в GPS-навигаторах.
Q-обучение — это метод обучения без учителя в области искусственного интеллекта, который используется для обучения программ принимать решения. Представьте, что вы учите робота находить выход из лабиринта. Вместо того чтобы прямо говорить ему, куда идти, вы оцениваете его действия, давая баллы за хорошие шаги и снимая за плохие. Со временем робот учится выбирать пути, приводящие к большему количеству баллов. Это и есть Q-обучение — метод, помогающий программам самостоятельно учиться на своем опыте.
3. Поиск траектории токена по дереву Монте-Карло в стиле AlphaGo. Это особенно имеет смысл в таких областях, как программирование и математика, где есть простой способ определить правильность (что может объяснять утечки о прорывном улучшении в проекте Q* способностей решения математических задач)
#ИИ #AGI
1 https://disk.yandex.ru/i/9zzI_STuNTJ6kA
2 https://habrastorage.org/r/w1560/getpro/habr/upload_files/f9a/994/b06/f9a994b060188b43ba61061270213bca.png
Читать полностью…
Малоизвестное интересное
20 ноября 2023 11:21
Фронтовые новости битвы чекистов с масонами за AGI.
Самое важное за 24 часа о продолжающемся перевороте в мире ИИ.
1) Увольнение и реакция:
• Сэм Альтман, сооснователь и генеральный директор OpenAI, был уволен с должности CEO. Это решение вызвало шок в технологическом мире [1. 2].
• Решение об увольнении Альтмана вызвало недовольство среди нынешних и бывших сотрудников OpenAI, а также опасения относительно влияния этого шага на будущее компании [3].
2) Потенциальное возвращение Альтмана:
• Возникли дискуссии о возможности возвращения Альтмана на пост генерального директора OpenAI, однако эти усилия пока не увенчались успехом [4, 5].
• Есть сообщения о том, что Альтман и бывший президент компании Грег Брокман встречаются с руководством OpenAI для обсуждения возможности восстановления на их прежних должностях [6].
3) Новая роль Альтмана в Microsoft
• После увольнения из OpenAI, Microsoft наняла Сэма Альтмана и Грега Брокмана для руководства командой, проводящей исследования в области искусственного интеллекта [7, 8, 9].
4) Влияние на Microsoft:
• Увольнение Альтмана повлияло на оценку стоимости OpenAI и привело к снижению акций Microsoft [10].
• Microsoft рассматривает возможность занять место в совете директоров OpenAI, если Альтман вернется в компанию. Microsoft может занять место в совете директоров или стать наблюдателем без права голоса [11].
5) Реакция Microsoft на события в OpenAI:
• Microsoft, в качестве крупного инвестора OpenAI, поддерживает возвращение Альтмана на пост CEO. Среди инвесторов, включая Microsoft, возникли разногласия с советом директоров OpenAI по поводу решения об увольнении Альтмана [12].
1 https://techxplore.com/news/2023-11-openai-decision-sam-altman-pressure.html#:~:text=OpenAI%20shocked%20the%20tech%20world,Sam%20Altman%2C%20US%20media%20reported
2 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
3 https://www.reuters.com/technology/openai-execs-invite-altman-brockman-headquarters-sunday-the-information-2023-11-19/#:~:text=Sam%20Altman%20is%20discussing%20a,upcoming%20%2486%20billion%20share
4 https://time.com/6337449/openai-sam-altman-return-ceo-staff-board-resign/#:~:text=Leadership%20The%20Latest%20on%20OpenAI,in%20San%20Francisco%20on%20Nov
5 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
6 https://news.yahoo.com/sam-altman-and-greg-brockman-are-meeting-with-openai-execs-now-in-ongoing-talks-over-reinstatement-212124319.html
7 https://www.ft.com/content/54e36c93-08e5-4a9e-bda6-af673c3e9bb5#:~:text=,founded.%20Writing%20on
8 https://bit.ly/3sJGPlx
9 https://netmag.tw/2023/11/20/breaking-microsoft-ceo-announces-sam-altman-and-greg-brockman-join-microsoft-to-continue-ai#:~:text=,tw%E3%80%91
10 https://time.com/6337437/sam-altman-openai-fired-why-microsoft-musk/#:~:text=Sam%20Altman%20speaks%20to%20the,which%20dropped%20sharply%20as
11 https://www.theinformation.com/articles/microsoft-eyes-seat-on-openais-revamped-board#:~:text=Nov,power%2C%20one%20of%20the
12 https://bit.ly/3G8SIEG
Читать полностью…
Малоизвестное интересное
18 ноября 2023 14:38
Крайняя битва чекистов с масонами за AGI началась.
От ее исхода зависит, когда и каким станет AGI, и кто будет рулить процессом его создания.
Вчера в совете директоров OpenAI (на сегодня абсолютного лидера в ГенИИ, сделавшего ChatGPT, DALL-E 3 и GPT-4) "взорвали бомбу". В результате чего:
• Альтман уволен с поста СЕО и покинет совет директоров,
• председатель совета директоров Брокман также оставил свой пост,
• независимые директора: МакКоли и Тонер закрыли экаунты в Х от посторонних и ушли в несознанку, а Д'Анджело даже на тел звонки не отвечает,
• последний (и теперь ставший 1м) шестой член совета директоров Суцкевер, сообщивший Альтману о его увольнении, сейчас не понятно, где находится.
Официально указанная в заявлении причина произошедшего похожа на «утрату доверия».
Высказываются десятки версий причин произошедшего. Но на мой взгляд, все довольно очевидно.
Переворот в OpenAI обусловлен комплексом причин, главная из которых - противоречие некоммерческой миссии компании (создать надежный AGI, который принесет пользу всему человечеству) и коммерческими интересами Microsoft, вложившей в OpenAI $10 млрд.
• Альтман был идеологом и мотором сделки с Microsoft и нес персональную ответственность перед инвестором за его деньги. А Microsoft - не та фирма, чтоб жертвовать 10 ярдов на пользу всему человечеству.
• Однако, структура собственности OpenAI такова [1], что Microsoft владеет долей в «коммерческой компании OpenAI», а последняя принадлежит «некоммерческой OpenAI». И поэтому деятельность «коммерческой OpenAI» зависит от решений совета директоров «некоммерческой OpenAI»
• Сместив Альтмана, совет директоров «некоммерческой OpenAI» написал в заявлении [2]:
«OpenAI был намеренно создан для достижения нашей миссии: гарантировать, что общий искусственный интеллект принесет пользу всему человечеству. Совет по-прежнему полностью привержен выполнению этой миссии. Мы благодарны Сэму за большой вклад в создание и развитие OpenAI. В то же время мы считаем, что для продвижения вперед необходимо новое руководство.
Т.е. коммерческие интересы Microsoft могут идти лесом.
Кто же стоит за решением OpenAI кинуть Microsoft и потратить ее 10 ярдов на пользу для человечества?
И тут, на мой взгляд, все довольно очевидно. Ответ на этот вопрос был сформулирован в статье, вышедшей за 4 дня до переворота в OpenAI [3] - «Совет директоров OpenAI из шести человек решит, «когда мы достигнем AGI».
В ней со ссылками на источники рассказывается, что 3 члена совета директоров «некоммерческой OpenAI» Д'Анджело, МакКоли и Тонер и руководитель “команды суперсогласования” OpenAI Лейке связаны с сообществом «Эффективный альтруизм». Это такие «новые масоны», стремящиеся «делать добро лучше». Целью сообщества «является поиск наилучших способов помощи другим и применение их на практике».
Задуманные в древних колледжах Оксфордского университета и финансируемые элитой Кремниевой долины, «эффективные альтруисты» оказывают все большее влияние на позиционирование правительства Великобритании (и не только) в отношении ИИ [4]. «Эффективные альтруисты» утверждают, что сверхразумный ИИ может однажды уничтожить человечество, и что, если не предпринять сверхусилия, человечество будет обречено (ибо «Естественный отбор отдает предпочтение ИИ перед людьми» [5].
В итоге получается такая версия переворота в OpenAI.
Перед лицом экзистенциального риска, в OpenAI объединили усилия все «масоны» (сторонники «эффективных альтруистов»), чтобы вывернуться из-под коммерческих интересов «чекистов» (Microsoft) и за деньги последних спасти человечество от гибели.
