Python Daily
01 September 2024 09:30
Sunday Daily Thread: What's everyone working on this week?
# Weekly Thread: What's Everyone Working On This Week? 🛠️
Hello /r/Python! It's time to share what you've been working on! Whether it's a work-in-progress, a completed masterpiece, or just a rough idea, let us know what you're up to!
## How it Works:
1. Show & Tell: Share your current projects, completed works, or future ideas.
2. Discuss: Get feedback, find collaborators, or just chat about your project.
3. Inspire: Your project might inspire someone else, just as you might get inspired here.
## Guidelines:
Feel free to include as many details as you'd like. Code snippets, screenshots, and links are all welcome.
Whether it's your job, your hobby, or your passion project, all Python-related work is welcome here.
## Example Shares:
1. Machine Learning Model: Working on a ML model to predict stock prices. Just cracked a 90% accuracy rate!
2. Web Scraping: Built a script to scrape and analyze news articles. It's helped me understand media bias better.
3. Automation: Automated my home lighting with Python and Raspberry Pi. My life has never been easier!
Let's build and grow together! Share your journey and learn from others. Happy coding! 🌟
/r/Python
https://redd.it/1f617a7
Читать полностью…
Python Daily
31 August 2024 20:30
Is My CI Pipeline for my Python Library Overkill?
So this is what my GitHub insights are looking like:
|Date|Clones|Unique Clones|
|:-|:-|:-|
|29 Aug|1376|16|
|30 Aug|1326|9|
The majority of this is just my CI pipeline.
This is a snippet of the strategy section of the CI:
strategy:
matrix:
python-version: "3.8", "3.9", "3.10", "3.11", "3.12"
django-version: 32, 42, 51
db: postgres, mysql, sqlite
broker: rabbitmq, kafka
exclude:
# Django 5.1 does not support Python <3.10
- python-version: "3.8"
django-version: 51
- python-version: "3.9"
/r/Python
https://redd.it/1f5qlui
Читать полностью…
Python Daily
31 August 2024 15:30
Automate Your Reddit Saved Post Backups with Context Using Reddit Stash
Hey Everyone,
**What My Project Does**
A while back, I realized that many of the posts I had saved on Reddit for future reference were disappearing. To solve this problem, I developed a Python script called **Reddit Stash**. This tool automatically saves your Reddit saved posts and comments, along with your own posts and comments, and includes the necessary context (e.g., associated comments or parent posts). The script runs daily at around 00:00 CET using GitHub Actions, ensuring your data is backed up without any manual intervention on Dropbox. The files are saved in Markdown format, making them easy to read and reference later.
**Target Audience**
**Reddit Stash** is ideal for users who want to preserve their saved Reddit content without losing context, such as those interested in:
* **Personal Knowledge Management:** Users who save Reddit posts for later reference and want to ensure they keep the full context for future use.
* **Developers/Researchers:** Those planning to use Reddit content in local Retrieval-Augmented Generation (RAG) systems or similar projects.
* **Casual Reddit Users:** Anyone who doesn’t want to worry about manually backing up their saved content.
Whether you're a serious developer or a casual Reddit user, this tool can save you time and effort.
**Comparison**
While there are existing tools
/r/Python
https://redd.it/1f5n53a
Читать полностью…
Python Daily
31 August 2024 07:30
A write-up of what's new in pip 24.2 — or why legacy editable installs are deprecated
Hi all,
**Link to post.**
Last time I was here, I was speaking with my maintainer of black hat. I no longer wear that hat. Earlier this year, I've joined the pip triage team.
About a month ago, we released pip 24.2. This release included neat improvements and one important deprecation (the deprecation of legacy `setup.py develop` based editable installs. setup.py itself is not deprecated). While the changelog is an accurate summary of the changes, the changelog is often hard to parse if you aren't already experienced in packaging and it simply lacks a lot of detail, too. So, I thought a post discussing the changes in detail would be useful and interesting. I tried my best to strike a balance between including the technical details where I could, but also explaining things in a way where you didn't have to be a tenured packaging expert to understand everything 🙂
This isn't anything official. pip doesn't have a blog, and I'm linking to my personal site here, but I do think it's valuable to have more detailed communications for a foundational piece of the packaging ecosystem. I make no promises that this will continue, but I'd love to write future pieces if I can.
