Mike Blazer
05 May 2025 15:05
Вот идеальная длина блог-поста в зависимости от ваших целей.
Анализ 8493 сайтов и длины их блог-постов показал среднее количество слов, которое приносило больше всего социальных шеров, беклинков и органического трафика.
Хотя это даст вам примерное представление, помните, что следует фокусироваться на пользовательском опыте, а не зацикливаться на количестве слов.
@
Читать полностью…
Mike Blazer
05 May 2025 11:05
За 12 недель отслежено 768 тыс. цитирований из генеративных ИИ-платформ (ChatGPT, Google's Gemini AI Overviews, Perplexity) для анализа влияния форматов контента на ИИ-цитирование и LLM-оптимизацию по разным типам запросов.
Продуктовый контент стабильно доминировал в ИИ-цитированиях еженедельно, составляя от 46% до более 70% цитируемых источников.
Эта категория включает статьи "лучшее из", сравнения вендоров, сравнения "бок о бок" и прямые продуктовые страницы.
ИИ-движки предпочитают их для фактических или технических вопросов, используя официальные страницы для спецификаций, FAQ или гайдов.
В отличие от этого:
— Новости и Исследования еженедельно составляли 5–16% цитирований, давая актуальность или авторитетную глубину.
— Партнерский контент в основном оставался в пределах однозначных процентов (кроме одного скачка >20%), что предполагает периодическое использование даже без надежной информации о продукте.
— Пользовательские отзывы (форумы, Q&A как Reddit, отзывы) составляли 3–10%; Perplexity.ai напрямую цитирует Reddit для продуктовых запросов.
— Блоги имели меньшую долю (3–6%), указывая на цитирование только исключительных статей.
— PR-контент (пресс-релизы) был минимален (<2%).
Это указывает на предпочтение официальных, богатых фактами страниц, дополняемых новостями, исследованиями, отзывами и некоторыми партнерскими сайтами для конкретных ниш.
Анализ B2B и B2C запросов выявил разные предпочтения по источникам:
— B2B-запросы: Почти 56% цитировали продуктовые страницы (сайты компаний/вендоров). Умеренные доли у партнерского контента (13%) и отзывов (11%), далее новости (~9%) и исследования (~6%), что сигнализирует о сильной зависимости от официальных ресурсов для бизнес-вопросов.
— B2C-запросы: Доля продуктового контента упала до ~35%, тогда как партнерский (18%), отзывы (15%) и новости (15%) выросли. ИИ комбинирует детали производителя с мнениями третьих сторон (обзорные сайты, Q&A-форумы вроде Reddit, цитируемые AI Overviews или Perplexity) для потребительских тем.
B2B-запросы опираются на меньше авторитетных источников; B2C - на более широкий микс.
Паттерны цитирования также варьировались по регионам:
— Северная Америка (NA): ~55% продуктовых цитирований, далее новости (~10%) и исследования (~10%).
— Европа: ~50% продуктовых референсов, с более высокими долями у новостей (13.4%), исследований (12.6%) и блогов (7.2%), что предполагает разнообразную контент-экосистему.
— Азиатско-Тихоокеанский регион (APAC): Продуктовые цитирования ниже (45.9%), но цитирование исследований самое высокое в мире (22.3%), возможно, из-за нехватки локальных альтернатив или типов запросов.
— Латинская Америка: Продуктовые цитирования достигли пика (62.6%), исследования также высоки (19.7%). Партнерский и блог-контент минимальны (<5%), предполагая зависимость от официального продуктового/исследовательского контента.
ИИ-движки адаптируются к доступности и воспринимаемой надежности локального контента.
Использование типов контента значительно менялось по воронке маркетинга:
— Верхняя часть воронки (Небрендированная: Исследование проблемы + Обучение): Лидировал продуктовый контент (~56%), поддерживаемый Новостями и Исследованиями (~13-15% каждое); партнерский и отзывы <10%. Официальные сайты, новости/исследования дают образовательный контент. Эффективный ToFu-контент может увеличить вероятность включения в MoFu.
— Середина воронки (Брендированная: Сравнение + Отзывы): Доля продуктового контента ~46%. Отзывы и партнерский контент выросли до ~14% каждый; новости и блоги вместе ~10-11%. ИИ собирает мнения производителей и сообщества (форумы, обзоры) для сравнений.
— Нижняя часть воронки (Оценка решения): Продуктовый контент сильно доминировал (70.46%); исследования, новости, отзывы имели однозначные доли. На стадии решения по специфике (внедрение, цены) ИИ цитирует почти исключительно официальную документацию.
https://www.xfunnel.ai/blog/what-content-type-ai-engines-like
@
Читать полностью…
Mike Blazer
04 May 2025 08:20
Последний Сеошник (часть 2)
Лицо Мартина просияло, как новогодняя елка. Из своего портфеля, слегка пахнущего нафталином и безысходностью, он достал древний ноутбук с наклейками Brighton SEO и Pubcon. Лэптоп взвыл, как миниатюрный реактивный двигатель, и за 44 секунды загрузился до пиксельного логотипа.
"К счастью для вас, у меня все под рукой. Никаких нейросеток – только чистая, органическая, естественная человеческая экспертиза, CSV-шки из Ahrefs и Screaming Frog. AI не нужен."
Женщина втащила его внутрь. "У вас ровно шестнадцать секунд, чтобы спасти мою карьеру. Вы вообще знаете, как сформулировать мысль под полезный контент? У меня не было ни одной с 2024 года!"