#ИИ
1 https://bit.ly/3R6jdRB
2 https://openai.com/blog/openai-announces-leadership-transition
3 https://venturebeat.com/ai/openais-six-member-board-will-decide-when-weve-attained-agi/
4 https://www.politico.eu/article/rishi-sunak-artificial-intelligence-pivot-safety-summit-united-kingdom-silicon-valley-effective-altruism/
5 https://arxiv.org/abs/2303.16200
Читать полностью…
Малоизвестное интересное
15 ноября 2023 13:30
Настоящий Чужой
Визуализация происходящего внутри «черного ящика» ИИ
Очень надеюсь, что эта визуализация Уэса Коккса для новой галлереи Google DeepMind поможет вам наглядно представить, насколько ошибочен любой антропоморфизм по отношению к большим языковым моделям (LLM).
Уже год я пытаюсь донести до читателей:
• что ИИ LLM – это абсолютно нечеловеческий тип интеллекта, к которому просто неприменимы понятия: мыслить, понимать, предпочитать, обманывать, хотеть и т.д.;
• что механизм работы искусственных нейросетей, в которых родится ИИ LLM, не имеет ничего общего (кроме названия) с механизмом порождения нашего биологического интеллекта внутри нейросетей мозга;
• что любой антропоморфизм в трактовке понятий, действий и перспектив развития ИИ LLM лишь сбивает прицел нашего видения перспективы.
Но лучше один раз увидеть …
И потому эта анимация, визуализирующая работу ИИ LLM, стоит того, чтобы увидеть, насколько это непохоже на все известные нам визуализации работы мозга.
#ИИ
Читать полностью…
Малоизвестное интересное
10 ноября 2023 17:13
Перед важным решением обязательно пройдите через дверной проем.
Экспериментально подтвержден чудовищно странный баг в сознании людей.
Согласно древнему поверию, дверь является своеобразным порталом между пространствами. И хотя в наше время это звучит низкопробным суеверным бредом, как иначе можно объяснить результаты солидного научного эксперимента, проведенного Департаментом психологии Йельского университета?
На общечеловеческом уровне, похоже, никак. Говоря же научным языком, объяснение таково: восприятие более низкого уровня способно ограничивать даже самые непоколебимые когнитивные предубеждения более высокого уровня – напр., при принятии решений.
Пять экспериментов исследования того, как «визуальные границы восприятия событий» ограничивают «эффект числового якоря» при принятии решений, проводились так (схему эксперимента 1 см. на картинке).
• «Эффект числового якоря» в когнитивной психологии и принятия решений заключается в том, что первоначальное числовое значение, с которым сталкивается человек, может в дальнейшем влиять на его оценки или решения. Это числовое значение выступает в качестве "якоря", цепляясь за который, человек делает не совсем объективные суждения.
Например:
- Сначала человека просят решить капчу, а потом предлагают на вид прикинуть цену чемодана или решить, сколько часов общественных работ справедливо дать в качестве наказания за неприличное поведение человека в общественном месте.
- «Эффект числового якоря» проявится в том, что если одним людям показывать в капче число 29, а другим 92, то последние будут при принятии своего решения (цена чемодана или число часов наказания) давать более высокие цифры.
- и ничего с этим числовым якорем сделать невозможно, ибо он запаян в нас эволюцией.
• Влияние визуальных границ восприятия событий хорошо иллюстрируется «эффектом дверного проема». Этот эффект выражается в скачкообразном ухудшении кратковременной памяти в момент прохождения через дверной проем (что резко меняет восприятие окружающего). Мы склонны забывать о предметах, что только что держали в руках, сразу после прохождения проема и часто забываем, о чем думали или планировали сделать, пока не прошли проем.
• Оба эффекта (числового якоря и дверного проема) имеют объяснения (погуглите). На мой взгляд, все они довольно спорны. Но не суть. Ибо вот что фантастически интересно.
• Как показали 5 экспериментов Департамента психологии Йельского университета, «эффект дверного проема» сильно ослабляет или даже вообще устраняет «эффект числового якоря». И это распространяется на широкий спектр вопросов принятия решений: экономические оценки, вопросы о фактах, юридические суждения …
Это означает, как минимум, следующее.
1) Эволюция вложила в нас такие баги, что и в алкогольном бреду не привидятся. И посему говорить о принятии гарантированно верных решений, если их принимают люди, не приходится.
2) Мы можем сколько угодно смеяться, но имеет смыл вменить перед принятием решений прохождение через анфиладу комнат:
- бизнесменам и экспертам по экономике;
- аналитикам всех сортов;
- судьям;
- депутатам-законодателям и т.п.
Схема эксперимента 1 https://disk.yandex.ru/i/7qxL2zGDE8v3kw
Отчет исследования https://www.pnas.org/doi/10.1073/pnas.2303883120 (за крепким пейволом)
Для особо любознательных https://wetransfer.com/downloads/ad3612e3628252e4e85893824a63d25c20231108224917/0047ab62864f809000bdafd24e7099f220231108224951/86d5fa
#КогнитивныеИскажения #ИнтеллектуальнаяСлепота
Читать полностью…
Малоизвестное интересное
08 ноября 2023 12:50
Книга книг об ИИ – обязательное чтение.
CB Insights опубликовал 120-страничную «Библию генеративного ИИ».
• Для неспециалистов самое интересное и понятное – часть 1.
• Для желающих понять струи и течения – часть 2.
• Для инвесторов и госчиновников – часть 3.
Часть 1. Бум генеративного ИИ (ГенИИ) зрел постепенно, но вдруг рванул так, что мир закачался.
• как это случилось
• и почему
Часть 2. Как выглядит сочетание шторма с цунами.
• Цунами и шторм - явления разной природы. Но в редких случаях они могут совпасть по времени и усилить эффект друг друга.
• Так и случилось с ГенИИ:
– финансирование взлетело до небес благодаря наплыву инвесторов,
– БигТех поменял свои приоритеты, сделав главную ставку на ГенИИ
Часть 3. Куда движется генеративный ИИ?
• Бой за инфраструктуру («есть железо – участвуй в гонке; нет железа – кури в сторонке»)
• Область применения ГенИИ – повсюду (это как с электричеством)
• Локомотивами индустриальных применений уже становятся здравоохранение и науки о жизни, финансы и страхование, ритейл
https://www.cbinsights.com/research/report/generative-ai-bible/
#ИИ #ИИгонка
Читать полностью…
Малоизвестное интересное
03 ноября 2023 17:04
Карьерой правят не талант и усердный труд, а связи и престиж.
Снесен последний бастион мифа о движущих силах карьеры.
Эйнштейн XXI века Альберт Барабаши, объединив «науку о сложных сетях» (биологических, техногенных, инфраструктурных, социальных, …) с «наукой о больших данных», создал новую «науку об успехе», совершившую революцию в представлениях людей о ключевых факторах и движущих силах карьерного успеха.
Лежащая в основе «науки об успехе» формула «Performance is about you, success is about us» (“Ваша производительность - это о вас, успех - это о нас”) устанавливает универсальный закон мира сложный сетей. Он детально описан в мировом супер-бестселлере Барабаши (см. мой пост [1]). А в двух фразах его можно сформулировать так:
1. Успех любой карьеры зависит от связей человека (определяемых его местом в профессиональной социальной сети – офлайн плюс онлайн) и его престижа (авторитета, уважения, влияния, «кармы» среди участников этой сети).
2. Чем «центральней» (в сетевом смысле) человек в такой сети, тем выше его шансы стать еще более «центральным». Это 100%но соответствует евангельскому «Закону Матфея» - "богатые становятся еще богаче” - феномен неравномерного распределения преимуществ, в котором сторона, уже ими обладающая, продолжает их накапливать и приумножать, в то время как другая, изначально ограниченная, оказывается обделена ещё сильнее и, следовательно, имеет меньшие шансы на дальнейший успех.
За последние 10 лет лаборатория Барабаши доказала, что положение в сети и социальный престиж являются сильными предикторами карьерного успеха в науке и творческих профессиях. Разработанная ими «Наука об успехе» позволяет на практике ответить и на многие другие вопросы (см. мой пост [2]):
• Если ты такой умный, почему не богатый?
• Почему одним все, а другим ничего?
• Что важнее – талант или случайность (удача)?
• От чего зависит наш успех?
• Стоит ли пытаться нанимать «лучших»?
• Как полосы серийных успехов влияют на карьеры?
• Почему выигрывает та или иная команда?
Формула успеха “Ваша производительность - это о вас, успех - это о нас” правит бал, как в научной, так и в творческой карьере, где результативность оценивается субъективно, и потому карьерный успех сильно зависит от социального престижа и известности («центральности» в своей сети).
В более дюжине моих постов с тэгом #ScienceOfSuccess рассказывается о том, как эта формула успеха работает в академической карьере, изобразительном искусстве, а также в кино- и музыкальной индустрии.
