Mike Blazer
20 мая 2025 11:05
Народ, чекайте сертификаты доменов!
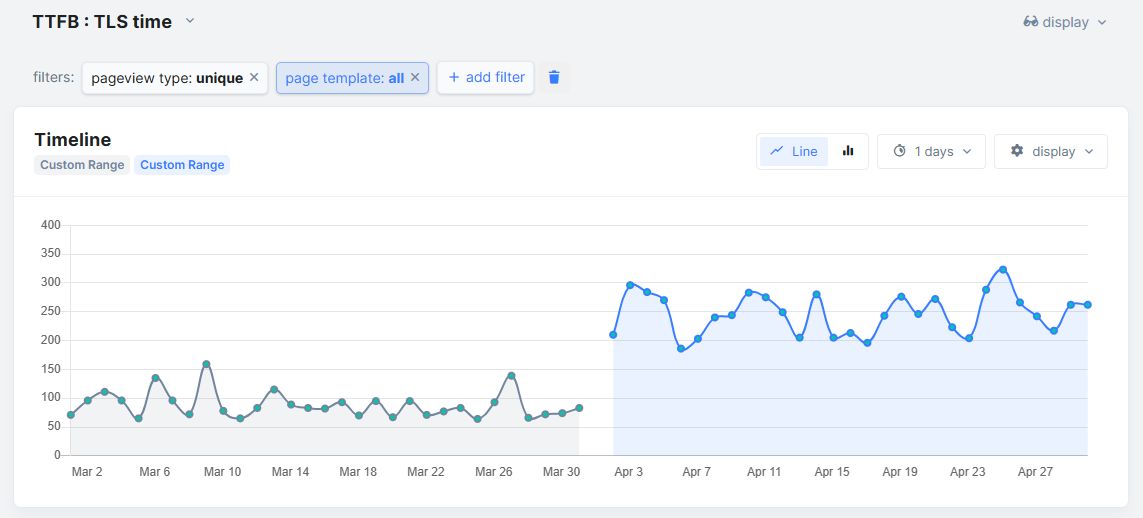
В этом кейсе смена типа HTTPS-сертификата привела к регрессии на 196.5%, поскольку время TLS увеличилось с 86 до 255 мс (на мобильных P90), пишет Эрвин Хофман.
Предыстория:
— От имени моего клиента я попросил включить HTTP2, чтобы выжать максимум из скорости сайта.
— 1 апреля этот хостер перепробовал всё.
— Но в итоге они также включили сертификат расширенной проверки (EV) для этого домена.
Проблема:
— EV-сертификаты также подразумевают использование OCSP stapling,
— что влечёт за собой гораздо более сильное негативное влияние на веб-производительность,
— на что также ясно указывали данные мониторинга RUM CWV.
Решение:
— На самом деле нам нужен был HTTP2, а не ухудшенное время TLS.
— Хостер ещё неделю пытался, но безуспешно.
— Поэтому вчера мы в итоге перенесли весь сайт на другой хостинг.
EV vs DV сертификаты:
Среднестатистическому сайту/магазину вполне достаточно сертификата проверки домена (DV) вместо EV-сертификата.
Более того, браузеры всё равно уже убрали видимое различие между EV и DV.
Именно поэтому этому сайту не был нужен EV-сертификат, и мы решили не включать его после переезда на новый хостинг, чтобы вернуть потерянную производительность.
Самое приятное: мы уже видим улучшения (пока не на этом графике).
@
Читать полностью…
Mike Blazer
19 мая 2025 17:05
Первый первоисточник, подтверждающий, что Google использует данные Chrome в качестве сигнала популярности в контексте ранжирования — новые данные Министерства юстиции США:
III. Другие сигналы
— eDeepRank. eDeepRank — это LLM-система, которая использует BERT и трансформеры. По сути, eDeepRank пытается брать сигналы на базе LLM и раскладывать их на компоненты, чтобы сделать их более прозрачными. HJ не особо в курсе деталей eDeepRank.
— PageRank. Это единичный сигнал, связанный с удаленностью от известного качественного источника, и он используется как входной параметр для показателя качества.
— [redacted] сигнал (популярности), который использует данные `Chrome`.
@
Читать полностью…
Mike Blazer
19 мая 2025 13:10
Внутренний документ Google, Trial Exhibit PXR0357, обнародованный в ходе антимонопольного дела США, содержит заявление под присягой вице-президента Google по поиску, Хён-Джина Кима.
Ким показал, что внутренний сигнал Q* (Кью-Стар) играет "чрезвычайно важную" роль в ранжировании.
Этот сигнал, согласно документу, оценивает качество отдельных страниц, но Google, вероятно, интерпретирует эти оценки в контексте всего сайта.
Название Q* публично не объяснялось. "Q" традиционно означает "Quality" (качество) (как в PQ, HQE, QRG), а "*" может означать 'wildcard' или обобщенную комплексную оценку, делая Q* потенциальной мета-метрикой: системной, расчетной оценкой доверия, а не просто баллом.
Если контент не ранжируется или трафик падает, несмотря на оптимизацию и качество, недостающий элемент — Q*, а не ключевые слова или бэклинки.
Сигнал работает незаметно и системно в фоновом режиме.
Оценка Q* на уровне документа, интерпретируемая в масштабе домена, объясняет пользу удаления слабых, малоценных или нерелевантных страниц для крупных сайтов.
Удаляя "Q*-low-performers" (страницы с низким Q*), такие как дубли и малоценный контент, сайт снижает балласт в индексе, защищает системное доверие домена и улучшает его совокупный профиль доверия.
Доверие не просто зарабатывается, а рассчитывается Q* – вероятно, на основе пользовательских сигналов, ссылочных паттернов, рисков спама и поведения бренда.