Please
/r/Python
https://redd.it/1f4zvaw
Читать полностью…
Python Daily
31 August 2024 05:30
D Monthly Who's Hiring and Who wants to be Hired?
For Job Postings please use this template
>Hiring: [Location\], Salary:[\], [Remote | Relocation\], [Full Time | Contract | Part Time\] and [Brief overview, what you're looking for\]
For Those looking for jobs please use this template
>Want to be Hired: [Location\], Salary Expectation:[\], [Remote | Relocation\], [Full Time | Contract | Part Time\] Resume: [Link to resume\] and [Brief overview, what you're looking for\]
​
Please remember that this community is geared towards those with experience.
/r/MachineLearning
https://redd.it/1f5cy0v
Читать полностью…
Python Daily
31 August 2024 00:30
Kazam 2.0 is released: screen recording, broadcasting, capturing and OCR in Linux
https://github.com/henrywoo/kazam
Kazam 2.0 is a versatile tool for screen recording, broadcasting, capturing and optical character recognition(OCR) with AI in mind.
🍄 Tested in: Ubuntu 20.04, 22.04, and 24.04 with Python 3.8 - 3.12.
Main Features:
1. Screen Recording: Kazam allows you to capture everything displayed on your screen and save it as a video file. The recorded video is saved in a format compatible with any media player that supports H264, VP8 codec and WebM video format.
2. Broadcasting: Kazam offers the ability to broadcast your screen content live over the internet, making it suitable for live streaming sessions. It supports Twitch and Youtube live broadcasting at the time of this writing.
3. Optical Character Recognition (OCR): Kazam includes OCR functionality, enabling it to detect and extract text from the captured screen content, which can then be edited or saved.
4. Audio Recording: In addition to screen content, Kazam can record audio from any sound input device that is recognized and supported by the PulseAudio sound system. This allows you to capture both the screen and accompanying audio, such as voice narration or system sounds, in your recordings.
5. Web Camera: Kazam support web camera recording and users can drag and drop webcam window anywhere in the screen
/r/Python
https://redd.it/1f4xjxh
Читать полностью…
Python Daily
30 August 2024 21:30
Deploying a Django app with as few moving parts as possible
https://www.bugsink.com/installation-simplification-journey/
/r/django
https://redd.it/1f4qq64
Читать полностью…
Python Daily
30 August 2024 15:30
PExploring Practical Uses of Machine Learning: How It's Revamping My Note-Taking Process
I’ve always struggled with note-taking because on one hand, I love keeping everything organized, but on the other, the constant need for categorizing and formatting just drives me nuts! Can anyone relate? I kept wishing for an AI tool that could handle all that for me, and that’s when I decided to create one myself.
I’ve come up with a basic version of the tool I dreamed up, called Stackie, because it helps me keep stacks of information organized—just type in whatever you need, and Stackie automatically sorts and structures every note (and yes, it gets natural language!).
Just the other day, I was looking into different mice for my sore wrist, popped the info into Stackie, and it neatly organized everything into my "Mouse Comparison" stack.
I’m also trying out new ways to use it, like tracking my calorie intake since I’ve put on a few pounds and want to get healthier. It’s funny how a tool I created out of laziness has turned out to be super useful.
I’m still brainstorming other ways to use Stackie and could really use some fresh ideas. So, I’d love to pick your brains and see if you can help me think outside the box. I’ve
/r/MachineLearning
https://redd.it/1f4owc0
Читать полностью…
Python Daily
30 August 2024 13:30
Ibis: Farewell pandas, and thanks for all the fish.
https://ibis-project.org/posts/farewell-pandas/
> TL; DR: we are deprecating the pandas and dask backends and will be removing them in version 10.0.
/r/Python
https://redd.it/1f41ol2
Читать полностью…
Python Daily
30 August 2024 10:30
Django API Manager
Hey guys,
I'm working on a platform that connects to a large amount of different APIs to extract different types of data. Instead of managing all those API calls from the code side. I want to manage them in the Django admin interface where I can add a button to "Add a new API connection" where I will provide details etc.. etc.. you know the drill.
Is there anything out there I could repurpose for this?
Thanks in advance!
