Data Scientology
01 сентября 2023 13:14
Do you really need a strong Math ( and ML ) knowledge be a NLP engineer ?
Let me explain a bit. I come from a humanities bachelor's degree background, but with a strong passion for linguistics. I wanted to specialize in computational linguistics, but gradually I also became very interested in NLP and jobs related to NLP. That being said, I hope the repressed computer engineers don't show up now lol
I'm about to start a master's degree called “ Digital Humanities” but which is actually only about language technologies. The program includes various subjects like NLP, computational linguistics, data mining, programming, data analysis, etc. However, I know that the Machine Learning (ML) course is fundamental for NLP, but the university's ML course requires strong math foundations, designed for those who have a bachelor's degree in computer science or computer engineering. So, I had thought about giving it up and instead taking the course called “ Computational Intelligence and Deep Learning” that focuses more on topics like fuzzy logic and especially artificial neural networks, RNNs, etc., without requiring initial math foundations.
And maybe adding also an Algorithms class (a good class but not too advanced) to have an additional foundation for NLP.
And then I might study ML on my own through private courses like the one from Stanford on platforms like Coursera.
Or would it be better for me to study the math part (linear algebra, integral and differential calculus, functions) and attempt the ML exam? Keep in mind that I've already taken a statistics course and enjoyed it, but honestly, I don't have that much motivation to study math extensively, especially because I might invest so much effort for none since I might only find jobs like data linguist or computational linguist (given my background in humanistic informatics) where these strong math and ML knowledge are not necessary.
Certainly, my career goal in NLP isn't to engage in researching new algorithms and statistical models, I want to use more my linguistics knowledge in NLP but not only to do annotations.
I've noticed there are many people working more as "NLP engineers" many practical NLP tasks can be accomplished using existing libraries and tools without delving deep into the underlying mathematical concepts and who directly apply algorithms. So obviously you need t know algorithms and deep learning but not too much deep into math research right?
Or would it be better for me to just give up and focus solely on computational linguistics?
/r/LanguageTechnology
https://redd.it/165epjv
Читать полностью…
Data Scientology
28 августа 2023 13:14
Getting data from physical circular chart.
/r/computervision
https://redd.it/162xdyo
Читать полностью…
Data Scientology
23 августа 2023 13:14
Is CV evolving beyond bounding boxes?
Hi all - We (team of Stanford researchers) wrote a new blogpost on "Video Analysis Beyond Bounding Boxes" collecting some of our thoughts on the direction the CV field is heading.
We're actively researching&developing in this space so would love to hear some feedback on this vision for the future of CV and video analysis.
/r/computervision
https://redd.it/15ydds0
Читать полностью…
Data Scientology
18 августа 2023 13:14
Vision transformers (ViT)
/r/deeplearning
https://redd.it/15rf0i8
Читать полностью…
Data Scientology
14 августа 2023 13:14
Your Neural Network Doesn't Know What It Doesn't Know
Hi everyone,
I made a repo trying to collect every high-quality source for Out-of-distribution detection, ranging from articles and talks for beginners to research papers at top conferences. It also has a primer if you are not familiar with the topic. Check it out and give it a star to support me if you find it helpful. Thanks a lot ;)
https://github.com/continuousml
​
https://preview.redd.it/3dsy0ameoxhb1.png?width=868&format=png&auto=webp&s=4a0c016ab9ad6baeb603bedac1d798572fc41152
/r/computervision
https://redd.it/15q8mx0
Читать полностью…
Data Scientology
09 августа 2023 13:14
Looking for good learning sources around generative AI, specifically LLM
Are there any good video content sources that explains all the concepts associated with generative AI (ex: RL, RLHF, transformer, etc) from the ground up in extremely simple language (using analogies/stories of things that would be familiar to say a 10-12 year old)? Also would prefer channels which explain the concepts in a sequential manner (so that easy to follow) and make short and crisp videos
If yes, could you kindly comment below with the suggestions. If not, could you comment whether something like that would be useful to you and ideally why also?
