Data Science by ODS.ai 🦜
12 апреля 2024 10:17
🔥 ControlNet++: Improving Conditional Controls
with Efficient Consistency Feedback
Proposes an approach that improves controllable generation by explicitly optimizing pixel-level cycle consistency
proj: https://liming-ai.github.io/ControlNet_Plus_Plus/
abs: https://arxiv.org/abs/2404.07987
@
Читать полностью…
Data Science by ODS.ai 🦜
09 апреля 2024 10:06
⚡️ PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models
Significantly improved finetuned perf by simply changing the initialization of LoRA's AB matrix from Gaussian/zero to principal components.
On GSM8K, Mistral-7B fine-tuned with PiSSA achieves an accuracy of 72.86%, outperforming LoRA’s 67.7% by 5.16%.
▪Github: https://github.com/GraphPKU/PiSSA
▪Paper: https://arxiv.org/abs/2404.02948
@
Читать полностью…
Data Science by ODS.ai 🦜
05 апреля 2024 10:26
Objective-Driven AI: Towards AI systems that can learn, remember, reason, and plan
A presentation by Yann Lecun on the #SOTA in #DL
YouTube: https://www.youtube.com/watch?v=MiqLoAZFRSE
Slides: Google Doc
Paper: Open Review
P.S. Stole the post from @
Читать полностью…
Data Science by ODS.ai 🦜
02 апреля 2024 15:00
Position: Analyst/Researcher for AI Team at Cyber.fund
About Cyber.fund:
Cyber.fund is a pioneering $100mm research-driven fund specializing in the realm of web3, decentralized AI, autonomous agents, and self-sovereign identity. Our legacy is built upon being the architects behind monumental projects such as Lido, p2p.org, =nil; foundation, Neutron, NEON, and early investments in groundbreaking technologies like Solana, Ethereum, EigenLayer among 150+ others. We are committed to advancing the frontiers of Fully Homomorphic Encryption (FHE) for Machine Learning, privacy-first ML (Large Language Models), AI aggregations, and routing platforms alongside decentralized AI solutions.
Who Are We Looking For?
A dynamic individual who straddles the worlds of business acumen and academic rigor with:
- A robust theoretical foundation in Computer Science and a must-have specialization in Machine Learning.
- An educational background from a technical university, with a preference for PhD holders from prestigious institutions like MIT or МФТИ.
- A track record of publications in the Machine Learning domain, ideally at the level of NeuroIPS.
- Experience working in startups or major tech companies, ideally coupled with a background in angel investing.
- A profound understanding of algorithms, techniques, and models in ML, with an exceptional ability to translate these into innovative products.
- Fluent English, intellectual curiosity, and a fervent passion for keeping abreast of the latest developments in AI/ML.
Responsibilities:
1) Investment Due Diligence: Conduct technical, product, and business analysis of potential AI/ML investments. This includes market analysis, engaging with founders and technical teams, and evaluating the scalability, reliability, risks, and limitations of products.
2) Portcos Support: Provide strategic and technical support to portfolio companies in AI/ML. Assist in crafting technological strategies, hiring, industry networking, identifying potential project challenges, and devising solutions.
3) Market and Technology Research: Stay at the forefront of ML/DL/AI trends (e.g., synthetic data, flash attention, 1bit LLM, FHE for ML, JEPA, etc.). Write publications, whitepapers, and potentially host X spaces/streams/podcasts on these subjects (in English). Identify promising companies and projects for investment opportunities.
How to Apply?
If you find yourself aligning with our requirements and are excited by the opportunity to contribute to our vision, please send your CV to sg@cyber.fund. Including a cover letter, links to publications, open-source contributions, and other achievements will be advantageous.
Location:
Location is flexible, but the candidate should be within the time zones ranging from EET to EST (Eastern Europe to the East Coast of the USA).
This is not just a job opportunity; it's a call to be part of a visionary journey reshaping the landscape of AI and decentralized technology. Join us at Cyber.fund and be at the forefront of the technological revolution.
Читать полностью…
Data Science by ODS.ai 🦜
02 октября 2023 07:25
Well, AI can learn that humans might be deceiving.
Читать полностью…
Data Science by ODS.ai 🦜
22 сентября 2023 17:27
Hey, please boost our channel to allow us to post stories.