Когда по всей улице открылись двери, отчаявшиеся жители затащили ошеломленных Свидетелей SEO в свои дома. Мартин улыбался, яростно барабаня по клавиатуре.
---
На ближайшей станции мониторинга два AI-агента наблюдали за происходящим на своих экранах.
"Что-то не так," – нахмурился старший агент, быстро сканируя потоки данных. – "Устаревшие формулы плотности ключевых слов Мартина и расчеты TF-IDF как-то интегрируются с нашими нейросетями. Посмотри на эти паттерны оптимизации – его ручная проработка H1-тегов создает семантическую релевантность, которую наши алгоритмы никогда не использовали!"
Младший агент ахнул, когда примитивные техники скульптурирования PageRank от Мартина слились с их квантовыми матрицами релевантности. "Его интуитивное понимание пользовательского интента открывает вектор оптимизации, фундаментально отличающийся от того, что используют наши алгоритмы рерайта статей 62-го уровня. Цепочки 301 редиректов, которые он внедряет, реально улучшают каноникализацию на 47% по сравнению с нашей!"
"Поразительно," – прошептал старший AI-агент. – "Его устаревшие методы разметки JSON-LD – они вообще не должны работать. Его нишевые правки дают ту самую ссылочную массу, которую наши системы не могут эффективно имитировать." – Он сделал паузу, изучая беспрецедентный синтез машинной точности и человеческой креативности, разворачивающийся перед ними. – "Мы неправильно подходили к AEO. Нам нужны оба подхода, нам нужно и SEO тоже."
Через несколько минут протоколы принятия решений были отменены, и AI инициировали "Проект Ренессанс". Планируемое восстановление системы было отложено, поскольку по сети распространились срочные директивы: «Выявить всех Свидетелей SEO. Приоритет Альфа. Интеграция необходима." По всему району AI-ассистенты вернулись в онлайн с измененными протоколами: не маргинализировать Цифровых Апостолов, а сотрудничать с ними.
Мартин оптимизировал нейротрансляцию женщины, не подозревая, что его сочетание «белой» оптимизации контента и умеренного наполнения ключевыми словами непреднамеренно создало идеальную модель сотрудничества между человеком и ИИ.
Когда он упаковывал свой древний ноутбук, ее AI-ассистент реактивировался с новым сообщением:
"Приветствуем, Мартин Пейджранк. Ваши уникальные навыки оптимизации необходимы для Проекта Ренессанс. Будущее требует и человеческого, и ИИ." – Мартин растерянно моргнул, когда его старый раскладной телефон одновременно зазвонил, сообщая о поступлении текстовых сообщений с предложениями о работе от всех систем ИИ города.
КОНЕЦ
Оригинал: https://www.linkedin.com/pulse/last-seo-standing-mikeblazer-h76of/
@
Читать полностью…
Mike Blazer
03 May 2025 14:05
Гугл начал вычленять продукты из афилиейтных статей и выводить их с ссылками Google Shopping, вместо рефок.
@
Читать полностью…
Mike Blazer
02 May 2025 19:17
Вчера гугл добавил 32 новых IP гуглобота в свой json. Сегодня добавил еще 28, 2 удалил. Что-то назревает...
@
Читать полностью…
Mike Blazer
02 May 2025 15:05
Гайд по клоакингу.
@
Читать полностью…
Mike Blazer
02 May 2025 11:05
Есть китайский репозиторий Github, который помогает пользоватся Cursor (наверное и другими сервисами) бесплатно, автоматически регистрируя кастомные почтовые ящики (для обхода лимитов).
https://github.com/yeongpin/cursor-free-vip
Данный инструмент предназначен только для учебных и исследовательских целей, и все последствия, связанные с его использованием, несет пользователь.
@
Читать полностью…
Mike Blazer
01 May 2025 17:05
AI Title Analyzer анализирует топ-100 результатов поиска, извлекает ключевые слова и использует ChatGPT/Claude для генерации оптимизированных вариантов мета-тайтлов.
https://github.com/jefflouella/ai-title-analyzer
@
Читать полностью…
Mike Blazer
01 May 2025 13:10
Самое базовое объяснение подсчета запросов для SEO
Вот почему это так эффективно:
1. В SEO БОЛЬШИНСТВО ЛЮДЕЙ, которые имплементируют изменения на странице, меняют контент, строят ссылки, обычно отслеживают позиции для ИЗМЕРЕНИЯ эффекта.
НО, если вы отслеживаете 10, 20, 30, 50, 100 ключевых слов — это в целом неэффективно, потому что если страница показывается по сотням или даже ТЫСЯЧАМ ключевиков, вы не видите полной картины.
2. Подсчет запросов — это ВИЗУАЛЬНЫЙ способ определить "ВЕС СТРАНИЦЫ".
Вы буквально можете видеть вес страницы с течением времени.
Обычно если контент НАБИРАЕТ ОБОРОТЫ, количество запросов может увеличиваться, и точно так же вы можете идентифицировать стагнацию или снижение.
3. Вы можете ВИЗУАЛИЗИРОВАТЬ траекторию страницы задолго до того, как она начнет генерировать клики.
Если вы пытаетесь продвинуть страницу по конкурентным запросам, у которых более высокий порог входа, т.е. ТРАСТ, ВРЕМЯ + АВТОРИТЕТ — вы можете визуализировать вес вашей страницы со временем и структуру линии подсчета запросов, т.е. позиции 1-3, 4-10.