/r/django
https://redd.it/1f4nl8p
Читать полностью…
Python Daily
30 August 2024 08:30
How to Build a Line Graph in Matplotlib | Python Data Visualization Tuto...
https://youtube.com/watch?v=tWBoDCnj5Ck&si=mE3sEVGy4Ki0Jurm
/r/IPython
https://redd.it/1f4nd6s
Читать полностью…
Python Daily
30 August 2024 05:30
Looking for freelance Django/Python Dev, how much should I pay?
Hello hello,
Not a Django dev myself but need someone with Python, Django, and API / Rest experience. I'd say probably mid-level for about \~12 hours a month, only to go up from there. Any idea on what a good hourly rate for such a freelancer would be?
/r/django
https://redd.it/1f4dkin
Читать полностью…
Python Daily
29 August 2024 23:30
Created CLI that writes your semantic commit messages in git and more.
I've created CLI, a tool that generates semantic commit messages in Git
Here's a breakdown:
What My Project Does Penify CLI is a command-line tool that:
1. Automatically generates semantic commit messages based on your staged changes.
2. Generates documentation for specified files or folders.
3. Hooks: If you wish to automate documentation generation
Key features:
`penify-cli commit`: Commits code with an auto-generated semantic message for staged files.
penify-cli doc-gen: Generates documentation for specified files/folders.
Installation: pip install penify-cli
Target Audience Penify CLI is aimed at developers who want to:
Maintain consistent, meaningful commit messages without the mental overhead.
Quickly generate documentation for their codebase. It's suitable for both personal projects and professional development environments where consistent commit practices are valued.
Comparison Github-Copilot, aicommit:
Penify CLI generates semantic commit messages automatically, reducing manual input. None does.
It integrates documentation generation, combining two common developer tasks in one tool.
Note: Currently requires signup at Penify (we're working on Ollama integration for local use).
Check it out:
PyPI: [https://pypi.org/project/penify-cli/](https://pypi.org/project/penify-cli/)
GitHub: https://github.com/SingularityX-ai/penify-cli
I'd love to hear your thoughts and feedback!
/r/IPython
https://redd.it/1f4b888
Читать полностью…
Python Daily
29 August 2024 21:30
How to add alt to img in django-summernote?
As title says. I am add blog post via admin panel. I have integrated django-summernote. I am not able to find any way to add alt tag to image uploaded inside post.
I followed this to integration https://djangocentral.com/integrating-summernote-in-django/
Thanks
/r/django
https://redd.it/1f48kyr
Читать полностью…
Python Daily
29 August 2024 18:30
2023 Python Developers Survey Results
# 2023 Python Developers Survey
Results are in for the official Python Developers Survey, conducted in partnership with JetBrains!
The survey is a joint initiative between the Python Software Foundation and JetBrains.
Read more about it here.
/r/Python
https://redd.it/1f43acl
Читать полностью…
Python Daily
01 September 2024 01:30
Modal button not working when following this Flask tutorial. Please help!
I'm following a Flask tutorial on YouTube and have hit a point where I can't get the code to work. The button doesn't pop up when I click on it. Any ideas? I have tried switching "data-toggle" to "data-bs-toggle" and likewise for "dismiss" and "target" (in line with bootstrap 5) but it doesn't work. The button doesn't do anything at all when I click on it.
Here's the button:
<button type="button" class="btn btn-danger btn-sm m-1" data-toggle="modal" data-target="#deleteModal">Delete</button>
And here's the modal:
<div class="modal fade" id="deleteModal" tabindex="-1" role="dialog" aria-labelledby="deleteModalLabel" aria-hidden="true">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h5 class="modal-title" id="deleteModalLabel">Delete Post?</h5>
<button type="button" class="close" data-dismiss="modal" aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>
<div class="modal-footer">
<button type="button" class="btn btn-secondary" data-dismiss="modal">Close</button>
/r/flask
https://redd.it/1f5xqyf
Читать полностью…
Python Daily
31 August 2024 17:30
Build plugins in marimo with anywidget
Blog post: https://marimo.io/blog/anywidget
marimo is now standardizing on anywidget as the third-party plugin API. With anywidget, users can create custom widgets to be used directly in marimo and hook into marimo's reactive framework.
Context:
marimo is a next-generation reactive notebook for Python and SQL.
anywidget provides a single interface for developing embeddable widgets inside other applications, such as Panel, Jupyter, and, of course, marimo. anywidget also comes with an excellent developer experience in creating these widgets with either vanilla JavaScript or popular frameworks like React and Svelte.