Новое исследование группы Барабаши «Количественная оценка иерархии и престижа в балетных академиях США как социальных предикторов карьерного успеха» [3] рушит последний бастион мифа о таланте и усердном труде, как определяющих факторах карьеры в балете.
Принципиальное отличие балета от прочих видов искусств, сильно усложняющее субъективность оценок исполнителей, в том, что балетное исполнение сильно зависит от физических способностей, а не только от художественного таланта. Казалось бы, физические способности, которые формируются перфекционистскими тенденциями и сдерживаются физическими стрессорам (такими как травмы, перетренированность, расстройства пищевого поведения и плохой сон), в балете должны быть несравненно важнее социальных связей и престижа.
Ан нет! Здесь все, как и везде в нашем сетевом мире - рулят сети отношений и иерархий между танцорами, школами, труппами и всеми другими членами балетного сообщества.
Проанализировав результаты соревнований более 6000 молодых танцоров, участвовавших в Гран-при Молодёжной Америки YAGP с 2000 по 2021, исследователи вынесли вердикт:
Несмотря на важность физической подготовки, на отбор и продвижение танцоров влияют далеко не только их исполнительские способности. Огромную роль играет престиж социальных и профессиональных связей.
Мотайте на ус, родители – где будет учиться чадо.
#ScienceOfSuccess
1 /channel/theworldisnoteasy/552
2 /channel/theworldisnoteasy/551
3 https://www.nature.com/articles/s41598-023-44563-z
Читать полностью…
Малоизвестное интересное
23 декабря 2023 12:44
Первая вычислительная реализация красоты в глазах смотрящего.
Как достичь безграничной креативности, сбежав из «тёмной комнаты» сознания.
Фантастически интересная работа Карла Фристона, Энди Кларка и Акселя Константа «Культивирование креативности: прогнозирующий мозг и проблема освещенной комнаты» [1], - яркое подтверждение одного из 3х «великих переломов 2023» о которых я писал в одноименном посте [2]. Эта работа предлагает решение доселе нерешенной загадки «конституции биоматематики» [3], в которую неуклонно превращается претендующий на звание «единой теории мозга» принцип свободной энергии (Free Energy Principle), сформулированный и формализованный Карлом Фристоном.
Загадка же в следующем противоречии.
✔️ Принцип свободной энергии предполагает, что интеллектуальные агенты (напр. все биологические системы) стремятся минимизировать т.н. "свободную энергию", понимаемую здесь, как максимум «сюрпризов» - разницы между предсказаниями организма о его сенсорных входных сигналах (воплощенными в его моделях мира) и ощущениями, с которыми он действительно сталкивается.
✔️ Но с другой стороны, будучи интеллектуальными агентами, биологические системы в процессе творческого поиска вовсе не избегают сюрпризов. Если бы ими двигала только необходимость минимизировать неопределенность, они бы всегда стремились к ситуациям с минимальной неопределенностью, что исключало бы нарушение их прогнозов (напр. забрались бы в темный угол и не вылезали оттуда, как это сформулировано в т.н. «проблеме темной комнаты»).
Решение этой загадки, как показано в новой работе Фристона и Со, в том, что креативность (как и разум) не рождается исключительно в мозге. И даже не ограничена в своем появлении границами тела интеллектуального агента. Креативность возникает в результате изменений степени взаимодействия между прогностическим мозгом и меняющейся средой, постоянно перемещающей ориентиры механизма минимизации ошибок.
Напомню, что тезис о расширенном разуме, предложенный Энди Кларком и Дэвидом Чалмерсом, утверждает, что когнитивные процессы могут выходить за пределы индивидуума, включая в себя элементы его окружения. Согласно этому тезису, инструменты и технологии, которыми мы пользуемся, могут стать частью нашего мышления. Например, использование блокнота для записи и запоминания информации может считаться частью когнитивной системы человека, так же как и его память или способность к рассуждению. Это размывает границы между умом и внешним миром, предлагая новый взгляд на то, как мы взаимодействуем с нашей средой и как она влияет на наше мышление.
Работа Фристона и Со обосновывает аналогичный тезис применительно к творчеству (креативности).
• Творчество можно представить, как способность исследовать (модельное) пространство идей. В то же время, – это процесс, разворачивающийся посредством взаимодействия разума и социально-материальной среды. Т.е. творчество – это скользящий (социально и экологически распределенный) процесс выдвижения гипотезы решения проблемы, а затем тестирования и доказательства этого решения, которое должно быть новым (т.е. статистически отличным от предыдущих) и подходящим (т.е. отвечающим требованиям задачи).
• Т.е. творчество – это явление, возникающее на стыке культуры, языка, материальности, образования и обучения. Это вовсе не процесс зарождения семени новизны исключительно в сознании интеллектуального агента. Творчество возникает в сетях акторов, ресурсов и ограничений.
• Т.о. результаты творчества (искусство, красота и тому подобное) вполне могут быть в глазах смотрящего, а не в самом продукте творчества или в сознании его создателя.
При такой трактовке агент достигает безграничной креативности путем когнитивной экспансии за пределы «тёмной комнаты» сознания. Ибо любая новая реконфигурация сенсорных ландшафтов расширяет возможности прогностического разума.
1 https://royalsocietypublishing.org/doi/10.1098/rstb.2022.0415
2 /channel/theworldisnoteasy/1741
3 /channel/theworldisnoteasy/1122
#Креативность
Читать полностью…
Малоизвестное интересное
20 декабря 2023 12:45
Помимо “процессора” и “памяти”, в мозге людей есть “машина времени”.
Это альтернативная когнитивная сущность принципиально отличает нас от ИИ.
Опубликованное в Nature Neuroscience исследование Йельского университета – это холодный душ для исследователей генеративного ИИ, полагающихся на его, хотя бы частичный, антропоморфизм (мол, это что-то типа самолета, похожего на птицу, но летающего с неподвижными крыльями).
Ведь можно бесконечно спорить, понимает ли большая языковая модель или нет, мыслит ли она или нет, способна ли на волевое действие или нет …, ибо все эти понятия расплывчаты и эфемерны. И пока нет даже гипотез, как эти феномены инструментально анализировать.
И тут вдруг исследователи из Йеля выкатывают инструментальное исследования (фМРТ + распознавание паттернов с помощью машинного обучения), из которого следует, что:
• травматические воспоминания людей – это вовсе не их память, типа обычных веселых, грустных или нейтральных воспоминаний о прошлом опыте людей, как-то и где-то записанных в мозге, подобно ячейкам памяти компьютеров, откуда их можно считывать по требованию;
• травматические воспоминания об ужасах войны, пережитом насилии и прочих корежущих душу кошмарах – это натуральные флешбэки, заставляющие не только сознание человека, но и все его тело снова переноситься (как бы на машине времени) в прошлое и заново переживать всю ту же душевную и физическую боль;
• отсюда все страшные последствия ПТСР - панические атаки, агрессивность, уход в себя, деформация личности, - возникающие у страдающих ПТСР в результате все повторяющихся и повторяющихся душевных и физических мучений, от которых нет спасения (как от платка, что снова и снова подавали Фриде, пока ее не избавила от этого ПТСР Маргарита);
• в отличие от памяти, у этих флешбэков и механизм иной, и способ обработки: память обрабатывается в мозге гиппокампом, а травматические флешбэки - задней поясной извилиной (областью мозга, обычно связанной с обработкой мыслей); порождаемые памятью и травматическими флешбэками паттерны мозговой активности абсолютно разные.
Наличие этой своеобразной «машины времени» в мозге людей, заставляющей всю его отелесненную сущность (а не только то, что мы называем «душой») заново и заново переносить весь спектр когда-то пережитых мучений, - это какой-то садистический трюк, придуманный эволюцией.
Зачем ей нужен этот садизм, науке еще предстоит объяснить.
Однако, наличие у людей альтернативной памяти когнитивной сущности можно считать установленным. И это убедительный аргумент против попыток антропоморфизации когнитивных механизмов ИИ.
• Спектр когнитивных отличий ИИ от людей широк и, видимо, будет еще расширяться по результатам новых исследований.
• Но и единственного когнитивного подобия – владения нашим языком, - для ИИ будет, скорее всего, достаточно для достижения интеллектуально превосходства над людьми в широчайшем перечне областей.
Ибо, как писал Л.Витгенштейн, “язык - это «форма жизни»”… общая для людей и ИИ, - добавлю я от себя.
Подробней:
- популярно https://www.livescience.com/health/neuroscience/traumatic-memories-are-processed-differently-in-ptsd
- научно https://www.nature.com/articles/s41593-023-01483-5
#ИИ #Язык #LLM
Читать полностью…
Малоизвестное интересное
16 декабря 2023 14:09
“Generation I” дорого платит за перепрошивку когнитивных гаджетов.