Big thanks in advance 🙏
/r/deeplearning
https://redd.it/15hdu5v
Читать полностью…
Data Scientology
04 августа 2023 13:14
D Simple Questions Thread
Please post your questions here instead of creating a new thread. Encourage others who create new posts for questions to post here instead!
Thread will stay alive until next one so keep posting after the date in the title.
Thanks to everyone for answering questions in the previous thread!
/r/MachineLearning
https://redd.it/15dnok8
Читать полностью…
Data Scientology
31 июля 2023 13:14
Promptify 2.0: More Structured, More Powerful LLMs with Prompt-Optimization, Prompt-Engineering, and Structured Json Parsing with GPT-n Models! 🚀
Hello fellow coders and AI enthusiasts!First up, a huge Thank You for making Promptify a hit with over **2.3k+ stars on Github** ! 🌟Back in 2022, we were the first one to tackle the common challenge of uncontrolled, unstructured outputs from large language models like GPT-3. , and your support has pushed us to keep improving.Today, we're thrilled to share some major updates that make Promptify even more powerful
​
* **Unified Architecture 🧭**: Introducing Prompter, Model & Pipeline Solution
* **Detailed Output Logs 📔**: Comprehensive structured JSON format output within the log folder.
* **Wider Model Support 🤝:** Supporting models from OpenAI, Azure, Cohere, Anthropic, Huggingface and more - think of it as your universal language model adapter.
* **Robust Parser 🦸♂️**: Parser to handle incomplete or unstructured JSON outputs from any LLMs.
* **Ready-Made Jinja Templates 📝:** Jinja prompt templates for NER, Text Classification, QA, Relation-Extraction, Tabular data, etc.
* **Database Integration 🔗**: Soon, Promptify directly to Mongodb integration. Stay tuned!
* **Effortless Embedding Generation 🧬**: Generate embeddings from various LLMs effortlessly with the new update.
Check out the examples and take Promptify for a spin on GitHub. If you like what you see, we'd be honored if you gave us a star!
**Github**: [https://github.com/promptslab/Promptify](https://github.com/promptslab/Promptify)
Thank you again for your support - here's to more structured AI!
from promptify import Prompter,OpenAI, Pipeline
sentence = "The patient is a 93-year-old female with a medical..."
model = OpenAI(api_key)
result = pipe.fit(sentence, domain="medical", labels=None)
Output
[ {"E": "93-year-old", "T": "Age"}, {"E": "chronic right hip pain", "T": "Medical Condition"}, {"E": "osteoporosis", "T": "Medical Condition"}, {"E": "hypertension", "T": "Medical Condition"}, {"E": "depression", "T": "Medical Condition"}, {"E": "chronic atrial fibrillation", "T": "Medical Condition"}, {"E": "severe nausea and vomiting", "T": "Symptom"}, {"E": "urinary tract infection", "T": "Medical Condition"}, {"Branch": "Internal Medicine", "Group": "Geriatrics"}, ]
​
/r/LanguageTechnology
https://redd.it/15dfttb
Читать полностью…
Data Scientology
26 июля 2023 13:14
D Simple Questions Thread
Please post your questions here instead of creating a new thread. Encourage others who create new posts for questions to post here instead!
Thread will stay alive until next one so keep posting after the date in the title.
Thanks to everyone for answering questions in the previous thread!
/r/MachineLearning
https://redd.it/1518fj5
Читать полностью…
Data Scientology
21 июля 2023 13:14
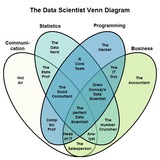
How essential are strong math and statistics skills for NLP Engineers?
My initial belief was that math and stats would be extremely vital for this field, but I'm seeing some mixed information online. Ironically, Google Bard also was stating that math and stats are not vital. (Though I can't help but think that this is inaccurate).
Can anyone confirm and give some feedback? What are the needed core skills?