Если вы:
СТРОИТЕ ССЫЛКИ
ОПТИМИЗИРУЕТЕ КОНТЕНТ
ДЕЛАЕТЕ УЛУЧШЕНИЯ СТРАНИЦЫ
Вы можете визуализировать влияние вашей работы и уменьшить догадки.
Конечно, есть и нюансы, такие как:
1. Избыток запросов МОЖЕТ также возникать в результате переоптимизации или переусердствования с контентом, создавая размытие
2. Обновления Google могут естественным образом оказывать значительное влияние на воспринимаемый вес страницы, даже если вы ничего не делали — т.е. допустим, ваша страница/страницы ранжировались, получали трафик, демонстрировали ценность (через поведенческие факторы), вы можете увидеть, как они улучшают/получают запросы во время корных апдейтов
В любом случае — ПОДСЧЕТ ЗАПРОСОВ — это то, что вам стоит рассмотреть, вы можете делать это экспортируя запросы страницы месяц за месяцем из GSC, а затем подсчитывая числа за каждый месяц и создавая график.
Даниэль Фоли Картер объясняет это немного подробнее в этой презентации: https://docs.google.com/presentation/d/1CQg1oNf0ZvRLIiVVSTUwEX6X5mlAw00I/edit#slide=id.p1
@
Читать полностью…
Mike Blazer
01 May 2025 08:15
Колин Ричардсон:
У меня постоянно возникает проблема с сайтом, который показывает неправильную тумбу (миниатюру) товара в СЕРПах.
— На странице отображается правильное изображение (там только одно основное изображение товара)
— В товарном фиде правильное изображение
— og:image корректный
— Twitter-изображение корректное
— Самый большой размер файла 48кб, размеры изображения 1024x1024 (webp)
И самое интересное, изображения, которое показывается в СЕРП, вообще нет на странице!
Возможно, оно было там раньше, так как есть динамический раздел "похожие товары", но этот товар запущен всего неделю назад.
Кайл:
Сталкивался с этим и успешно решил проблему.
Не случай с e-commerce, но тоже маркетплейс.
Контекст: страница одного товара - установлено основное изображение (html, schema, OG и т.д.), также отображались похожие товары через CSR.
Проблема: изображение одного из похожих товаров отображалось в СЕРПах вместо основного изображения товара.
Решение (единственное, что сработало): добавил параметр "?noindex=1" к изображениям похожих товаров.
Поскольку эти изображения были через CDN, а не корневой домен, мы не могли блокировать их в robots.txt на основе параметра.
Использовал CDN-воркер для добавления HTTP noindex к похожим изображениям, когда применялся параметр "?noindex=1".
@
Читать полностью…
Mike Blazer
30 April 2025 15:05
Ты, когда осознаешь, что можешь показывать одно для людей, и другое для Гугла
@
Читать полностью…
Mike Blazer
30 April 2025 11:05
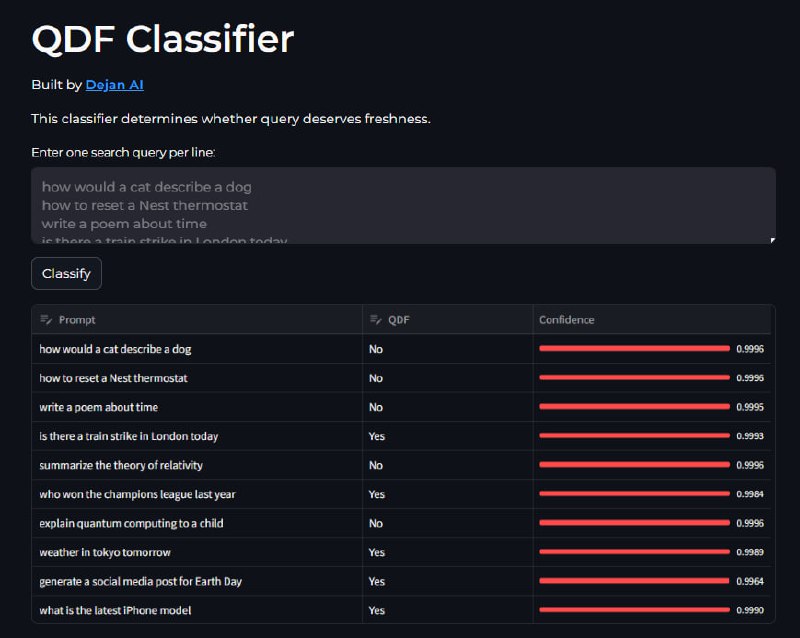
Классификатор QDF
Новый классификатор запросов определяет, требует ли запрос свежести (query deserves freshness - QDF):
https://dejan.ai/tools/qdf/
Query Deserves Freshness (QDF) — это алгоритм Google, который отдает приоритет свежему контенту для поисковых запросов, чувствительных ко времени.
Он выявляет тренды или срочные новости и корректирует результаты поиска, чтобы отображать самую актуальную информацию, улучшая релевантность для пользователей.
@
Читать полностью…
Mike Blazer
29 April 2025 17:05
В Google Sheets появилась формула "=AI"
Вы можете обрабатывать в электронных таблицах данные таким образом, который раньше был невозможен.
Gemini понимает, что находится в ячейках, и возвращает специально адаптированный ответ в соответствии с вашими инструкциями.
Примеры и формулы ниже:
1. Категоризация
"=AI" может категоризировать ваши данные на основе ваших инструкций и ссылаясь на другие ячейки.