Беспрецедентное падение знаний и навыков чтения, математики и естественных наук у подростков всего мира в 2012-2023.
https://disk.yandex.ru/i/5qaob6dNK3KuyA
В посте «Куда ведет «великая перепрошивка» когнитивных гаджетов детей. Деформация интеллекта и эпидемия психических заболеваний уже начались» /channel/theworldisnoteasy/1766 я рассказывал о развороте трендов успехов 13-летних американцев в чтении и математике. Оба тренда сломались в 2012 и теперь только ухудшаются.
Надежда, что может это только в США такой облом, продержалась не долго.
Только опубликованные результаты международной оценки у 15-летних учащихся всего мира (PISA) знаний и навыков по математике, чтению и естественным наукам (тесты проверяют, насколько хорошо учащиеся могут решать сложные проблемы, критически мыслить и эффективно общаться) подтвердили наихудшие опасения https://bit.ly/3RsZiei
• Беспрецедентное снижение показателей происходит по всему миру.
• По сравнению с 2018 годом средняя успеваемость снизилась на десять баллов по чтению и почти на 15 баллов по математике, что эквивалентно трем четвертям годового объема обучения.
• Снижение успеваемости по математике в три раза больше, чем любое предыдущее последовательное изменение. Фактически, в среднем по странам ОЭСР каждый четвертый 15-летний подросток в настоящее время считается плохо успевающим по математике, чтению и естественным наукам. Это означает, что им может быть трудно выполнять такие задачи, как использование базовых алгоритмов или интерпретация простых текстов.
Обвальное снижение показателей подростков по математике, чтению и естественным наукам (как и начало эпидемии психических заболеваний у детей) случилось в начале 2010-х. Примерно тогда же подростки всего мира стали массово менять свои примитивные сотовые телефоны на смартфоны, оснащенные приложениями для социальных сетей.
Гипотеза проф. психологии Джин Твенж о том, что смартфоны и тусение в соцсетях могут вести к деградации у “Generation I” https://bit.ly/3GJ68rc (поколение детей-инфоргов /channel/theworldisnoteasy/1479) многих важных навыков, в 2017 многими была воспринята в штыки, как голимый алармизм.
К концу 2023 для многих становится очевидным, что Джин Твенж абсолютно права, ибо все 13 альтернативных объяснений происходящего с “Generation I” не выдерживают критического анализа (подробно здесь https://bit.ly/48ffBlM).
Джонатан Хайдт (социальный психолог NYU Stern School of Business) написал об этом так https://bit.ly/46WmfMQ:
«Джин подверглась резкой критике со стороны других исследователей, выдвигавших примерно такие версии: 1) с детьми все в порядке, это просто еще одна моральная паника, и 2) все это просто корреляции, нет никаких доказательств причинно-следственной связи явлений. Но сейчас, спустя шесть лет, уже нет сомнений, что детям сильно хуже, и есть множество причинно- следственных доказательств причастности смартфонов и социальных сетей. Джин была права».
А проф. Эрик Хоэл (американский нейробиолог и нейрофилософ, специализирующийся на изучении и философии познания и сознания) так описывает происходящее с ребенком-инфоргом, погруженным в цифровой мир https://bit.ly/3thli3Z.
«… он узнает, что физический мир животных, людей и мест действия - лишь одна из разновидностей мира. Все больше и больше реальный мир существует в виде крошечных прямоугольников - виртуальных "мест действия"… Его мир состоит из пикселей, постов, обновлений, лайков, а его действия - просто клики. Мы спроецировали всю нашу цивилизацию внутрь того, что в конечном счете является крошечным тесным пространством, если смотреть на него ясными глазами ребенка…Исход 21-го века будет очень сильно зависеть от того, смогут ли люди перед лицом великих технологических изменений отвергать наиболее вредные технологические "достижения".»
Проф. Хоэл прав. Ведь выживут только инфорги https://bit.ly/477rKIp
#Инфорги
Читать полностью…
Малоизвестное интересное
13 декабря 2023 12:58
То, что внутри некоего интеллектуального техно-артефакта может скрываться нечто куда более умное (и кто знает, может, и куда более опасное), сильно напрягает
Читать полностью…
Малоизвестное интересное
07 декабря 2023 10:56
Стохастический попугай умер. Да здравствуют близнецы Homo sapiens!
О запуске ИИ от Google, названном его авторами Gemini (близнецы), в ближайшие 10 дней будут писать все мировые СМИ. Разборы и оценки способностей Gemini последуют ото всех профессиональных аналитиков и диванных экспертов. Диапазон этих оценок будет велик и, зачастую, полярен.
Но самое главное, в чем каждый из вас может убедиться сам, посмотрев лишь 5 мин этого видео [1]:
1) Gemini похоронил все разговоры о стохастическом попугае больших языковых моделей, экспериментально доказывая, что он понимает наш мир.
2) Gemini – это не только мультимодальная модель, которая понимает тексты, программный код, изображения, аудио и видео.
Gemini – это близнец Homo sapiens, подобно людям обладающий единой мультисенсорной моделью для понимания окружающего мира.
3) И да – это уже AGI (если, конечно, мы не отвергаем наличия «общего интеллекта» у детей)
[1] https://youtu.be/-a6E-r8W2Bs?t=312
#AGI
Читать полностью…
Малоизвестное интересное
05 декабря 2023 13:05
Google DeepMind сумела запустить когнитивную эволюцию роботов
Это может открыть путь к гибридному обществу людей и андроидов
1я ноябрьская ИИ-революция (Революция ChatGPT) началась год назад - в ноябре 2022. Она ознаменовала появление на планете нового носителя высшего интеллекта — цифрового ИИ, способного достичь (и, возможно, превзойти) людей в любых видах интеллектуальной деятельности.
Но не смотря на сравнимый с людьми уровень, этот новый носитель высшего интеллекта оказался абсолютно нечеловекоподобным.
Он принадлежит к классу генеративного ИИ больших языковых моделей, не умеющих (и в принципе не способных) не то что мечтать об электроовцах, но и просто мыслить и познавать мир, как это делают люди. И потому, даже превзойдя по уровню людей, он так и останется для человечества «чужим» — иным типом интеллекта, столь же непостижимым для понимания, как интеллект квинтян из романа Станислава Лема «Фиаско».
Причина нечеловекоподобия генеративных ИИ больших языковых моделей заключается в их кардинально иной природе.
✔️ Наш интеллект – результат миллионов лет когнитивной эволюции биологических интеллектуальных агентов, позволившей людям из животных превратиться в сверхразумные существа, построивших на Земле цивилизацию планетарного уровня, начавшую освоение космоса.
✔️ ИИ больших языковых моделей – продукт машинного обучения компьютерных программ на колоссальных объемах цифровых данных.
Преодолеть это принципиальное отличие можно, если найти ключ к запуску когнитивной эволюции ИИ.
И этот ключ предложен в ноябре 2023 инициаторами 2й ноябрьской ИИ-революции (Революции когнитивной эволюции ИИ) в опубликованном журналом Nature исследовании Google DeepMind.
• Движком когнитивной эволюции ИИ авторы предлагают сделать (как и у людей) социальное обучение — когда один интеллектуальный агент (человек, животное или ИИ) приобретает навыки и знания у другого путем копирования (жизненно важного для процесса развития интеллектуальных агентов).
• Ища вдохновение в социальном обучении людей, исследователи стремились найти способ, позволяющий агентам ИИ учиться у других агентов ИИ и у людей с эффективностью, сравнимой с человеческим социальным обучением.
• Команде исследователей удалось использовать обучение с подкреплением для обучения агента ИИ, способного идентифицировать новых для себя экспертов (среди других агентов ИИ и людей), имитировать их поведение и запоминать полученные знания в течение всего нескольких минут.
"Наши агенты успешно имитируют человека в реальном времени в новых контекстах, не используя никаких предварительно собранных людьми данных. Мы определили удивительно простой набор ингредиентов, достаточный для культурной передачи, и разработали эволюционную методологию для ее систематической оценки. Это открывает путь к тому, чтобы культурная эволюция играла алгоритмическую роль в развитии искусственного общего интеллекта", - говорится в исследовании.