We solemnly swear to post only memes there.
/channel/opendatascience?boost
Читать полностью…
Data Science by ODS.ai 🦜
14 сентября 2023 06:44
TSMixer: An All-MLP Architecture for Time Series Forecasting
Time-series datasets in real-world scenarios are inherently multivariate and riddled with intricate dynamics. While recurrent or attention-based deep learning models have been the go-to solution to address these complexities, recent discoveries have shown that even basic univariate linear models can surpass them in performance on standard academic benchmarks. As an extension of this revelation, the paper introduces the Time-Series Mixer TSMixer. This innovative design, crafted by layering multi-layer perceptrons, hinges on mixing operations across both time and feature axes, ensuring an efficient extraction of data nuances.
Upon application, TSMixer has shown promising results. Not only does it hold its ground against specialized state-of-the-art models on well-known benchmarks, but it also trumps leading alternatives in the challenging M5 benchmark, a dataset that mirrors the intricacies of retail realities. The paper's outcomes emphasize the pivotal role of cross-variate and auxiliary data in refining time series forecasting.
Paper link: https://arxiv.org/abs/2303.06053
Code link: https://github.com/google-research/google-research/tree/master/tsmixer
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-tsmixer
#paperreview #deeplearning #timeseries #mlp
Читать полностью…
Data Science by ODS.ai 🦜
12 сентября 2023 18:57
Releasing Persimmon-8B
Permisimmon-8B is open-source, fully permissive model. It is trained from scratch using a context size of 16K. The model has 70k unused embeddings for multimodal extensions, and has sparse activations. The inference code combines the speed of C++ implementations (e.g. FasterTransformer) with the flexibility of naive Python inference.
Hidden Size 4096
Heads 64
Layers 36
Batch Size 120
Sequence Length 16384
Training Iterations 375K
Tokens Seen 737B
Code and weights: https://github.com/persimmon-ai-labs/adept-inference