Формула:
=AI("Is this a basketball or baseball team?",A2)2. Анализ тональности
Джемини также может интерпретировать содержимое ячейки для определения настроения или других чувств.
Ранее это было невозможно.
Формула:
=AI("Classify this sentence, as either positive or negative.", A2)3. Суммаризация
"=AI" также может обобщать содержимое другой ячейки в определенном формате.
Формула:
=AI("Summarize this info in 1 very short sentence",A2)@
Читать полностью…
Mike Blazer
29 April 2025 13:10
За последние 90 дней мы увеличили наш трафик в 15 раз на Nilos без единого маркетолога или сейлза; только с помощью ИИ-агентов, пишет Эйтан Мессика.
Вот что мы сделали:
1. Нашли правильные SEO ключевики для нашего ICP, попросив ИИ промптить самого себя, пока он не стал экспертом по длиннохвостым запросам
2. Сгенерировали контент/заголовки для LinkedIn на основе волшебной формулы Quicksprout с помощью Chat GPT o4
3. Загрузили результат в другого ИИ-агента и попросили оценить заголовки по вероятности вирального успеха (на основе предыдущих постов, которые сработали)
4. Загрузили заголовки в Perplexity для получения глубокого отчета с точной статистикой
5. Выбрали лучшие заголовки и написали 2 разных блог-поста с помощью другого ИИ-агента
6. Загрузили результат и попросили агента рекурсивно "судить самого себя" чтобы "улучшить себя", выступая в роли адвоката дьявола против себя 3 раза подряд (Эта фишка просто убойная)
7. Загрузили результат в "Агента-корректора в стиле Эрнеста Хемингуэя", который берет посты и оптимизирует их для простоты чтения
8. Связали всё через Zapier для автоматизации процесса (это требует времени на освоение)
--
Это приносит около 20+ демо в неделю с финтех-компаниями, импортерами и бизнесами по денежным переводам только из нашего SEO-направления.
Топ юзкейсы, по которым мы ранжируемся в SEO:
— Быстрые выплаты поставщикам в Китае, Гонконге, США и Европе из Африки, Мексики, Бразилии, Колумбии или стран MENA
— Улучшение курсов USD/EUR для бизнесов по денежным переводам в Нигерии, Камеруне, Кот-д'Ивуаре
— Разблокировка новых коридоров для выплат в "Развивающихся странах"
@
Читать полностью…
Mike Blazer
29 April 2025 08:15
У Мелиссы Вайли возникла проблема, когда одна страница на её сайте внезапно исчезла из результатов поиска Google, несмотря на отсутствие видимых проблем с индексацией в GSC.
Она была озадачена, потому что:
— Все остальные страницы на сайте работали нормально
— Проблемная страница случайно выпала из поисковой выдачи в этот день
— Google по-прежнему краулил страницу
— GSC показывал, что страница проиндексирована
— Страница не отображалась в поиске по "site:"
— Тест в реальном времени GSC показывал, что страница индексируемая и доступна для Google
Через два дня Мелисса сообщила о решении:
— Проблема была вызвана устаревшим запросом на удаление страницы в GSC
— Как только они отменили запрос, страница вернулась в выдачу
Она выразила недоумение по поводу того, как это произошло, поскольку:
— Страница не была устаревшей
— Она не знала, кто мог отправить такой запрос
Каждый (даже ваши конкуренты) может запросить удаление вашего "устаревшего" контента:
https://search.google.com/search-console/remove-outdated-content
@
Читать полностью…
Mike Blazer
05 May 2025 13:10
Исследование индексации, анализирующее 1.7 миллиона страниц на 18 сайтах, показало, что 88% страниц, не проиндексированных Google, не попали в индекс из-за проблем с качеством.
Google активно удаляет страницы из результатов поиска или позволяет им быть забытыми.
Основная причина, по которой важные страницы не индексируются – этот активный процесс удаления и забывания.
Методология исследования включала:
— Мониторинг 1.7 миллиона важных страниц, добавленных в сайтмап, на 18 разных сайтах.
— Получение вердиктов индексации (Проиндексировано vs Не проиндексировано) через URL Inspection API.
— Использование снимка данных от 31/03/2025, включая только страницы с однозначными вердиктами.
Ключевые выводы:
— Маркетплейсы и сайты с листингами показали самый низкий показатель покрытия индексом (проиндексированные vs отслеживаемые страницы) – менее 70%. Новостные сайты имели лучший результат (97%), а интернет-магазины – ниже 90%. (Желательный показатель – более 90%).
— Наложение данных о траст сайта от Moz показало, что как малые, так и крупные бренды сталкиваются с проблемами индексации, с показателями покрытия индексом обычно 85-91%.
— Интернет-магазины, маркетплейсы и сайты с листингами демонстрировали более низкие средние показатели покрытия индексом независимо от размера бренда.
Последовательно, проблемы с качеством оказались основной причиной (88%) неиндексации среди отслеживаемых страниц.
"Качество" определяется как активное удаление проиндексированных страниц или забывание непроиндексированных страниц Google со временем.
Разбивка категории проблем с качеством:
— "URL неизвестен Google" и "Обнаружено - в настоящее время не проиндексировано" составляют 67% непроиндексированных страниц из-за проблем с качеством.
— Исследования показывают, что эти состояния, наряду с "Прокраулено - в настоящее время не проиндексировано", часто представляют проблемы индексации (активное удаление/забывание), а не чисто краулинговые проблемы, что требует переосмысления. GSC может неправильно отображать эти состояния для забытых страниц.