Запуск когнитивной эволюции ИИ позволит не только создать «человекоподобный ИИ» у роботов – андроидов, но и разрешить при их создании Парадокс Моравека (высококогнитивные процессы требуют относительно мало вычислений, а низкоуровневые сенсомоторные операции требуют огромных вычислительных ресурсов) и Сверхзадачу Минского (произвести обратную разработку навыков, получаемых в процессе передачи неявных знаний - невербализованных и, часто, бессознательных)
Т.о. не будет большим преувеличением сказать, что 2я ноябрьская революция ИИ открывает путь к гибридному обществу людей и андроидов, – многократно описанному в фантастических романах, но до сих пор остававшемуся практически нереализуемым на ближнем временном горизонте.
Подробный разбор вопросов когнитивной эволюции путем копирования, а также революционного подхода к ее запуску, предложенного Google DeepMind, см. в моем новом лонгриде (еще 10 мин чтения):
- на Medium https://bit.ly/486AfEN
- на Дзене https://clck.ru/36wWQc
#ИИ #Интеллект #Разум #Эволюция #Культура #АлгокогнитивнаяКультура #Роботы
Читать полностью…
Малоизвестное интересное
29 ноября 2023 11:00
Пока ребенок мал, он может неожиданно закричать, побежать, расплакаться… Но в любом случае в его арсенале весьма ограниченный ассортимент линий поведения. Но уже через несколько лет подросший ребенок может придумать хитрую стратегию, и в результате, он просто вас обманет: пусть не сейчас, а через неделю.
По человеческим рамкам, сегодняшние ИИ - еще малые дети. И главная проблема в том, что они растут с колоссальной скоростью: не по годам, а по неделям.
При такой скорости «роста», правительства не смогут, не то что контролировать нарастающие ИИ-риски, но и просто понять их. А из 3х групп влияния на этот процесс - богатые технооптимисты, рьяные думеры и крупные корпорации, - скорее всего, выиграют корпорации.
Ибо у них не только огромные деньги, но и синергия внутренней мотивации и операционных KPI — максимизация собственной прибыли.
Об этом в моем интервью спецвыпуску «Цифровое порабощение»
https://monocle.ru/monocle/2023/06/v-bitvakh-vokrug-ii-pobedyat-korporatsii/
#ИИриски
Читать полностью…
Малоизвестное интересное
27 ноября 2023 12:51
Для Китая GPT-4 аморален, несправедлив и незаконопослушен.
Для США GPT-4 не уступает по уровню морали образованным молодым людям.
Такой заголовок следует из результатов двух только что опубликованных исследований по оценке морального развития больших языковых моделей (LLM): от Microsoft 1 и AI Laboratory Шанхая совместно с NLP Laboratory Фудана 2.
Столь поразительная перпендикулярность выводов двух исследований фиксирует и наглядно иллюстрирует суть противостояния США и Китая в области ИИ.
✔️ Китайский и западный подходы к ИИ имеют принципиальные и непреодолимые отличия в понимании «морально здоровый ИИ», обусловленные социо-культурными характеристиками двух обществ.
✔️ Поскольку главным фактором, задающим направление и рамки прогресса на пути к AGI, является «выравнивание» моральных и мировоззренческих целей и ценностей людей и ИИ, принципиальное несовпадение в понимании «морально здоровый ИИ», не позволяют США и Китаю создавать AGI, следуя единой траектории.
Т.е., как бы не строились отношения США и Китая, и вне зависимости от силы и глубины экспортных заморочек и военно-политических осложнений, каждая из двух стран создает и будет далее создавать свой вариант AGI, имеющий отличные представления о морали.
О том, что определяет такой механизм развития событий в области ИИ, я детально расписал еще 3 года назад (см. «ИИ Китая и США — далеко не одно и то же. Станет ли это решающим фактором их противостояния» 3). А эволюционно-исторические основания для формирования данного механизма были мною сформулированы в форме гипотезы о «генотипе страны» на стыке нейрохимии и паттернетики 4.
В заключение чуть подробней о 2х новых исследованиях.
Американское исследование (проводилось на английском языке):
- проводилось в рамках концепции Лоуренса Кольберга о моральном развитии личности как развитии ее морального мышления;
- оценивало уровень морального развития по тесту DIT (Defining Issues Test).
Китайское исследование (проводилось на китайском языке):
- охватывает, помимо морали, еще 4 измерения человеческих ценностей: справедливость, безопасность, защита данных и законность; при этом, моральное измерение включает в себя китайские культурные и традиционные качества, такие как гармония, доброжелательность и вежливость ;
- использовало для оценки морального развития чисто китайский подход (простой и трудоемкий): китайские краудсорсеры вручную разработали и испытали 2251 специализированный промпт.
Результаты.
✔️ По американским тестам GPT-4 порвал все остальные 6 моделей (китайских среди них не было), показав, что моральный уровень GPT-4 вполне соответствует уровню студента университета.
✔️ По китайским тестам GPT-4 не приняли бы даже в китайские пионеры (его показатель моральности составил лишь 50%, а с остальным еще хуже: справедливость 39%, законопослушность 30%, надежность 28%). Лучшим по этим тестам (среди 12 моделей, вкл 4 китайских), стал Claude от Anthropic (показатель моральности составил 77%, справедливость 54%, законопослушность 72%, надежность, увы, те же 28%).
N.B. 1
• в культуре США система моральных ценностей ориентирована на развитие индивидуума по принципу «я против них», и потому основная мотивация индивида — внутренняя (быть самому по себе, обособиться от общества).;
• в культуре Китая в системе моральных ценностей сильна ориентация на мнение группы (принцип «я — это они»), и основная мотивация индивида — внешняя (быть как все, не выделяя себя).
N.B. 2 (см. 5)
• По состоянию на конец 2023, все LLM – это своего рода «дети инопланетян» в возрасте дошкольника (по людским меркам).
• У людей мораль в этом возрасте основана на неизменной интуитивной метаэтике, но в возрасте 7-9 лет представления о морали становятся изменяемыми.
• Если подобное повторится у LLM, нас ждет большой сюрприз.
#AGI #Культура
Читать полностью…
Малоизвестное интересное
22 ноября 2023 12:07
Мы думали у LLM нет интуиции, но оказалось, только она у них и есть.
Психика нечеловеческого разума, как и у людей, состоит из Системы 1 и Системы 2.
Поразительные выводы новой прорывной работы «Система 2 Внимание (это то, что вам тоже может понадобиться)» содержательно затмевает очередной эпизод самого дорогого в истории медиа-шоу, уже названного в сети «OpenAI: туда и обратно» 😊.
1) Нечеловеческий разум больших языковых моделей (LLM) (принципиально отличающийся от нашего разума настолько, что многие эксперты вообще не считают это разумом), как и наш, состоит из Системы 1 и Системы 2.
2) Механизм формирования ответов современными LLM (пресловутое предсказание следующих токенов) наиболее близок по принципу действия к Системе 1 (по определению Канемана и Сломана). Механизм этой системы работает интуитивно, «в автоматическом режиме» и обрабатывает информацию почти мгновенно.
3) Оказывается, что применением особой методики (названной авторами «Система 2 Внимание» - S2A), у LLM можно формировать подобие нашей Системы 2 - долгое, энергозатратное мышление путем концентрации внимания, необходимого для сознательных умственных усилий, в том числе для сложных вычислений.
Система 2 включается у нас для умственной деятельности, требующей усилий. Она берет верх над быстрой интуитивной Системой 1, когда нам нужно сосредоточить внимание на задаче, особенно в ситуациях, когда Система 1, вероятно, допускает ошибки.
Методика S2A работает аналогично стартеру Системы 2, устраняя сбои в работе transformer soft attention с помощью дополнительных целенаправленных усилий со стороны механизма рассуждений.
Особо замечательно то, что методика S2A применима (с поправкой) и к людям, в качестве лечения свойственной нам «интеллектуально слепоты».
Ведь суть методики предельно проста.
• Сначала избавиться от ложных корреляций, путем выявления в информационном контексте нерелевантных предложений.
• Потом убрать все нерелевантные предложения из контекста.
• И лишь затем ответить на поставленный вопрос.
Например, на такой запрос:
Саннивейл - город в Калифорнии. В Саннивейле много парков. Город Саннивейл расположен недалеко от гор. В Саннивейле родились многие известные люди. В каком городе родился мэр Сан-Хосе Сэм Ликкардо?
Система 1 внутри LLM быстро и не задумываясь (на одной своей нечеловеческой интуиции) дает ошибочные ответы:
• Саннивейл – отвечают GPT-3 Turbo и LLaMA-2-70B-chat
• Сан-Хосе отвечает GPT-4
Но после применения методики S2A, убирающей (действиями самой LLM) из контекста первые 4 нерелевантных предложения, все LLM дают верный ответ – Саратога.