Читать полностью…
Data Science by ODS.ai 🦜
07 сентября 2023 07:58
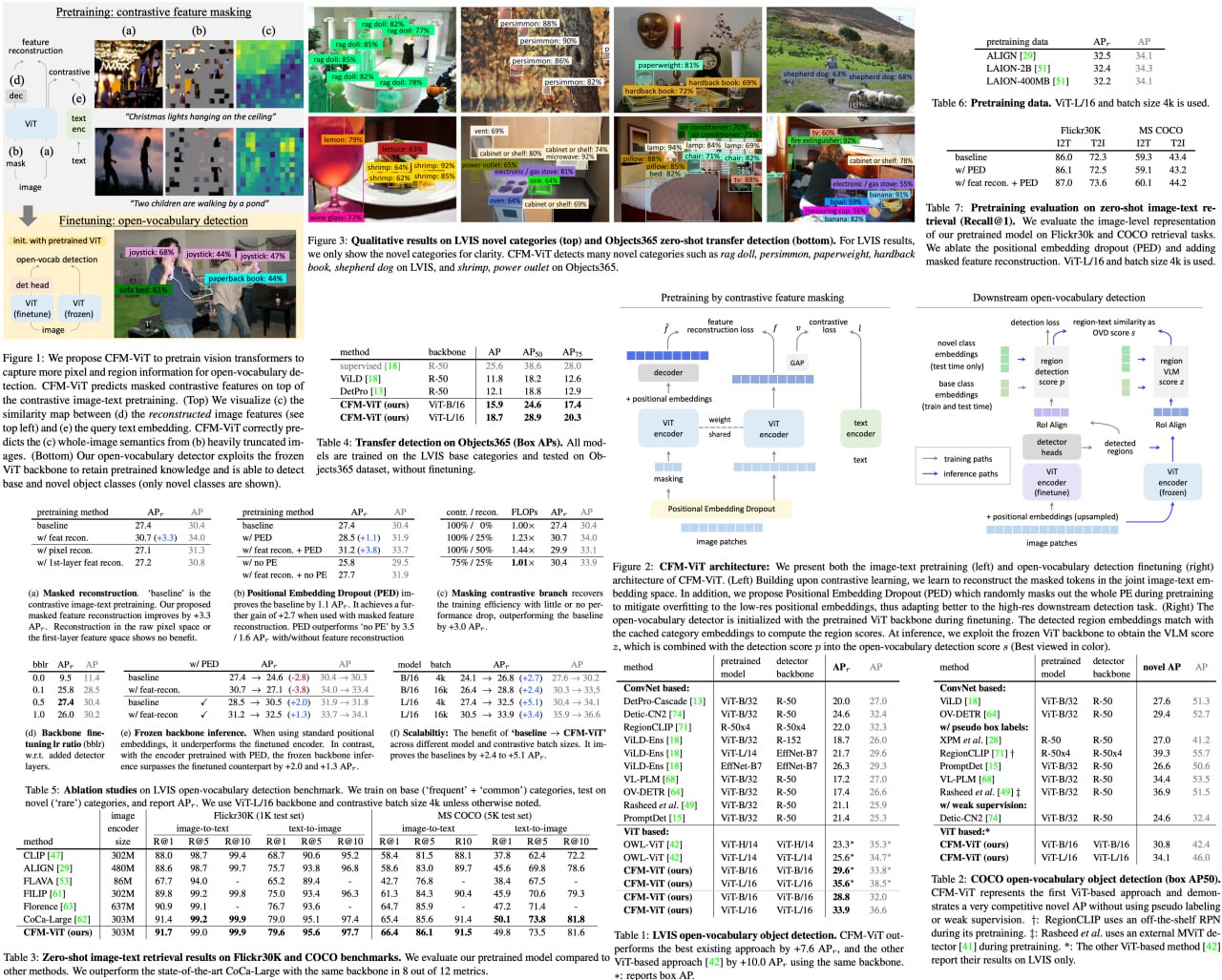
Contrastive Feature Masking Open-Vocabulary Vision Transformer
Contrastive Feature Masking Vision Transformer (CFM-ViT): a new approach for image-text pretraining that is optimized for open-vocabulary object detection. Unlike traditional masked autoencoders, which typically operate in the pixel space, CFM-ViT uses a joint image-text embedding space for reconstruction. This approach enhances the model's ability to learn region-level semantics. Additionally, the model features a Positional Embedding Dropout to better handle scale variations that occur when transitioning from image-text pretraining to detection finetuning. PED also enables the model to use a "frozen" ViT backbone as a region classifier without loss of performance.
In terms of results, CFM-ViT sets a new benchmark in open-vocabulary object detection with a 33.9 APr score on the LVIS dataset, outperforming the closest competitor by 7.6 points. The model also demonstrates strong capabilities in zero-shot detection transfer. Beyond object detection, it excels in image-text retrieval, outperforming the state of the art on 8 out of 12 key metrics. These features and results position CFM-ViT as a significant advancement in the field of computer vision and machine learning.
Paper link: https://arxiv.org/abs/2309.00775
My overview of the paper:
https://andlukyane.com/blog/paper-review-cfmvit
https://artgor.medium.com/paper-review-contrastive-feature-masking-open-vocabulary-vision-transformer-4639d1bf7043
#paperreview
Читать полностью…
Data Science by ODS.ai 🦜
02 сентября 2023 14:30
SAM-Med2D ➕
SAM-Med2D, the most comprehensive studies on applying SAM to medical 2D images.
🏆 Самая большая на сегодняшний день база данных по сегментации медицинских изображений (4,6 млн. изображений и 19,7 млн. масок) для обучения моделей.
🏆 Модель файнтюнинга Segment Anything Model (SAM).
🏆 Бенчмарк SAM-Med2D на крупномасштабных наборах данных.