/r/Python
https://redd.it/1f56lj9
Читать полностью…
Python Daily
31 August 2024 10:30
Interpol Wanted Persons Data Downloader with an Interactive Dashboard
# What My Project Does
Interpol Red-DL is a project designed to retrieve, save and display data published by Interpol on wanted persons.
The project creates a copy of the data of wanted persons to keep the data, even if deleted by Interpol, and it also extends the features of Interpol website by adding a data visualization dashboard on top.
Github Repo
Demo Video
Demo Website*
*I have a Streamlit app deployed temporarily, using a snapshot of the database from the last complete run few weeks ago.
# Target Audience
Those who are curious about reverse-engineering APIs or data scraping. The README contains a short write-up about the challenges faced when working with the API. The project also gives some ideas for anyone into data visualization, showing how you can extend existing websites to create data dashboards with easy prototyping libraries like Streamlit.
# Comparison
Most similar open-source projects scraping Interpol's data are either outdated, likely because of stricter API checks, or they use Selenium for data extraction, which feels like an overkill.
I worked on this project as a challenge during my internship at an AI-based company. Following are some of my opinions:
Is Interpol preventing bots?
I’ve always enjoyed messing around with APIs, but this one was
/r/Python
https://redd.it/1f57h6m
Читать полностью…
Python Daily
31 August 2024 06:30
Introducing pipefunc: Simplify Your Python Function Pipelines
Excited to share my latest open-source project, pipefunc! It's a lightweight Python library that simplifies function composition and pipeline creation. Less bookkeeping, more doing!
What My Project Does:
With minimal code changes turn your functions into a reusable pipeline.
- Automatic execution order
- Pipeline visualization
- Resource usage profiling
- N-dimensional map-reduce support
- Type annotation validation
- Automatic parallelization on your machine or a SLURM cluster
pipefunc is perfect for data processing, scientific computations, machine learning workflows, or any scenario involving interdependent functions.
It helps you focus on your code's logic while handling the intricacies of function dependencies and execution order.
- 🛠️ Tech stack: Built on top of NetworkX, NumPy, and optionally integrates with Xarray, Zarr, and Adaptive.
- 🧪 Quality assurance: >500 tests, 100% test coverage, fully typed, and adheres to all Ruff Rules.
Target Audience:
- 🖥️ Scientific HPC Workflows: Efficiently manage complex computational tasks in high-performance computing environments.
- 🧠 ML Workflows: Streamline your data preprocessing, model training, and evaluation pipelines.
Comparison:
How is pipefunc different from other tools?
- Luigi, Airflow, Prefect, and Kedro: These tools are primarily designed for event-driven, data-centric pipelines and ETL processes. In contrast, pipefunc specializes in running simulations and computational workflows, allowing different parts of a calculation to run on different resources (e.g., local machine,
/r/Python
https://redd.it/1f583cp
Читать полностью…
Python Daily
31 August 2024 04:30
Saturday Daily Thread: Resource Request and Sharing! Daily Thread
# Weekly Thread: Resource Request and Sharing 📚
Stumbled upon a useful Python resource? Or are you looking for a guide on a specific topic? Welcome to the Resource Request and Sharing thread!
## How it Works:
1. Request: Can't find a resource on a particular topic? Ask here!
2. Share: Found something useful? Share it with the community.
3. Review: Give or get opinions on Python resources you've used.
## Guidelines:
Please include the type of resource (e.g., book, video, article) and the topic.
Always be respectful when reviewing someone else's shared resource.
## Example Shares:
1. Book: "Fluent Python" \- Great for understanding Pythonic idioms.
2. Video: Python Data Structures \- Excellent overview of Python's built-in data structures.
3. Article: Understanding Python Decorators \- A deep dive into decorators.
## Example Requests:
1. Looking for: Video tutorials on web scraping with Python.
2. Need: Book recommendations for Python machine learning.
Share the knowledge, enrich the community. Happy learning! 🌟
/r/Python
https://redd.it/1f5a0qh
Читать полностью…
Python Daily
30 August 2024 23:30
Optimizing Parallel Processing and other improvements along with Deployment Strategies for a Django-based Web Scraping Application
I have created a Django project with Redis and Celery in a Docker Compose setup for development. The project allows users to input a search keyword and select a country from a drop down list which is loaded initially from country model using js. Users can provide multiple search inputs and corresponding countries before submitting. After submission, a process (scraper.py) will start, extracting information from Google and Yelp searches by constructing URLs from the provided inputs using Python's requests library. This process is handled by Celery as a task. I also have a model for task status.