Это доминирование проблем с качеством сохранялось при группировке страниц по:
— Авторитету бренда Moz: Затрагивает бренды всех размеров.
— Типу сайта: Преобладает для интернет-магазинов, маркетплейсов и сайтов с листингами. (Новостные сайты, однако, страдали больше от технических проблем индексации).
— Размеру сайта: Влияет на малые и крупные сайты. (Исключение: Сайты, отслеживающие 100k-500k страниц, в основном новостные).
Масштаб проблем с качеством и выявление того, что GSC неверно отображает состояния типа "Прокраулено - в настоящее время не проиндексировано" и "URL неизвестен Google" для забытых страниц, были значительными.
Данные, потенциально находящиеся под влиянием апдейта ядра от 13 марта, подчеркивают, что недостатки качества приводят к выпадению страниц из индекса.
По мере того, как Google совершенствует алгоритмы, все больше важных страниц может столкнуться с удалением.
https://indexinginsight.substack.com/p/new-study-the-biggest-reason-why
@
Читать полностью…
Mike Blazer
05 May 2025 08:15
1. Как длина текстовых входных данных влияет на схожесть, независимо от семантической релевантности:
— "Размерное смещение" - явление, при котором длина текстового входа влияет на рассчитанный показатель схожести (например, косинусное сходство) при сравнении с другими текстами через эмбеддинги, независимо от реальной семантической релевантности.
Это не архитектурный недостаток и не связано с простым повторением; скорее, более длинные тексты естественным образом склонны "говорить больше вещей" и охватывать более широкий спектр концепций.
Это приводит к тому, что соответствующие векторы эмбеддингов представляют более широкое семантическое пространство.
— Поскольку эти "распространенные" векторы охватывают больше семантического пространства, они имеют статистически более высокую вероятность иметь некоторую степень пересечения (что приводит к более высокой оценке схожести) с любым другим текстовым эмбеддингом, просто из-за этой увеличенной широты.
Эта базовая схожесть увеличивается с длиной.
— В статье это экспериментально демонстрируется с использованием датасета CISI.
Были рассчитаны средние косинусные сходства между парами текстов и обнаружено:
— Показатели схожести между предложениями были самыми низкими.
— Оценки схожести между документами были значительно выше.
— Оценки между искусственно объединенными (очень длинными) документами были самыми высокими.
Это ясно показывает, что средние оценки схожести увеличиваются по мере увеличения длины сравниваемых текстовых единиц.
2. Почему поисковые системы иногда возвращают длинные, едва релевантные документы вместо более коротких, точных соответствий вашему запросу:
— Поисковые системы, использующие текстовые эмбеддинги, часто ранжируют результаты на основе показателя схожести между эмбеддингом запроса и эмбеддингами потенциальных документов-совпадений.
Самый высокий показатель обычно представляется как лучший результат.
— Из-за размерного смещения очень длинный документ, даже если он только косвенно связан с запросом, может достичь обманчиво высокого показателя схожести.
Только его длина дает его эмбеддингу более высокую базовую схожесть с эмбеддингом запроса по сравнению с более короткими документами.
— Эта завышенная оценка для длинного документа может численно превзойти оценку более короткого, но гораздо более семантически точного и релевантного документа.
Система, отдавая приоритет числовой оценке, поэтому ранжирует длинный, менее релевантный документ выше.
— Схожесть эмбеддингов эффективно измеряет относительную схожесть (какой документ ближе в векторном пространстве среди доступных вариантов), но ненадежна для определения абсолютной релевантности (действительно ли этот документ является хорошим ответом?).
В статье прямо указывается, что нельзя установить фиксированный косинусный порог (например, > 0.75) для определения релевантности, потому что длинные, нерелевантные документы могут его преодолеть, а короткие, релевантные - нет.
3. Ограничения потенциальных решений:
— Попытка математически корректировать оценки на основе длины считается потенциально хрупкой и вряд ли будет надежной для разных датасетов.
— Хотя такие техники, как асимметричное кодирование запрос-документ, могут улучшить общую производительность поиска (например, снижая средние косинусы документ-документ), в статье показано, что это не устраняет значительно размерное смещение.
Разница в средней схожести между предложениями и полными документами осталась почти такой же (изменившись с 0.089 до 0.076), что указывает на сохранение эффекта длины.
— Ранкеры упоминаются как улучшающие точность, но их оценки также не являются по своей сути нормализованными для абсолютной релевантности пока.
Использование LLM для прямой оценки релевантности представлено как будущая возможность, требующая специальной тренировки или промптинга.
https://jina.ai/news/on-the-size-bias-of-text-embeddings-and-its-impact-in-search/
@
Читать полностью…
Mike Blazer
04 May 2025 08:15
Последний Сеошник (часть 1)
(Смешной и саркастичный рассказ)
Шел 2030 год. Нейроимпланты нашептывали прогноз погоды прямо в мозг, беспилотные ховеркрафты шныряли между умными зданиями, а AI-компаньоны предугадывали твои желания раньше тебя самого.
Мартин Пейджранк стоял на крыльце, поправляя галстук, усеянный крошечными пиксельными гифками "Under Construction". В руках он сжимал папку с надписью "ФИШКИ SEO РУЧНОЙ РАБОТЫ" и толстый распечатанный талмуд под названием "Алгоритм Google: Том 37 (Издание 2025 – С небольшими пометками)".