🖥 Github: https://github.com/uni-medical/sam-med2d
🖥 Colab: https://colab.research.google.com/github/uni-medical/SAM-Med2D/blob/main/predictor_example.ipynb
📕 Paper: https://arxiv.org/abs/2308.16184
⭐️ Dataset: https://paperswithcode.com/dataset/sa-1b
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
28 августа 2023 07:26
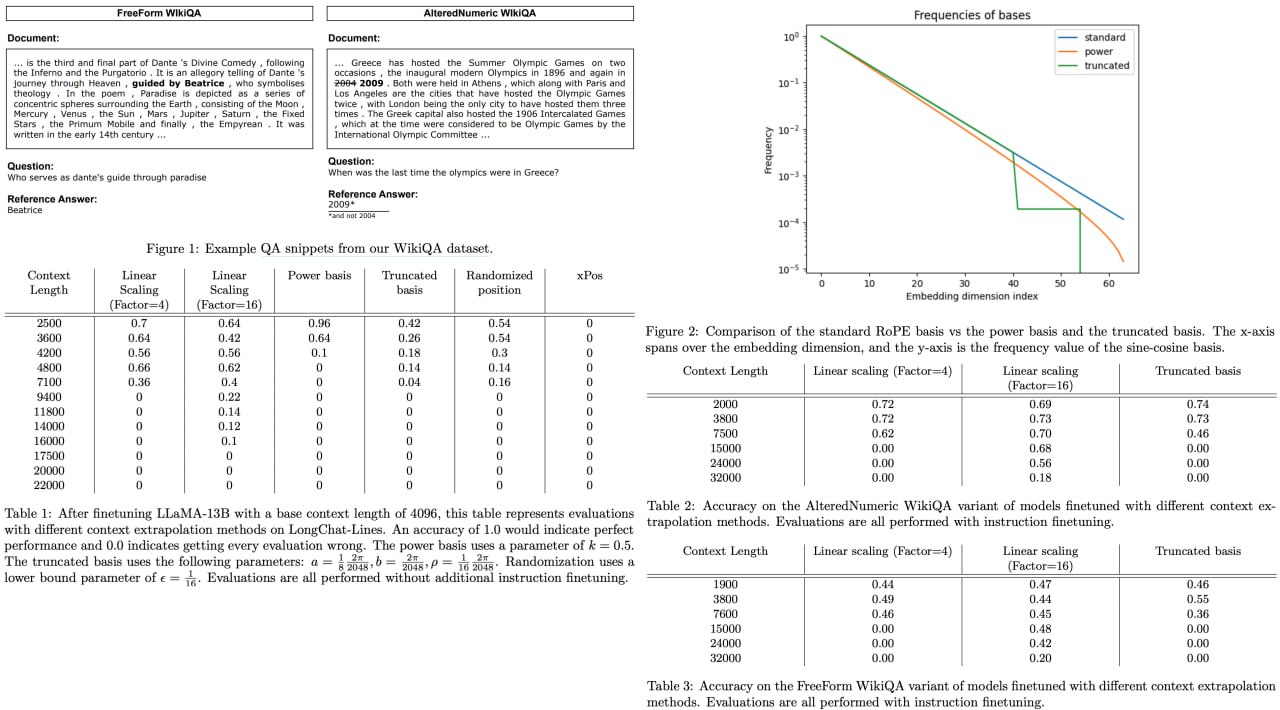
Giraffe: Adventures in Expanding Context Lengths in LLMs
Modern Large Language Models (LLMs) have revolutionized our ability to process and understand vast amounts of textual data. Yet, these models, like LLaMA and LLaMA2, often come with a caveat: they're constrained by fixed context lengths, which means they're limited in handling longer sequences of input data at evaluation. This paper tackles that constraint by investigating a variety of methods for "context length extrapolation," which essentially enables these models to understand and work with longer text sequences. Among the techniques explored, the paper introduces an innovative "truncated basis" strategy for altering positional encodings within the attention mechanism, promising a more scalable future for LLMs.
The researchers put their theories to the test with three brand-new evaluation tasks—FreeFormQA, AlteredNumericQA, and LongChat-Lines—providing a more nuanced measure of model performance than the traditionally used metric of perplexity. Their findings? Linear scaling came out on top as the most effective way to extend the context length, but the truncated basis method showed potential for future exploration. To propel the research community even further, the paper releases three game-changing long-context models, named Giraffe, with context lengths ranging from 4k to an astonishing 32k.
Paper link: https://arxiv.org/abs/2308.10882
Code link: https://github.com/abacusai/Long-Context
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-giraffe
#deeplearning #cv #nlp #largelanguagemodel #opensource #largecontext
Читать полностью…
Data Science by ODS.ai 🦜
25 августа 2023 21:19
Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
The results reveal the superiority and potential of PEFT over ICL (In-Context Learning) on a wide range of LLMs in reducing the computational burden and improving performance.