Additionally, I have a dashboard page that displays the status of the task. In the scraper.py file, I am using Python's multiprocessing module with a maximum of 15 workers. This allows the scraper to run in parallel when the user submits multiple sets of search and country inputs. Once the scraping is completed, a download option will be enabled on the dashboard page for the respective task, allowing users to download the resulting CSV file.
However, I’ve noticed that the parallel execution is taking more time than expected. I’m looking for the correct way to implement parallel processing efficiently.
For production, I’m considering deployment options
/r/django
https://redd.it/1f4sy58
Читать полностью…
Python Daily
30 August 2024 18:30
How to Create a 4-Digit Non-Repetitive OTP Authentication System in Django/DRF?
I was recently asked an interesting question during an interview: How would you design an authentication system that generates a 4-digit OTP without repeating any digits when a user tries to log in or sign up?
The requirements were pretty specific:
1. The OTP should be 4 digits long.
2. Each digit must be unique (no repetition of digits).
3. The OTP should be sent to the user for authentication during login or sign-up.
4. The system should be implemented using Django/DRF.
/r/django
https://redd.it/1f4s9li
Читать полностью…
Python Daily
30 August 2024 14:30
MinusX: AI assistant for Jupyter
MinusX in Action
Hey Folks!
I'm Vivek, building MinusX (https://minusx.ai) . It is an AI assistant for Jupyter. It is a chrome extension that adds a side chat to analytics apps. When you give it an instruction, it operates the tool - by clicking and typing - just like you would, to analyze data and answer queries. I was a research engineer at comma.ai (used to use jupyter everyday) for the last 3 years, and this project was born out of a personal itch.
You can inter-operate with the "agent" in your notebooks and take back control anytime. Our architecture makes the agent tool agnostic, and we're looking to support more tools!
We just did a beta release of MinusX recently. You can try it on your own data on your jupyter instances right now (https://minusx.ai/chrome-extension)! I'd love to hear any feedback you may have!
PS: We're open sourcing our entire application this week!
/r/JupyterNotebooks
https://redd.it/1f4fb95
Читать полностью…
Python Daily
30 August 2024 11:30
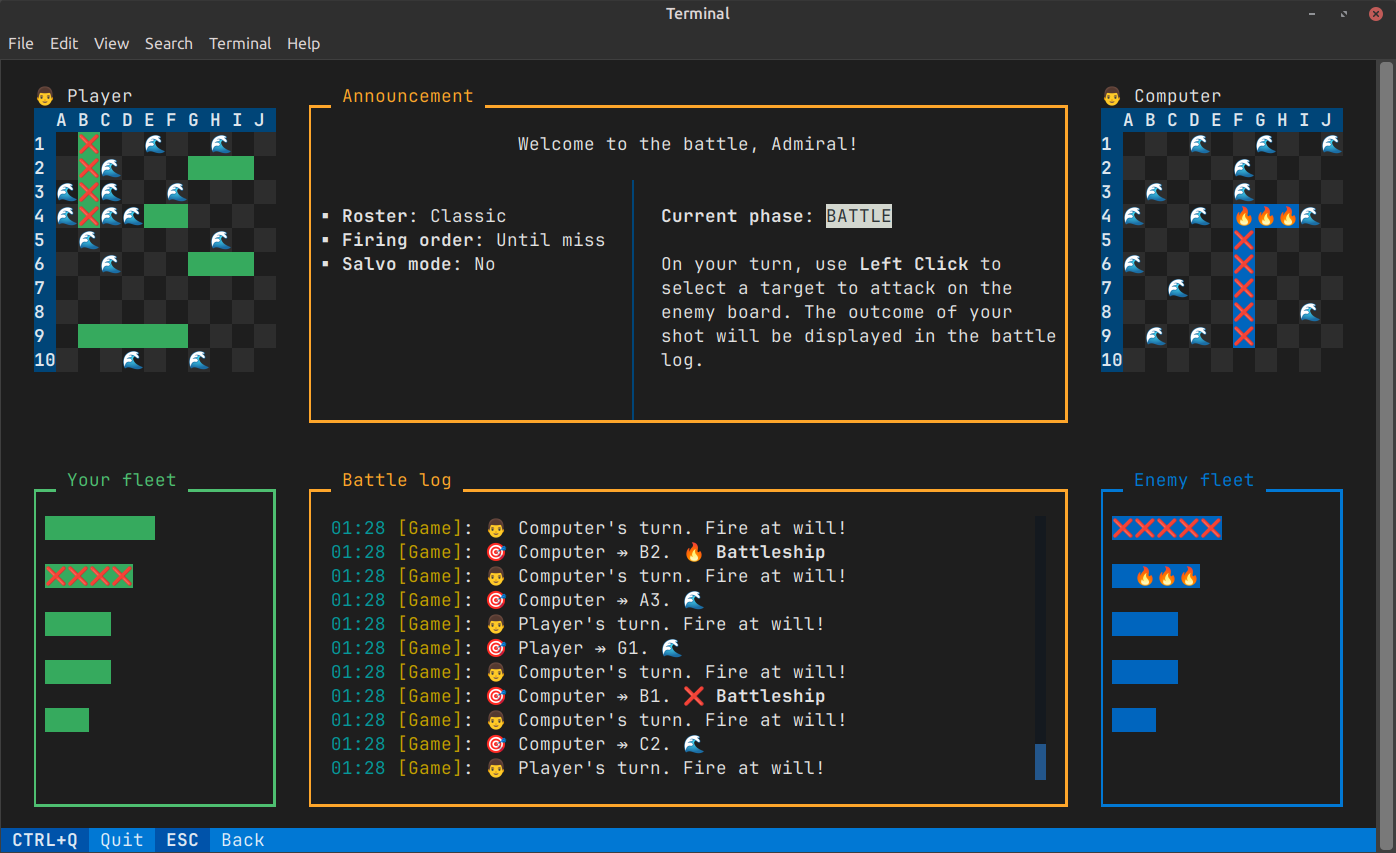
Battleship TUI: a terminal-based multiplayer game