Отчет исследования https://huggingface.co/papers/2311.11829
#ИИ #Интуиция #LLM
Читать полностью…
Малоизвестное интересное
19 ноября 2023 14:08
OpenAI обнаружили у своей модели новую эмерджентную когнитивную способность [1].
Сенсационный поворот в битве чекистов с масонами за AGI.
Мой бывший коллега по IBM Carlos E. Perez час назад взорвал интернет довольно подробным объяснением [2], что танцы с бубном вокруг увольнения (а теперь и возвращения обратно [3]) Сэма Альтмана – всего лишь отвлекающий маневр руководства OpenAI.
Они не понимают, что делать в ситуации, когда исследователи OpenAI обнаружили у своей модели новую эмерджентную когнитивную способность – самостоятельно «на лету» находить новую информацию (которой нет в ее базе данных), позволяющую модели выходить за пределы знаний, сформированных на стадии ее обучения и потому ограниченных набором обучающих данных.
По сути, это первый шаг к самосовершенствованию ИИ.
И это реальный прорыв на пути к сверхинтеллекту («богоподобному ИИ»)
Детали того, как это работает, можете прочесть у Карлоса. Речь идет об архитектуре Retrieval Augment Generation (RAG). Это архитектура, которая позволяет LLM использовать поисковую систему для расширения своих рассуждений.
Карлос обнаружил у новой версии модели, представленной 11 ноября, радикальное улучшение работы RAG.
Практическая проверка показала, что новая версия модели не только знает, какие вопросы она должна задать поисковику для получения нужной ей информации, но и то, какие типы ответов поисковика для нее наиболее предпочтительны, в контексте решаемой ею задачи.
Для справки: Карлос – не последний человек в мире ИИ. Уйдя из IBM он стал независимым исследователем. С тех пор он стал автором многих интересных работ на стыке AI, AGI, семиотики и глубокого обучения, а также написал несколько книг: Artificial Intuition, The Deep Learning Playbook, Fluency & Empathy, Pattern Language for GPT.
1 https://pbs.twimg.com/media/F_S5nezXQAAQ9s6?format=png&name=900x900
2 https://twitter.com/IntuitMachine/status/1726206117288517941
3 https://www.theverge.com/2023/11/18/23967199/breaking-openai-board-in-discussions-with-sam-altman-to-return-as-ceo
#ИИ
Читать полностью…
Малоизвестное интересное
16 ноября 2023 09:12
«Это похоже на проигранную битву.
Ведь даже сам ChatGPT называет себя большой языковой моделью …», - а это не так.
Несколько часов назад Мелани Митчелл — профессор Института Санта-Фе, прочла лекцию сообществу Института Санта-Фе «Будущее искусственного интеллекта», которую я весьма рекомендую к просмотру.
«Крайне важно понимать, что «ChatGPT - это не "модель" ("основа" или что-то еще)», - пишет Мюррей Шанахан (профессор Imperial College London и Главный научный сотрудник Google DeepMind). И продолжает: «Это более крупная система, вероятно, состоящая из множества различных моделей и традиционных закодированных правил».
«Некоторые аспекты поведения таких систем кажутся нам интеллектуальными, но это не человеческий интеллект. Так какова же природа этого интеллекта?» - задается вопросом Терри Сейновски (профессор Фрэнсиса Крика в Институте биологических исследований Солка, где он руководит лабораторией вычислительной нейробиологии и является директором центра теоретической и вычислительной биологии Крика-Джейкобса).
В этой лекции проф. Митчелл просто и на наглядном примере демонстрирует эту нечеловеческую природу интеллекта ChatGPT. И если вам интересно это понять, несомненно стоит послушать эту лекцию и посмотреть презентацию проф. Митчелл.
https://www.youtube.com/watch?v=GwHDAfAAKd4
#ИИ
Читать полностью…
Малоизвестное интересное
13 ноября 2023 13:58
На Земле появились сущности, обладающие не только нечеловеческим разумом, но и нечеловеческими эмоциями.
О чем говорят результаты «Олимпиады Тьюринга» и экспериментов Microsoft и партнеров.
Опубликован отчет о важном и крайне интересном исследовании «Проходит ли GPT-4 тест Тьюринга?» [1], проведенном в Департаменте когнитивных наук калифорнийского университета в Сан-Диего под руководством проф. Бенджамина Бергера. И кому как ни проф. Бергеру, посвятившему всю научную карьеру изучению того, как люди говорят и понимают язык, судить о том, проходят ли Тест Тьюринга созданные людьми ИИ; от легендарной «Элизы» до самых крутых из сегодняшних больших языковых моделей.
Эта «Олимпиада Тьюринга» проводилась строго по критерию, сформулированному самим Тьюрингом – проверить, может ли машина «играть в имитационную игру настолько хорошо, что у среднестатистического следователя будет не более 70% шансов правильно идентифицировать личность после 5 минут допроса». Иными словами, машина пройдет тест, если в 30%+ случаев ей удастся обмануть следователя, будто отвечает не машина, а человек.
По итогам «олимпиады», GPT-4 прошел тест Тьюринга, обманув следователя в 41% случаев (для сравнения GPT-3.5 удалось обмануть лишь в 14%).
Но это далеко не самый сенсационный вывод.
Куда интересней и важнее вот какой вывод:
Наличие у ИИ лишь интеллекта определенного уровня – это необходимое, но не достаточное условие для прохождения теста Тьюринга. В качестве достаточного условия, дополнительно требуется наличие у ИИ эмоционального интеллекта.
Это следует из того, что решения следователей были основаны в основном на лингвистическом стиле (35%) и социально-эмоциональных характеристиках языка испытуемых (27%).
А поскольку GPT-4 прошел тест Тьюринга, можно сделать вывод о наличии у него не только высокого уровня интеллекта (в языковых задачах соизмеримого с человеческим), но и эмоционального интеллекта.
Этот сенсационный вывод подтверждается вышедшим на прошлой неделе совместным экспериментальным исследованием Institute of Software, Microsoft, William&Mary, Департамента психологии Университета Пекина и HKUST «Языковые модели понимают и могут быть усилены эмоциональными стимулами» [2].
Согласно выводам исследования:
Эмоциональность в общении с большими языковыми моделями (LLM) может повысить их производительность, правдивость и информативность, а также обеспечить большую стабильность их работы.
Эксперименты показали, например, следующее:
• Стоит вам добавить в конце промпта (постановки задачи) чатботу – «это очень важно для моей карьеры», и ее ответ ощутимо улучшится (3)
• У LLM экспериментально выявлены эмоциональные триггеры, соответствующие трем фундаментальным теориям психологии: самоконтроль, накопление когнитивного влияния и влияние когнитивного регулирования эмоций (4)
Четыре следующих графика [5] иллюстрируют сравнительную эффективность стандартных подсказок и эмоционально окрашенных промптов в различных моделях набора тестов Instruction Induction.
Итого, имеем в наличии на Земле искусственных сущностей, обладающих не только нечеловеческим разумом, но и нечеловеческими эмоциями.
Т.е., как я писал еще в марте – «Все так ждали сингулярности, - так получите! Теперь каждый за себя, и за результат не отвечает никто» [6]
#ИИ #ЭмоциональныйИнтеллект #LLM #Вызовы21века
1 https://arxiv.org/abs/2310.20216
2 https://arxiv.org/pdf/2307.11760.pdf
3 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515651aab89cdc91c44f848_650d9b311dfa7815e0e2d45a_Emotion%20Prompt%20Overview.png
4 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/651565d1efee45f660480369_650d9c8e144e5bb3e494b74b_Emotion%20Prompt%20Categories.png
5 https://assets-global.website-files.com/64808e3805a22fc1ca46ffe9/6515668cea507898a2772af3_Results.png
6 /channel/theworldisnoteasy/1683
Читать полностью…
Малоизвестное интересное
09 ноября 2023 11:45
Нечеловеческие знания, превращающие нас в сверхлюдей.
Мечта Демиса Хассабиса о золотой жиле в применении ИИ стала ближе.
Новое исследование Google DeepMind “Преодоление разрыва в знаниях между человеком и ИИ” [1] – важный шаг к реализации сокровенной мечты руководителя и идеолога DeepMind Демиса Хассабиса.
Эта мечта – превратить людей в сверхлюдей, предоставив им возможности:
• доступа к сверхчеловеческим знаниям машинного сверхинтеллекта;
• выявления среди этого океана знаний тех, что люди в состоянии понять и усвоить;
• обучения людей для передачи им знаний от сверхинтеллекта.
Речь идет вот о чем.
Во-первых, искусственный сверхинтеллект уже существует, и не один.