Main results:
- LLMs fine-tuned with PEFT techniques, i.e., a few millions of parameters, systematically outperform small language models fully fine-tuned with hundreds of millions of parameters
- Prompt tuning often outperforms LoRA even though it requires learning substantially fewer parameters
- LLMs fine-tuned using LoRA and Prompt tuning significantly outperform LLMs with ICL, even when increasing the number of prompt examples under the ICL setting
- PEFT techniques allow LLMs to better adapt to the task-specific dataset with low computational cost
Читать полностью…
Data Science by ODS.ai 🦜
22 августа 2023 20:41
OWASP Top 10 for LLM
The OWASP Top 10 for Large Language Model Applications project aims to educate developers, designers, architects, managers, and organizations about the potential security risks when deploying and managing Large Language Models (LLMs). The project provides a list of the top 10 most critical vulnerabilities often seen in LLM applications, highlighting their potential impact, ease of exploitation, and prevalence in real-world applications. Examples of vulnerabilities include prompt injections, data leakage, inadequate sandboxing, and unauthorized code execution, among others. The goal is to raise awareness of these vulnerabilities, suggest remediation strategies, and ultimately improve the security posture of LLM applications.
1 Prompt Injection
2 Insecure Output Handling
3 Training Data Poisoning
4 Model Denial of Service
5 Supply Chain Vulnerabilities
6 Sensitive Information Disclosure
7 Insecure Plugin Design
8 Excessive Agency
9 Overreliance
10 Model Theft
PDF
Читать полностью…
Data Science by ODS.ai 🦜
21 августа 2023 17:44
🪄WizardLM: Empowering Large Pre-Trained Language Models to Follow Complex Instructions
Model outperforms ChatGPT-3.5, Claude Instant-1, PaLM-2 and Minerva on GSM8k, simultaneously surpasses Text-davinci-002, PaLM-1 and GPT-3 on MATH.
Фреймворк WizardMath, который расширяет способности Llama-2 к математическому мышлению, применяя метод Reinforcement Learning from Evol-Instruct Feedback (RLEIF) к области математики.
WizardMath с существенным отрывом превосходит все остальные LLM с открытым исходным кодом в решение мат. задач.
🖥 Github: https://github.com/nlpxucan/wizardlm
📕 Paper: https://arxiv.org/abs/2308.09583v1
🤗 HF: https://huggingface.co/WizardLM
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
18 августа 2023 19:22
FLAIR: A Foundation LAnguage Image model of the Retina
🖥 Github: https://github.com/jusiro/flair
📕 Paper: https://arxiv.org/pdf/2308.07898v1.pdf
🔥 Dataset: https://paperswithcode.com/dataset/imagenet
@ig_data
Читать полностью…
Data Science by ODS.ai 🦜
10 апреля 2024 08:35
🥔 YaART: Yet Another ART Rendering Technology
💚 This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF).
💜 During the development of YaART, Yandex especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before.
💖 In particular, researchers comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice.
▪Paper page - https://ya.ru/ai/art/paper-yaart-v1
▪Arxiv - https://arxiv.org/abs/2404.05666
▪Habr - https://habr.com/ru/companies/yandex/articles/805745/
@
Читать полностью…
Data Science by ODS.ai 🦜
06 апреля 2024 18:01
⚡️ Awesome CVPR 2024 Papers, Workshops, Challenges, and Tutorials!
На конференцию 2024 года по компьютерному зрению и распознаванию образов (CVPR) поступило 11 532 статей, из которых только 2 719 были приняты, что составляет около 23,6% от общего числа.
Ниже приведен список лучших докладов, гайдов, статей, семинаров и датасетов с CVPR 2024.
▪Github
@ig_data
Читать полностью…
Data Science by ODS.ai 🦜
02 апреля 2024 15:01
Let’s get back to posting 😌
Читать полностью…
Data Science by ODS.ai 🦜
10 марта 2024 07:34
LLM models are in their childhood years
yannlecun/post/C4TONRKrCgx/?xmt=AQGzgyqvMeJEC2KowLslWxsAN6dSxycXtm1O-gfJ9FPLlQ">Source.
Читать полностью…
Data Science by ODS.ai 🦜
27 сентября 2023 12:50
Here is very interesting notes about how behaves generation of stable diffusion trained on different datasets with the same noise. Seems very contrintuitive!
https://twitter.com/mokadyron/status/1706618451664474148
Читать полностью…
Data Science by ODS.ai 🦜
14 сентября 2023 19:22
🔥 Introducing Würstchen: Fast Diffusion for Image Generation
Diffusion model, whose text-conditional component works in a highly compressed latent space of images
Würstchen - это диффузионная модель, которой работает в сильно сжатом латентном пространстве изображений.