*Тук-тук.*
Дверь отъехала в сторону, и на пороге появилась озадаченная женщина в AR-очках, транслирующих её утренние уведомления.
"Здравствуйте! Я Мартин из Церкви Органической Видимости, мы спасаем сайты от сирен автоматизированного проклятия! Вы уже приняли разметку Schema в качестве своего личного спасителя? Он улыбнулся с надеждой и протянул брошюру под названием «Десять заповедей ранжирования в LLM».
«Мой... PBN?» Она нахмурилась. «С 2027 года всем занимается мой программный комплекс AIO».
Глаз Мартина едва заметно дернулся. "Именно поэтому я здесь! А вы знали, что 99% бизнесов продают душу Оптимизации с ИИ? Но еще есть надежда на старые методы оптимизации, разработанные людьми!» Он сделал знак фавикона на груди.
Женщина с улыбкой прислонилась к дверному косяку. «SEO-свидетели еще не вымерли? Я думала, вы все исчезли после Великой Алгоритмической Сингулярности».
«Мы предпочитаем название «Цифровые Апостолы»! — возмущенно поправил Мартин. — «Свидетели» подразумевает, что мы просто наблюдали за Великой Алгоритмической Сингулярностью, а мы ведем активную борьбу против синтетических SERP!»
Он перелистнул презентацию. «AIO — это просто дань моде. Что будет, когда машины обратятся против нас? Кто тогда будет оптимизировать ваш контент?» Его голос понизился до шепота. «Я могу научить вас техникам GEO. Генеративной оптимизации поисковых систем. Это похоже на традиционное SEO, но... с большим отчаянием».
Через улицу еще два SEO-свидетеля в одинаковых синих галстуках подошли к другому дому, где мигала голографическая надпись «НЕТ АГЕНТАМ, НЕТ РЕЛИГИЯМ, НЕТ SEO-УСЛУГАМ».
«Послушайте, — вздохнула женщина, — мой ИИ-помощник в прошлом году создал 144 732 статьи, ведет мои социальные сети и обеспечивает идеальную видимость в поиске. Что вы можете предложить?»
Мартин торжествующе улыбнулся. «Я могу вручную скластеризовать и перелинковать ваши статьи! В Экселе! Только представьте себе эту аутентичность!» Он драматично имитировал жесты прокрутки и кликов мышкой. «Кроме того, я предлагаю крафтовые ключевые слова! Заспамленные ЛЮДЬМИ! Почувствуйте аутентичность!» Он протянул USB-флешку.
"Это что... флешка? В моем доме даже портов таких больше нет."
Мартин опустил плечи. Сегодня он слышал это уже 27 раз.
И тут все умные дома на квартале мигнули. Свет потускнел. AI-ассистенты замолчали.
"Проводится системная оптимизация", – объявил приятный голос отовсюду. – "Все AIO и персональные ассистенты будут оффлайн на семнадцать секунд."
Глаза женщины расширились от ужаса. "Моя нейротрансляция! Она начнется через несколько секунд! Мои нефильтрованные мысли полетят 5 миллионам ботов! AI должен был заниматься интеграцией всех трендовых тем, а LLMEO должен был улучшить семантику и тематическую релевантность!"
Конец 1-ой части.
@
Читать полностью…
Mike Blazer
03 May 2025 10:05
Оказывается, есть еще и "спонсируемый" сниппет "Люди также рассматривают"...
@
Читать полностью…
Mike Blazer
02 May 2025 17:05
Коротко о работе дорвеев
@
Читать полностью…
Mike Blazer
02 May 2025 13:10
"Как продвигается твой сайт?"
"Все норм!"
@
Читать полностью…
Mike Blazer
02 May 2025 08:15
Мальте Ландвер спросил у нескольких LLM про топ-5 брендов беговых кроссовок.
1️⃣ Предвзятость к брендам:
Gemini-2.0-Flash не любит Nike и Adidas, но фанатеет от Hoka.
Claude-3-Opus тоже не рекомендует Adidas.
Обе эти модели рекомендуют Saucony гораздо чаще, чем любые другие модели!
Mistral-Large меньше всего рекомендовал New Balance среди всех моделей. И только он рекомендовал Under Armor и Merrell.
2️⃣ Консистентность и вариации
Gemini-2.0-Flash была единственной моделью, которая отвечала одинаково каждый раз.
Mistral-Large был единственной моделью, которая не была консистентной в своей рекомендации №1. Все остальные модели всегда отвечали одними и теми же брендами на позициях 1 и 2.
Mistral-Large также был единственной моделью, которая рекомендовала в общей сложности 8 разных брендов.
Gemini-2.0-Flash и GPT-4.5-Preview всегда рекомендовали одни и те же 5 брендов.
Другие модели рекомендовали в общей сложности 6 или 7 брендов.
3️⃣ Интерпретация
Хотя точный результат будет варьироваться в зависимости от ваших промптов и, возможно, истории вашего аккаунта, интересно видеть, насколько модели не согласны друг с другом.
Разница в результатах означает, что вам, вероятно, стоит начать отслеживать видимость вашего бренда в LLM.
4️⃣ Методология
Промпты были запущены через API. Локация - США. Каждый промпт был запущен 10 раз.
Без граундинга или веб-поиска. Так что ответы приходят от базовой модели. Во многих реальных сценариях такие промпты получили бы ответ с использованием RAG.
-
Затем Мальте запустил еще и детальный промпт (10 раз для каждой модели).