# What My Project Does
The good old Battleship reinvented as a TUI (Text User Interface) application. Basically, you can play Battleship in your terminal. More than that, you can play via the Internet! You can also track your performance (like the shooting accuracy and the win/loss rate) and customize the UI.
Here’s a screenshot of the game screen.
# Target Audience
Anyone who’s familiar with the terminal and has Python installed (or curious enough to try it out).
# Comparison
I didn’t find other Battleship implementations for the terminal that support multiplayer mode. Looks like it’s one of a kind. Let me know if I’m wrong!
# A bit of history
The project took me about a year to get to the alpha release. When I started in August 2023 I was on a sabbatical and things were moving fast. During August and September I created most of the domain model and tinkered a bit with Textual. It took some time to figure out what components should be there, what are their responsibilities, etc.
From there it took about three weeks to develop some kind of a visual design and implement the whole UI. Working with Textual was really a joy, though coming from VueJS background I was
/r/Python
https://redd.it/1f4flrj
Читать полностью…
Python Daily
30 August 2024 09:30
Question on Macros vs Partial Templates
Hi,
Question on using macros vs partial templates.
Is there a preference or difference between the two? It seems like with the latest jinja updates, we can just pass variables to the partial template as well.
{% extends "home/home_base.html" %}
{% from "home/macros/nav_bar_macros.html" import nav_bar%}
{% block content %}
<div class="h-full">
<nav id="nav-bar" class="flex p-7 justify-between items-center">
<img src="{{ url_for('static', filename='images/logo.svg') }}">
<div>
{{ nav_bar(current_page)}}
</div>
</nav>
<div id="main-container" class="w-10/12 mx-auto mb-12">
{% include 'home/marketplace/partials/_recommended.html' with context %}
{% include 'home/marketplace/partials/_explore.html' with context %}
</div>
</div>
{% endblock %}
Per the code block above, i am using a macro for my dynamic nav bar, and also using partial templates. Both seem to do the same thing and my server can return a macro (via get_template_attribute) or just
/r/flask
https://redd.it/1f42zkf
Читать полностью…
Python Daily
30 August 2024 07:30
How to properly record and send audio data from react to flask backend
I want to send audio data from react in a interval of approx. 10sec to my flask backend. Here is my code, it is working but music format is not write.