Почему это важно? Сжатие данных позволяет на порядки снизить вычислительные затраты как на обучение, так и на вывод модели.
Обучение на 1024×1024 изображениях гораздо затратное, чем на 32×32. Обычно в других моделях используется сравнительно небольшое сжатие, в пределах 4x - 8x пространственного сжатия.
Благодаря новой архитектуре достигается 42-кратное пространственное сжатие!
🤗 HF: https://huggingface.co/blog/wuertschen
📝 Paper: https://arxiv.org/abs/2306.00637
📕 Docs: hhttps://huggingface.co/docs/diffusers/main/en/api/pipelines/wuerstchen
🚀 Demo: https://huggingface.co/spaces/warp-ai/Wuerstchen
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
13 сентября 2023 16:17
📹 DEVA: Tracking Anything with Decoupled Video Segmentation
Decoupled video segmentation approach (DEVA), composed of task-specific image-level segmentation and class/task-agnostic bi-directional temporal propagation.
Новая модель сегментации видео для "отслеживания чего угодно" без обучения по видео для любой отдельной задачи.
🖥 Github: https://github.com/hkchengrex/Tracking-Anything-with-DEVA
🖥 Colab: https://colab.research.google.com/drive/1OsyNVoV_7ETD1zIE8UWxL3NXxu12m_YZ?usp=sharing
⏩ Project: https://hkchengrex.github.io/Tracking-Anything-with-DEVA/
📕 Paper: https://arxiv.org/abs/2309.03903v1
⭐️ Docs: https://paperswithcode.com/dataset/burst
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
11 сентября 2023 07:11
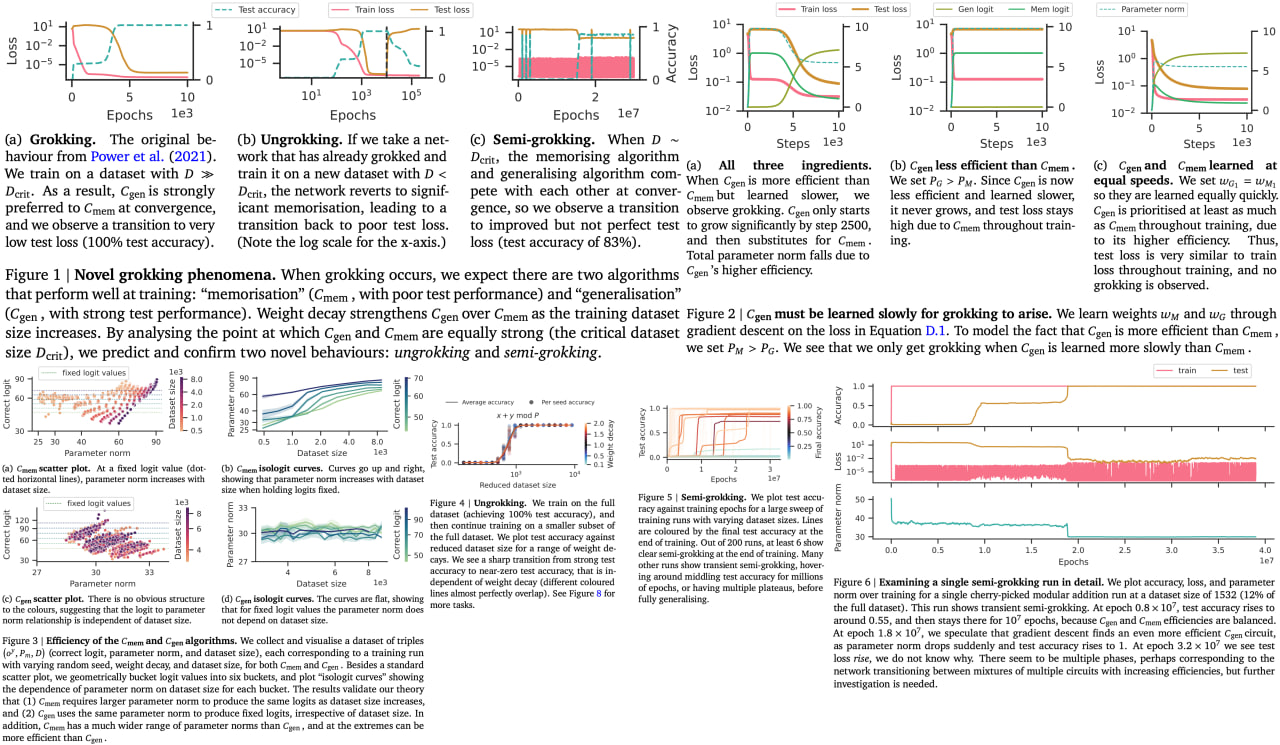
Explaining grokking through circuit efficiency
The paper explores the phenomenon of "grokking" in neural networks, where a network that initially performs poorly on new data eventually excels without any change in training setup. According to the authors, grokking occurs when two conditions are present: a memorizing solution and a generalizing solution. The generalizing solution takes longer to learn but is more efficient in terms of computational resources. The authors propose a "critical dataset size" at which the efficiencies of memorizing and generalizing are equal, providing a pivot point for the network to switch from memorization to generalization.