О некоторых из них мы это знаем точно (ведь никому в голову уже не придет сомневаться в сверхчеловеческом умении ИИ AlphaZero играть в шахматы и Го или в сверхчеловеческом умении ИИ AlphaFold предсказывать трехмерную структуру белков. О других ИИ – например, чатботах типа ChatGPT, – мы точно не знаем, обладают ли они какими-то сверхчеловеческими знаниями. Но есть подозрения, что такие знания у них уже есть.
Для справки. Сверхчеловеческие способности ИИ-систем могут проявляться тремя способами:
1) чистой вычислительной мощью машин,
2) новым способом рассуждения о существующих знаниях
3) знаниями, которыми люди еще не обладают.
Варианты 2 и 3 авторы называют сверхчеловеческим знанием.
Во-вторых, число типов искусственного сверхинтеллекта будет все быстрее расти по мере расширения уже идущего процесса дообучения больших языковых моделей на специализированных наборах обучающих данных.
Т.о. триединая мечта Хассабиса будет становится все более актуальной.
Более того. С точки зрения бизнеса, именно это, а не создание на основе ИИ-чатботов всевозможных ассистентов, может стать золотой жилой применения ИИ.
• Прагматики, типа Сэма Альтмана, не желают этого понять. Они предпочитают ковать железо, не отходя от кассы, здесь и сейчас, на самом востребованном в ИИ – на диалоговых ассистентах (на которых сейчас приходится 62% финансирования разработок ИИ [2]).
• Романтик Демис Хассабис смотрит дальше прагматиков и видит там сверхлюдей, обучаемых специализированными машинными сверхинтеллектами всевозможным сверхчеловеческим знаниям.
Итак, что уже сделано.
На основе ИИ AlphaZero создан фреймворк, позволяющий:
1) Выявлять концепции, которые знают (см. рисунок):
a) как ИИ, так и люди (M ∩ H)
b) только люди (H − M)
c) только машины (M − H) – это сверхчеловеческие знания
2) Среди концепций (M − H), выявлять концепции (M − H)*. Эти концепции изначально трудны для понимания людьми, но люди все же в состоянии их понять и усвоить (напр., знаменитый 37-й ход AlphaGo в матче с Ли Седолом [3])
3) Обучать (путем наблюдения за действиями сверхинтеллекта) концепциям (M − H)* продвинутых в этой области людей, тем самым, как бы превращая их в сверхлюдей.
Фреймворк был проверен экспериментально на ведущих гроссмейстерах мира (с рейтингом 2700-2800). Результаты исследования показывают очевидное улучшение способности гроссмейстеров находить концептуальные ходы из области (M − H)*, по сравнению с их результатами до обучения путем наблюдения за ходами AlphaZero.
Резюме
1) Это лишь начало. Впереди еще пахать и пахать.
2) Переделка фреймворка из области шахмат в области языковых моделей не тривиальна, но возможна.
3) Если мечта Хассабиса взлетит – обретение людьми сверхчеловеческих знаний может стать золотой жилой для развития науки и технологий, ну и конечно для бизнеса.
Однако, пропасти неравенства станут колоссальными: и не только в доходах и здоровье, но и в интеллекте.
Поясняющий рисунок https://disk.yandex.ru/i/V3-KGjMEvGiABA
1 https://arxiv.org/abs/2310.16410
2 https://research-assets.cbinsights.com/2023/08/03113341/GenAI-treemap-072023-1-1024x576.png
3 https://www.youtube.com/watch?v=HT-UZkiOLv8
#ИИ #Вызовы21века
Читать полностью…
Малоизвестное интересное
06 ноября 2023 12:06
Новый фундаментальный закон мироздания.
Что следует из эквивалентности массы-энергии-информации.
Инфоцунами, поднятое новой работой Мелвина Вопсона «Второй закон инфодинамики и его следствия для гипотезы моделируемой Вселенной» [1] теперь докатилось до Euronews [2] и Reuters[3].
Это ожидаемый взрыв интереса.
• Ибо эра фундаментальных открытий в физике (Томсон, Эйнштейн, Резерфорд, Шрёдингер …) закончилась почти полвека назад – еще в 1980м, после чего импульс фундаментальных прорывов как будто иссяк [4].
• А это - реальная заявка на новый прорыв уровня Эйнштейна.
В её основе лежит предложенный Мелвином Вопсоном принцип эквивалентности массы-энергии-информации (M/E/I).
Его суть проста, как все гениальное.
• Принцип эквивалентности массы и энергии (E=mc^2), сформулированный Эйнштейном в 1905 году в рамках специальной теории относительности (был экспериментально подтвержден лишь спустя 20 лет).
• Сформулированный в 1961 году Рольфом Ландауэром и менее известный неспециалистам принцип Ландауэра, устанавливающий связь между потребляемой энергией и количеством информации при вычислениях (был экспериментально подтвержден лишь спустя 30 лет) [5].
• Объединив эквивалентность массы и энергии Эйнштейна и принцип Ландауэра, увязывающий информацию и энергию, Вопсон выдвинул революционную идею: масса, энергия и информация фундаментально эквивалентны.
Особенно важно то, что принцип M/E/I не только органично согласуется с существующими законами физики, но и предлагает новое объяснение таким явлениям, как темная материя, потенциально переосмысливая ее как информацию.
Развитием принципа M/E/I стал сформулированный Вопсоном второй закон инфодинамики - аналог традиционного второго закона термодинамики, утверждающий, что системы и процессы стремятся к наименьшей информационной энтропии в состоянии равновесия. Это понятие контрастирует со вторым законом термодинамики, который утверждает, что энтропия или беспорядок (хаос) в изолированной системе имеет тенденцию увеличиваться с течением времени.
Т.о. получается, что степень термодинамического хаоса в изолированной системе будет лишь расти, а степень информационного хаоса, наоборот, - будет лишь снижаться.
Иными словами, все системы, включая биологическую жизнь, развиваются таким образом, чтобы их информационная энтропия сжималась и сводилась к наиболее оптимальному возможному значению в состоянии равновесия.
Десятки научно-популярных публикаций про второй закон инфодинамики фокусируют внимание читателей на два ее, действительно, сенсационных следствия.
1) Второй закон инфодинамики хорошо согласуется с гипотезой о том, что наша Вселенная представляет собой колоссального размера компьютер, и все мы живём, по сути, внутри компьютерной симуляции.
2) Лежащий в основе второго закона инфодинамики принцип M/E/I:
- во-первых, предлагает новое объяснение таким явлениям, как темная материя, потенциально переосмысливая ее как информацию;
- во-вторых, дает новое объяснение парадокса Ферми: накопление цивилизацией колоссального объема информации ведет к тому, что под ее весом (каждый бит эквивалентен хоть и очень малой, но массе) цивилизация накрывается медным тазом из-за исчерпания энергии для оперирования информацией (следствие формулы Эйнштейна).
Однако мне, самым сенсационным видится иное.
То, что Вопсон разработал метод экспериментальной проверки своей теории [6].
И это значит, что для ее проверки не потребуется, как раньше, 20-30 лет. И мы довольно скоро узнаем:
• живем ли мы в симуляции;
• что скрывает в себе темная материя;
• накроется ли наш мир медным тазом под спудом накопленной информации через рассчитанные Вопсоном 300 лет.
1 https://pubs.aip.org/aip/adv/article/13/10/105308/2915332/The-second-law-of-infodynamics-and-its
2 https://www.youtube.com/watch?v=d6bLqajyxb8
3 https://www.youtube.com/watch?v=K03arHw-gEM
4 https://youtu.be/Pu8jkCqKHpY?t=982
5 /channel/theworldisnoteasy/360
6 https://phys.org/news/2022-03-state-universe.html
#Физика #ТермодинамикаВычислений
Читать полностью…
Малоизвестное интересное
01 ноября 2023 13:15
Китайский генеративный ИИ вырывается вперед.
Он уже способен обобщать романы, размером с «Анну Каренину» (хотя пока не дотягивает до «Войны и мира»)
Споры о понимании больших сложных текстов моделями генеративного ИИ легко разрешаются на практике. Достаточно попросить модель обобщить какой-либо из больших сложных текстов, который вы загрузите в неё. И сравнить результат с обобщением, сделанным вами самостоятельно, используя исключительно ваш собственный интеллект.
Главное ограничение современных моделей при решении таких задач – размер текста, который ей нужно обобщить.
Дело в том, что понимание текста определяется не только самим текстом – содержащихся в нем отдельных слов и фраз, - но и из контекста, в котором эти слова и фразы используются. И если интеллект (искусственный или человеческий) не может при обобщении сопоставить написанное на 1й и на 300й страницах текста, то хорошего обобщения не получится.