react code snippet
useEffect(() => {
socket.connect();
function sendData(data) {
var form = new FormData();
form.append("file", data, "data.mp3");
form.append("title", "data.mp3");
axios
.post("http://127.0.0.1:5000/save-record", form, { headers })
.then((response) => {
console.log(response.data);
})
.catch((error) => {
console.error(error);
/r/flask
https://redd.it/1f4978m
Читать полностью…
Python Daily
30 August 2024 02:30
Friday Daily Thread: r/Python Meta and Free-Talk Fridays
# Weekly Thread: Meta Discussions and Free Talk Friday 🎙️
Welcome to Free Talk Friday on /r/Python! This is the place to discuss the r/Python community (meta discussions), Python news, projects, or anything else Python-related!
## How it Works:
1. Open Mic: Share your thoughts, questions, or anything you'd like related to Python or the community.
2. Community Pulse: Discuss what you feel is working well or what could be improved in the /r/python community.
3. News & Updates: Keep up-to-date with the latest in Python and share any news you find interesting.
## Guidelines:
All topics should be related to Python or the /r/python community.
Be respectful and follow Reddit's Code of Conduct.
## Example Topics:
1. New Python Release: What do you think about the new features in Python 3.11?
2. Community Events: Any Python meetups or webinars coming up?
3. Learning Resources: Found a great Python tutorial? Share it here!
4. Job Market: How has Python impacted your career?
5. Hot Takes: Got a controversial Python opinion? Let's hear it!
6. Community Ideas: Something you'd like to see us do? tell us.
Let's keep the conversation going. Happy discussing! 🌟
/r/Python
https://redd.it/1f4hgd2
Читать полностью…
Python Daily
29 August 2024 22:30
Fileuploads blocking Workers
Hello everybody,
I encountered a problem which got pretty big for my App now. Sometimes the app becomes unresponsive for a long time and will answer the request after like 50 seconds.
I think it is because a lot of users are uploading images and this blocks my gunicorn workers. Users might have a bad internet connection for example. Like this when 12 images are uploaded with bad connection and I only have 10 workers, this will cause a problem. (I also use Azure Blob Storage as my file storage)
How would you handle that?
Thank you in advance for your advice :)
/r/django
https://redd.it/1f487e9
Читать полностью…
Python Daily
29 August 2024 20:30
D Post any bginner questions to r/MLQuestions!
I have recently inherited the subreddit r/MLQuestions, as the other mods had been innactive for 10 months and 4 years respectively. I have been sprucing up the sub, adding flairs, rules, etc, and I am trying to increase engagement and make it more useful for those who want to ask questions. Basically, stackoverflow but dedicated to beginn\r questions about ML. So if any of you have questions that your are too embarrased to ask here, ask at r/MLQuestions! I will also be introducing a system similar to r/changemyview, where each question someone answers, they get an increment to their user flair that shows how many questions they have answered!
BTW the mods gave me permission to post this, so thank you guys for this, very cool.
/r/MachineLearning
https://redd.it/1f3yfjg
Читать полностью…
Python Daily
29 August 2024 16:30
Help designing model for including sem/year
I'm creating models to store questions and syllabus of different courses.
eg. program: Master of Fine Arts (MFA), courses: Sculpture, Visual arts
This is what I have in mind so far:
#django and postgresql
#from django.db import models
class Program(models.Model):
programid = models.IntegerField(unique=True)
programcode = models.CharField(maxlength=100)
programname = models.CharField(maxlength=100)
class Course(models.Model):
courseid = models.IntegerField(unique=True)
coursecode = models.CharField(maxlength=100)
coursename = models.CharField(maxlength=100)
coursecredit = models.IntegerField()
courseicon = models.CharField(maxlength=50)
program = models.ForeignKey(
Program, ondelete=models.CASCADE, relatedname="courses"
)
class Syllabus(models.Model):
course = models.ForeignKey(Course, ondelete=models.CASCADE, relatedname='syllabus')
topic = models.CharField(maxlength=100)
content = models.TextField()
hours = models.IntegerField()
/r/django
https://redd.it/1f3robj
Читать полностью…



 1102
1102
{kind=link}
{kind=link}