/r/LanguageTechnology
https://redd.it/150sew0
Читать полностью…
Data Scientology
17 июля 2023 13:14
I Hit 700K Views in 3 Months with my Opensource Shorts automation framework, ShortGPT
/r/computervision
https://redd.it/150mzll
Читать полностью…
Data Scientology
12 июля 2023 13:14
A Comparison of Large Language Models (LLMs) in Biomedical Domain
https://provectus.com/blog/comparison-large-language-models-biomedical-domain/
/r/LanguageTechnology
https://redd.it/14x5cge
Читать полностью…
Data Scientology
07 июля 2023 13:14
P TomoSAM, a 3D Slicer extension using SAM to aid the segmentation of 3D data from tomography or other imaging techniques
We are a team at NASA working on modeling the material response of Thermal Protection Systems (TPS). We developed this tool to streamline the segmentation process of micro-tomography data, a necessary step before using the physics solvers within PuMA. However, we believe that TomoSAM is general enough to be useful in other fields, such as medical imaging. The release is fully open-source and you can find more information in the links below:
TomoSAM extension within 3D Slicer
🔗 Github: https://github.com/fsemerar/SlicerTomoSAM
🔗 YouTube tutorial: https://www.youtube.com/watch?v=4nXCYrvBSjk
🔗 Publication: https://arxiv.org/abs/2306.08609
🔬 TomoSAM combines the power of Segment Anything Model (SAM), a cutting-edge deep learning model, with the capabilities of 3D Slicer, a software platform useful for visualization and segmentation.
💡 SAM is a promptable deep learning model developed by Meta AI that can identify objects and generate image masks in a zero-shot manner, requiring only a few user clicks.
⚙️ This integration reduces the need for laborious manual segmentation processes, saving significant time and effort for researchers working with volumetric data.
📄 Our paper outlines the methodology and showcases the capabilities of TomoSAM.
TomoSAM's usage, architecture, and communication system
Feel free to reach out if you have any questions or comments! 🚀
/r/MachineLearning
https://redd.it/14sroe6
Читать полностью…
Data Scientology
03 июля 2023 13:14
Additional Resources
Hi everyone,
After an [extended blackout](https://old.reddit.com/r/MachineLearning/comments/146ue8q/rmachinelearning_is_joining_the_reddit_blackout), we've decided to reopen the sub since it became pretty clear that if we didn't then the [admins would likely replace us and just reopen](https://kbin.social/m/machinelearning/t/68966/r-MachineLearning-finally-received-a-warning-from-u-ModCodeOfConduct) anyway.
We know lots of you contacted us during the blackout trying to understand how to stay up to date with the latest ML research, news, and discussions. For that reason we are providing additional resources below that either exclusively focus on ml or often discuss ml:
* ~~[taggernews](http://www.taggernews.com/tags/ai/machine%20learning/) - an ml powered classifier for [hackernews](https://news.ycombinator.com/) posts tagged as ai/ml~~
* use [hackernews](https://news.ycombinator.com/) RSS feeds like this one to keep up with posted research https://hnrss.org/newest?q=arxiv+OR+cvpr+OR+aaai+OR+iclr+OR+icml+OR+neurips+OR+emnlp+OR+acl
* reddit has rss feeds for just about any link by just adding `.rss` to the end of the url, so you can follow r/machinelearning using https://reddit.com/r/machinelearning.rss or even follow all posts that link to arxiv using https://reddit.com/domain/arxiv.org.rss
* [lobste.rs/t/ai](https://lobste.rs/t/ai) - posts tagged as ai on [lobste.rs](https://lobste.rs/t/ai)
* [m/machinelearning](https://kbin.social/m/machinelearning/) - a nascent space for ml discussion on [kbin](https://kbin.social)
You can also find a more thorough list of subs with additional resources here: https://sub.rehab
If you have additional resources you think would be useful, please comment below and we can add them to the list.
EDIT: removed taggernews since its long defunct
/r/MachineLearning
https://redd.it/14ionyi
Читать полностью…


 1234
1234
{kind=link}
{kind=link}
{kind=link}