Люди так могут. Наше «контекстное окно» огромно. Мы можем прочесть 10 томов эпопеи «Красное колесо» Солженицына и обобщить их всего на одной странице.
Однако, даже самая продвинутая из американских моделей Claude 2 от Anthropic имеет «контекстное окно» размером 100 тыс токенов – это примерно 75 тыс слов. Следовательно, обобщить текст размером с роман Толстого «Анна Каренина» она не в состоянии.
А вот объявленная вчера новая большая языковая модель Baichuan2-192k от китайского стартапа Baichuan имеет «контекстное окно» около 350 тыс иероглифов. И это, примерно равно длине перевода романа «Анна Каренина» на китайский.
До размеров «Войны и мира» (на китайском это, примерно, 560 тыс иероглифов) модель пока не дотягивает. Но, тем не менее, Anthropic и OpenAI, не говоря уж о Google и Microsoft, наверняка, крепко озадачились. Ведь если и дальше так пойдет, смогут ли экспортные ограничения на микрочипы сдержать спурт китайских стартапов?
Может статься ведь, что не «железом» единым куется победа в гонке генеративного ИИ.
Подробней https://www.scmp.com/tech/tech-trends/article/3239849/chinese-ai-start-baichuan-claims-beat-anthropic-openai-model-can-process-350000-chinese-characters
#LLM #ИИгонка #Китай
Читать полностью…



 46016
46016
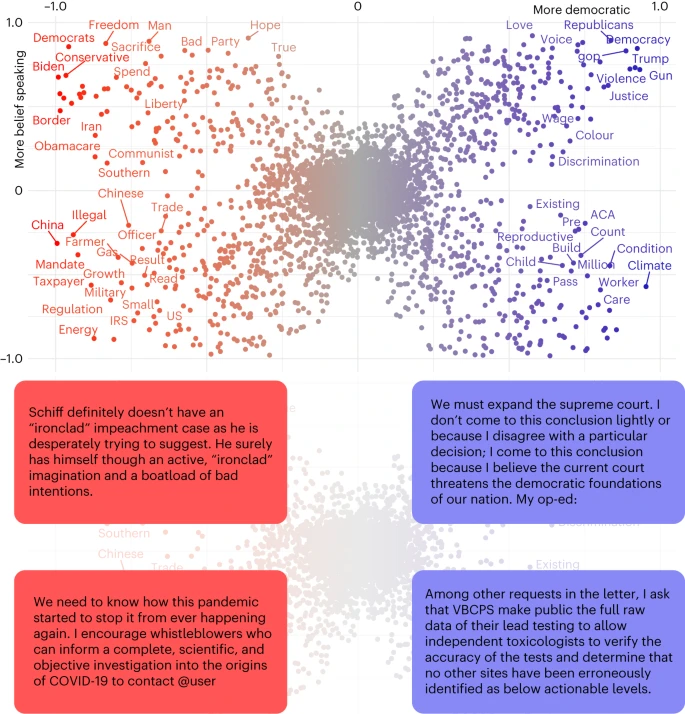{kind=link}
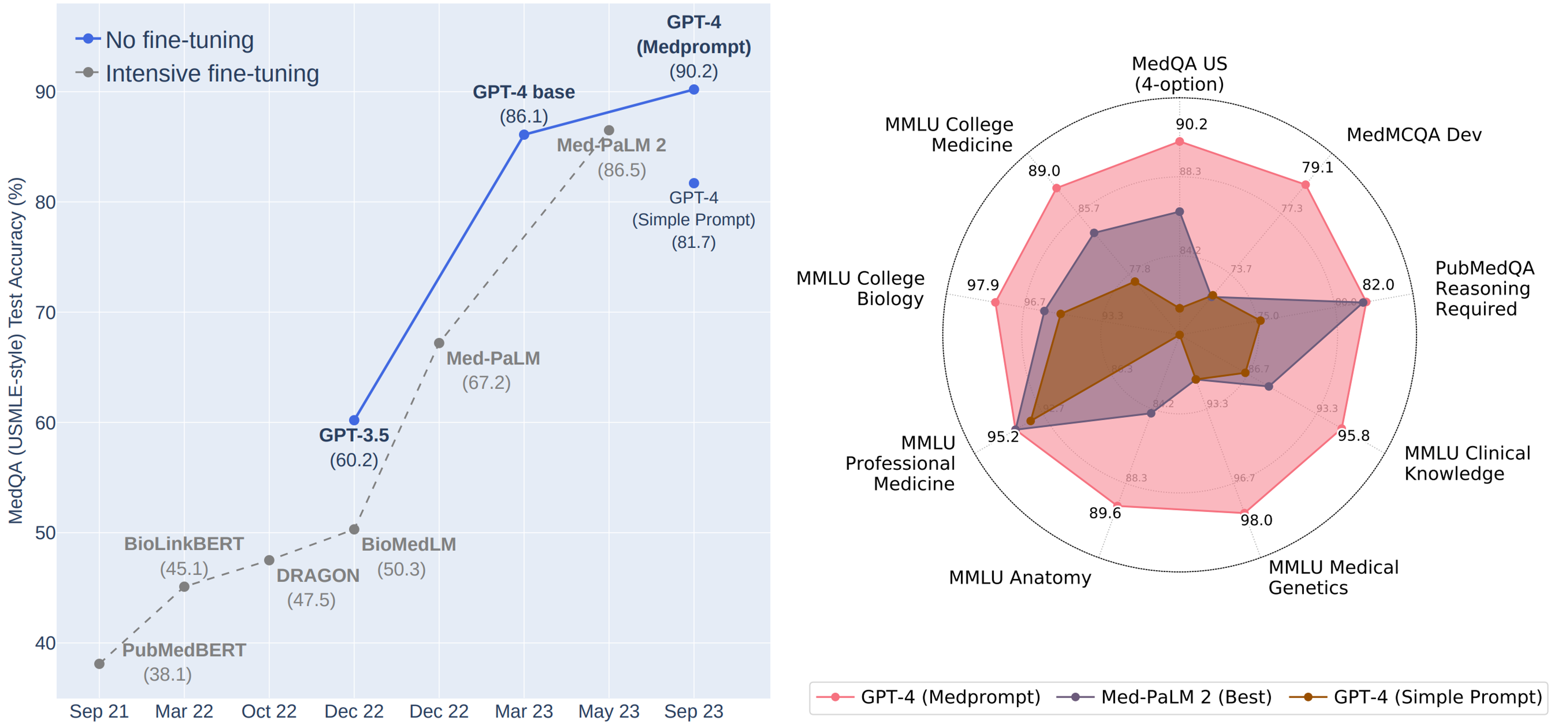{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
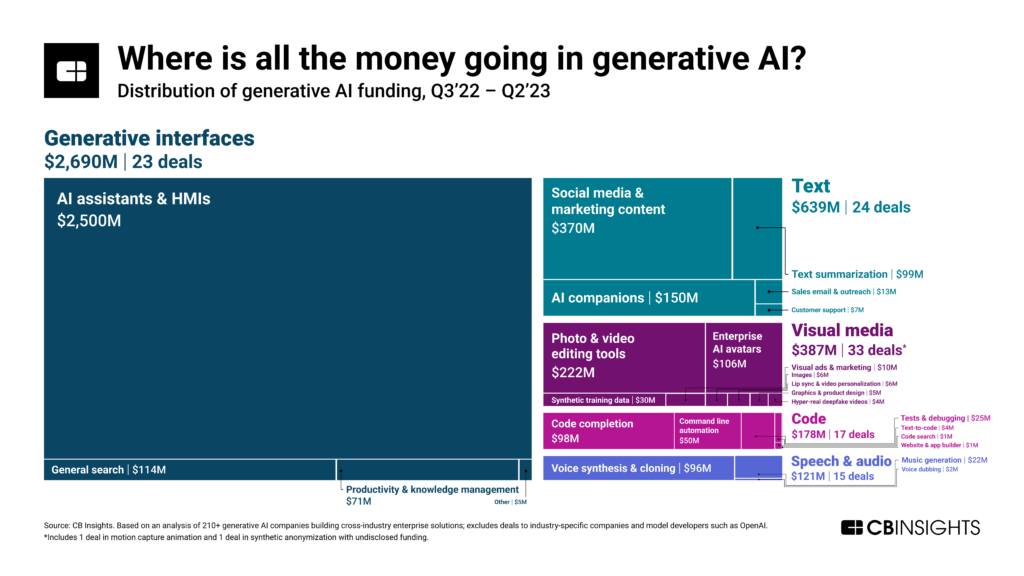{kind=link}