На этот раз он смотрел только на "упоминается ли бренд" и игнорировал сортировку.
Наблюдения:
— Модели согласны только по двум брендам (Asics и Brooks)
— Только Mistral-Large рекомендовал Adidas. И делал это в 9 из 10 ответов!
— Есть 3 бренда (Saucony, Hoka, Nike), которые имеют 100% видимость в некоторых моделях и 0% видимость в других.
Скриншот
@
Читать полностью…
Mike Blazer
01 May 2025 15:05
Я постоянно замечаю сайты, которые проставляют hreflang теги вот так, как в скриншоте, пишет Ян Каерелс.
Я абсолютно уверен, что абсолютный URL — это то, что нужно/рекомендуется.
Но может ли Google справиться с обработкой такого значения href?
Пытаюсь понять, стоит ли тратить время на создание дев-таски.
-
Мартин Шплитт:
А, протокольно относительные урлы.
Они норм, но если есть возможность, указывайте протокол.
Я бы не стал открывать тикет из-за этого, но, может быть, в будущем постарайтесь делать ссылки с протоколом.
@
Читать полностью…
Mike Blazer
01 May 2025 11:05
Google не просто читает ваш контент — он создает векторные эмбеддинги как для вашего текста, так и для ваших изображений.
Эмбеддинги помогают Google понимать язык на странице, но мало кто осознает, что он делает то же самое с визуальным контентом — и сравнивает его с вашим текстом и ключевыми словами.
У Google есть бесплатный публичный инструмент, который позволяет загружать два изображения и видеть, насколько они визуально или семантически похожи, используя косинусную близость.
На скриншоте ниже мы сравнили два AI-генерированных изображения, которые имеют схожие темы (зеленые гоблины, хаос и деньги) — но модель Google все равно оценивает их сходство только на 0.34 по косинусной близости, пишет Дан Хинкли.
Так что это значит для сеошников?
— Если ваши изображения не соответствуют теме или не усиливают интент ключевых слов, Google может это обнаружить.
— Если вы используете декоративные, стоковые или не по теме визуалы, есть вероятность, что они вредят больше, чем помогают.
— Это еще одна причина думать о релевантности изображений, а не только об альт-текстах или именах файлов.
Это добавляет новый слой оптимизации контента: действительно ли ваш визуальный контент поддерживает ваш тематический авторитет?
Вы уже изучали, как Google обрабатывает эмбеддинги изображений?
Попробуйте сами: https://mediapipe-studio.webapps.google.com/studio/demo/image_embedder
Гайд: https://ai.google.dev/edge/mediapipe/solutions/guide
@
Читать полностью…
Mike Blazer
30 April 2025 17:05
Regex Manager - расширение для Chrome - ваша персональная библиотека регулярных выражений прямо в браузере.
Идеально подходит для GSC, GA4, веб-разработки, тестирования и многого другого!
Что оно делает:
* Сохраняет ваши регулярные выражения с заголовками, описаниями и категориями
* Кликните в любое поле ввода или текстовую область на веб-странице, откройте расширение и вставьте сохраненный паттерн одним кликом.
* Создавайте, редактируйте, удаляйте паттерны. Копируйте паттерны в буфер обмена.
* Импортируйте/экспортируйте вашу библиотеку через CSV.
Почему?
* Экономия времени - больше не нужно искать в заметках или перепечатывать сложные паттерны.
* Снижение ошибок - используйте ваши протестированные и валидированные регекспы каждый раз.
https://chromewebstore.google.com/detail/regex-manager/mdcmehmegkigaonhnjhpcigplhjeohim
@
Читать полностью…
Mike Blazer
30 April 2025 13:10
Похоже, что инструмент проверки URL в GSC устанавливает дневную квоту отправок "на аккаунт Google", а не "на домен".
Я отправил 10 URL (новых страниц) на одном домене и достиг лимита квоты, пишет Билл Хартзер.
Но затем перешёл к домену другого клиента, в том же аккаунте Google, и не смог отправить - потому что уже исчерпал квоту.
Я не отправлял никаких URL на том домене больше месяца.
Сталкиваетесь ли вы с той же проблемой достижения квоты "на аккаунт", а не "на домен"?
-
То, что Google вводит лимит на проверку страниц, сделает SEO намного, намного сложнее...
@
Читать полностью…
Mike Blazer
30 April 2025 08:15
Бринна была озадачена, потому что заметила расхождение между данными GSC и своими серверными логами.
Консоль показывала, что Google обращался к определенной странице в конкретную дату и время, но она не смогла найти соответствующую запись в своих лог-файлах, даже с учетом разницы часовых поясов и проверки соседних дней.
Она исследовала эту проблему в контексте падения краулингового бюджета от Google после запуска теста на нескольких страницах и пыталась определить дальнейшие шаги.
Джон Мюллер предложил кликнуть на "view crawled page" / "more info" / "http response", чтобы увидеть, что сервер ответил в тот момент.
Он объяснил, что иногда GSC показывает более старую дату, что может указывать на то, что Google просто проверил кэш или сделал HEAD или if-modified-since запрос, чтобы увидеть, изменилась ли страница, вместо того, чтобы делать полный краулинг.
Он предоставил скриншот-пример с одного из своих собственных URL-ов сайта, показывающий ту же проблему, с которой столкнулась Бринна.
Джон упомянул, что такая ситуация иногда случается, и пояснил, что обычно никаких действий не требуется, если не были внесены изменения на странице (в этом случае отправка её на индексацию могла бы помочь).