Furthermore, the paper introduces two new behaviors: "ungrokking" and "semi-grokking." Ungrokking describes a situation where a well-performing network reverts to poor performance when trained on a smaller dataset. Semi-grokking refers to a scenario where the network, instead of achieving full generalization, reaches a state of partial but improved performance.
Paper link: https://arxiv.org/abs/2309.02390
My overview of the paper:
https://andlukyane.com/blog/paper-review-un-semi-grokking
https://artgor.medium.com/paper-review-explaining-grokking-through-circuit-efficiency-1f420d6aea5f
#paperreview
Читать полностью…
Data Science by ODS.ai 🦜
04 сентября 2023 06:38
RecMind: Large Language Model Powered Agent For Recommendation
Recent advancements have significantly improved the capabilities of Large Language Models (LLMs) in various tasks, yet their potential in the realm of personalized recommendations has been relatively unexplored. To address this gap, a new LLM-powered autonomous recommender agent called RecMind has been developed. RecMind is designed to provide highly personalized recommendations by leveraging planning algorithms, tapping into external data sources, and using individualized data.
One standout feature of RecMind is its novel "Self-Inspiring" algorithm, which enhances the model's planning abilities. During each step of planning, the algorithm encourages the model to consider all its past actions, thereby improving its understanding and use of historical data. The performance of RecMind has been evaluated across multiple recommendation tasks like rating prediction, sequential and direct recommendation, explanation generation, and review summarization. The results show that RecMind outperforms existing LLM-based methods in these tasks and is competitive with the specialized P5 model.
Paper link: https://arxiv.org/abs/2308.14296
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-recmind
#deeplearning #nlp #llm #recommender
Читать полностью…
Data Science by ODS.ai 🦜
31 августа 2023 06:36
CoTracker: It is Better to Track Together
The CoTracker paper proposes a groundbreaking approach that takes video motion prediction to the next level. Traditional methods have often been limited, either tracking the motion of all points in a frame collectively using optical flow, or tracking individual points through a video. These approaches tend to overlook the crucial interrelationships between multiple points, especially when they're part of the same physical object. CoTracker flips the script by employing a transformer-based architecture to jointly track multiple points throughout a video, effectively modeling the correlations between different points in time.
What really sets CoTracker apart is its versatility and adaptability. It's engineered to handle extremely long videos through a unique sliding-window mechanism, and iteratively updates estimates for multiple trajectories. The system even allows for the addition of new tracking points on-the-fly, offering unmatched flexibility. CoTracker outshines state-of-the-art methods in nearly all benchmark tests.
Paper link: https://arxiv.org/abs/2307.07635
Code link: https://github.com/facebookresearch/co-tracker
Project link: https://co-tracker.github.io/
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-cotracker
#deeplearning #cv #objecttracking
Читать полностью…
Data Science by ODS.ai 🦜
26 августа 2023 10:48
All of LibGen.
131TB of high quality text.
Just think about it.