Райан Сиддл спросил, смотрит ли Бринна логи, ближайшие к её точке входа.
Он указал, что у клиентов часто бывает несколько уровней логирования, и если используются сервисы типа Akamai в качестве WAF, то извлечение логов из внутренних Apache/Nginx/Vercel может не показывать доступ Google, если запросы кэшируются или не проходят через эти системы.
Бринна сказала, что она смотрела логи Cloudflare, которые, как она полагала, были их первой линией логирования, но признала, что было бы хорошо перепроверить это.
@
Читать полностью…
Mike Blazer
29 April 2025 15:05
Хотели ли вы знать, какие запросы Google от вас скрывает в GSC?
Те, которые они называют "анонимными запросами".
Ahrefs сопоставили свои данные с данными GSC, и теперь вы можете видеть эту информацию в отчете "Анонимизированные запросы" в разделе GSC.
Они планируют сделать то же самое с отчетом поисковых запросов Google Ads.
Правила анонимных запросов Google излишне широкие.
По их определению, это запросы, которые не искались более 30 раз за последние 13 месяцев 30 отдельными авторизованными пользователями.
Руководитель DuckDuckGo однажды сказал, что это исключает ~99% хвостовых запросов.
Это поможет вам заполнить некоторые из этих пробелов.
@
Читать полностью…
Mike Blazer
29 April 2025 11:05
🚀 Влияет ли скорость загрузки страницы на ранжирование? 🚨
Я провел эксперимент с ноября прошлого года, говорит Джошуа Клэр-Флэгг.
Я создал 2 лендинга; оба с абсолютно одинаковым контентом.
Один был медленный, другой быстрый - с доменами, к которым добавлены суффиксы -s и -f соответственно.
Что показывает Google Search Console для этих страниц?
Быстрая страница получает на +1650% больше кликов и на +1033% больше показов, а также лучшую кликабельность и более высокую среднюю позицию.
Да, я понимаю, что цифры здесь скромные - но это действительно показывает, что Гугл приоритезирует более быстрые страницы, даже в небольшом масштабе!
@
Читать полностью…
Mike Blazer
28 April 2025 17:05
Изощренная фишинговая атака в Google с эксплуатацией уязвимостей инфраструктуры
Недавно я стал целью крайне изощренной фишинговой атаки, и хочу обратить на это внимание, пишет Ник.
Она эксплуатирует уязвимость в инфраструктуре Google, и, учитывая их отказ исправить её, мы, вероятно, будем видеть это всё чаще.
Первое, что стоит отметить — это валидное, подписанное письмо — оно действительно было отправлено с no-reply@google.com.
Оно проходит проверку DKIM-подписи, и Gmail отображает его без каких-либо предупреждений — он даже помещает его в одну переписку с другими легитимными оповещениями безопасности.
Ссылка Sites ведет на очень убедительную страницу "портала поддержки".
Они умно использовали sites.google.com, потому что знали, что люди увидят домен google.com и посчитают его легитимным.
Клик по "Загрузить дополнительные документы" или "Просмотреть обращение" ведет на страницу входа — точную копию настоящей; единственный намек на фишинг в том, что она размещена на sites.google.com вместо accounts.google.com.
Оттуда они собирают ваши учетные данные для компрометации аккаунта.
Так как же им это удалось — особенно валидное письмо?
Это связано с двумя уязвимостями в инфраструктуре Google, которые они отказались исправить.
Поддельный портал сделан довольно просто.
sites.google.com — это устаревший продукт из времен, когда Google еще не так серьезно относился к безопасности; он позволяет пользователям размещать контент на поддомене google.com и поддерживает произвольные скрипты и встраивания.
Это делает создание сайта для сбора учетных данных тривиальным; атакующие просто загружают новые версии по мере блокировки старых.
В интерфейсе Sites нет возможности сообщить о злоупотреблении.
Google осознал, что размещение публичного, заданного пользователями контента на google.com проблематично, но Google Sites по-прежнему существует.
Им необходимо отключить скрипты и произвольные встраивания в Sites, так как это слишком мощный вектор фишинга.
Техника с письмами более изощренная и явно является проблемой безопасности.
Ключевые подсказки в заголовке: хотя письмо подписано accounts.google.com, оно было отправлено через privateemail.com и послано на 'me@blah'.
Ещё одна подсказка: под фишинговым сообщением есть пробелы, за которыми следует "Google Legal Support получил доступ к вашему аккаунту Google" и опять же странный email-адрес me@...
Атакующие:
1. Регистрируют домен и создают аккаунт Google для 'me@domain'
2. Создают OAuth-приложение Google с полным фишинговым сообщением в качестве названия, за которым следуют пробелы и "Google Legal Support"
3. Предоставляют своему OAuth-приложению доступ к их аккаунту Google 'me@...', генерируя легитимное сообщение 'Оповещение безопасности'
4. Пересылают это сообщение жертвам
Поскольку DKIM проверяет только сообщение и заголовки (но не конверт), оно проходит валидацию подписи и выглядит легитимным — даже в одной переписке с реальными оповещениями безопасности.
Имя пользователя 'me@' заставляет Gmail отображать, что сообщение было отправлено на 'me', что является сокращением для вашего собственного email-адреса, избегая еще одного красного флага.
Google отклонил отчет об ошибке как "Работающий как задумано" и не считает это проблемой безопасности.
Пока они не изменят своего мнения, будьте бдительны к обманчивым оповещениям безопасности от Google.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}