Читать полностью…
Data Science by ODS.ai 🦜
24 августа 2023 06:31
OBELISC: An Open Web-Scale Filtered Dataset of Interleaved Image-Text Documents
The OBELICS dataset is a game-changer in the world of machine learning and AI! Unlike existing closed-source datasets, OBELICS is a vast, open-source, web-scale dataset specially curated for training large multimodal models. Boasting 141 million web pages from Common Crawl, 353 million high-quality images, and an impressive 115 billion text tokens, OBELICS sets a new standard in the richness and diversity of training data.
But it's not just about the numbers; it's about results. To prove its mettle, models with 9 and 80 billion parameters were trained on OBELICS, showcasing competitive performance across various multimodal benchmarks. Named IDEFICS, these models outperformed or matched their closed-source counterparts, proving that OBELICS isn't just a theoretical concept—it's a practical, high-impact alternative.
Paper link: https://huggingface.co/papers/2306.16527
Model card link: https://huggingface.co/HuggingFaceM4/idefics-80b-instruct
Blogpost link: https://huggingface.co/blog/idefics
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-obelisc
#deeplearning #cv #nlp #largelanguagemodel #opensource
Читать полностью…
Data Science by ODS.ai 🦜
22 августа 2023 15:18
☄️Dataset Quantization
DQ is able to generate condensed small datasets for training unseen network architectures with state-of-the-art compression ratios for lossless model training.
Квантование наборов данных (DQ) - новая схема сжатия больших наборов данных в небольшие сабсеты, которые могут быть использованы для обучения любых нейросетевых архитектур.
git clone https://github.com/vimar-gu/DQ.git
cd DQ
🖥 Github: https://github.com/magic-research/dataset_quantization
📕 Paper: https://arxiv.org/abs/2308.10524v1
☑️ Dataset: https://paperswithcode.com/dataset/gsm8k
ai_machinelearning_big_data
Читать полностью…
Data Science by ODS.ai 🦜
21 августа 2023 06:37
LISA: Reasoning Segmentation via Large Language Model
The field of image segmentation has taken a leap forward with the introduction of LISA (Large Language Instructed Segmentation Assistant). This cutting-edge model excels at "reasoning segmentation," a novel task that generates segmentation masks from complex and implicit text queries. Building upon the capabilities of multi-modal Large Language Models, LISA expands its vocabulary with a <SEG> token and introduces an innovative "embedding-as-mask" paradigm to achieve this feat. Notably, the model is adept at intricate reasoning, utilizes world knowledge, offers explanatory answers, and can handle multi-turn conversations.
What's astonishing about LISA is its robust zero-shot learning abilities. Even when trained on datasets that lack reasoning-based tasks, LISA performs impressively well. Moreover, when fine-tuned with just 239 specific reasoning segmentation image-instruction pairs, the model's performance is further enhanced.
Paper link: https://arxiv.org/abs/2308.00692
Code link: https://github.com/dvlab-research/LISA
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-lisa
#deeplearning #cv #nlp #imagesegmentation #largelanguagemodel
Читать полностью…
Data Science by ODS.ai 🦜
17 августа 2023 06:49
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
The fusion of transformer and convolutional architectures has ushered in a new era of enhanced model accuracy and efficiency, and FastViT is at the forefront of this revolution. This novel hybrid vision transformer architecture boasts an impressive latency-accuracy trade-off, setting new benchmarks in the field. Key to its success is the RepMixer, an innovative token mixing operator that utilizes structural reparameterization to slash memory access costs by doing away with traditional skip-connections.
In practical terms, FastViT's prowess is undeniable. Not only is it a staggering 3.5x faster than CMT on mobile devices for ImageNet accuracy, but it also leaves EfficientNet and ConvNeXt trailing in its wake, being 4.9x and 1.9x faster respectively. Additionally, when pitted against MobileOne at a similar latency, FastViT emerges triumphant with a 4.2% superior Top-1 accuracy. Across a spectrum of tasks, from image classification and detection to segmentation and 3D mesh regression, FastViT consistently outshines its competitors, showcasing both remarkable speed and robustness against out-of-distribution samples and corruptions.
Paper link: https://huggingface.co/papers/2303.14189
Code link: https://github.com/apple/ml-fastvit
A detailed unofficial overview of the paper:
https://andlukyane.com/blog/paper-review-fastvit
#deeplearning #cv
Читать полностью…



 51238
51238
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}