Симптомы низкого Q*:
— обвал CTR,
— волатильность позиций,
— контент, выглядящий "деприоритизированным",
что указывает на потерю доверия со стороны системы.
Ханнс Кроненберг задокументировал более 20 случаев в сегменте, где домены систематически менялись видимостью: прирост одного почти зеркально отражал потери другого.
Этот феномен, названный "порядок ранжирования Q*", предполагает, что кажущиеся эффекты от обновления ядра часто являются внутрисегментной "гонкой за доверием".
Проигрыш в этой гонке означает потерю не только позиций, но и системной релевантности, даже при качественном контенте.
Чтобы повлиять на Q*, нужно забыть о краткосрочных хаках, так как он реагирует на долгосрочное поведение.
Q*, по сообщениям, отдает предпочтение брендам, узнаваемости и последовательности, демонстрируемым месяцами.
Google доверяет не "хорошим", а тем, кто ведет себя как уже доверенные им сущности.
Прогнозируется, что Q* может стать новым PageRank: публично неизмеряемым, напрямую не контролируемым, но решающим.
Сеошники, оптимизирующие только под ключевые слова, рискуют упустить этот фундаментальный сигнал.
Команды, стратегически выстраивающие доверие через поведение пользователей, узнаваемость и управление брендом, будут не просто конкурировать за видимость, а получат системное предпочтение.
https://www.linkedin.com/pulse/google-enth%C3%BCllt-q-der-unsichtbare-trust-score-kosten-kann-kronenberg-2dude/
Еще нюансы:
— У Гугла есть внутренний дебаггер, в котором они могут смотреть веса сигналов для каждого документа по конкретному запросу.
— Традиционный подход Гугла к ранжированию напоминал Okapi BM25 — это функция ранжирования, используемая для оценки релевантности документов по отношению к заданному поисковому запросу.
— RankEmbed — это дуал-энкодер модель (dual encoder model), которая эмбеддит (преобразует в векторное представление) и запрос, и документ в пространство эмбеддингов (embedding space).
— Пространство эмбеддингов (embedding space) учитывает семантические свойства запроса и документа наряду с другими сигналами.
— Выборка и ранжирование затем представляют собой скалярное произведение (dot product) (меру расстояния в пространстве эмбеддингов).
— Navboost описывается как QD table (таблица "query-document" - таблица поиска "запрос-документ"). Она используется в обоих направлениях и содержит счетчики/частоты (counts/frequencies) пользовательской активности по запросам (user query activity) для каждого документа.
@
Читать полностью…
Mike Blazer
19 мая 2025 08:15
🆕 Что там с использованием CTR в ранжировании?
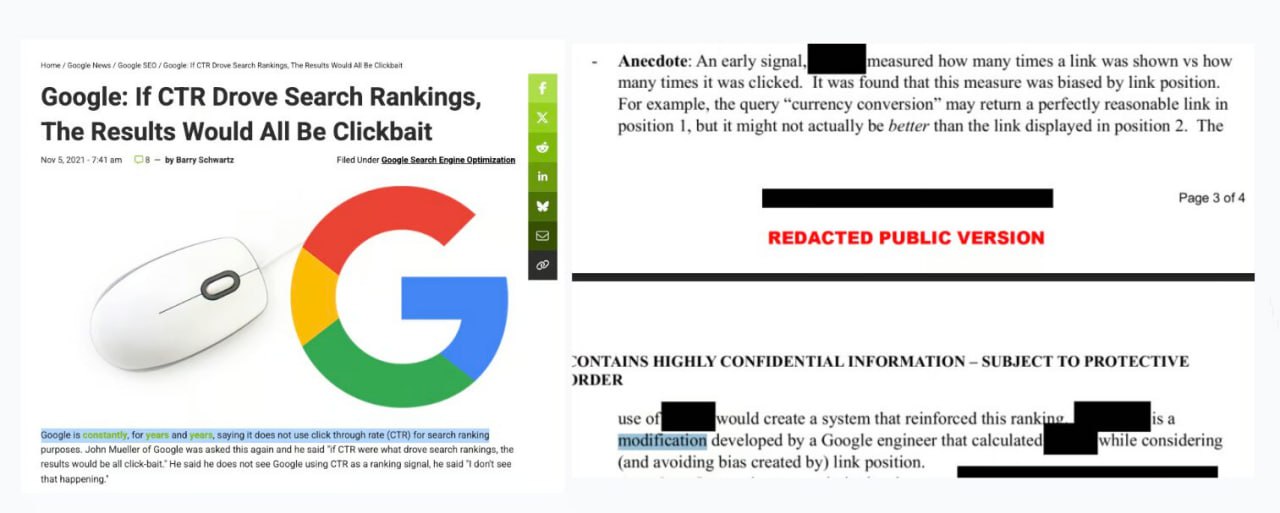
Google годами твердил SEO-сообществу, что не использует CTR, но теперь из интервью Панду Наяка, инженера Google Поиска с многолетним стажем, в рамках судебных разбирательств Минюста США, стало известно обратное.
Панду Наяк сообщил Минюсту США:
Один из ранних сигналов измерял, сколько раз ссылка была показана в сравнении с количеством кликов по ней.
Выяснилось, что этот показатель искажался позицией ссылки.
... это модификация, разработанная инженером Google, которая производила расчет ... с учетом (и для устранения искажения, вносимого) позицией ссылки.
Так что, технически, Google не только использует
CTR для корректировки ранжирования, но и разработал более совершенные формулы для нормализации данных, учитывающие также позицию ссылки в поисковой выдаче.
Источник — интервью инженера Google Панду Наяка от 31 января 2025 года в рамках антимонопольного дела Минюста США против Google, обнародованное Минюстом 2 мая 2025 года:
https://www.justice.gov/atr/media/1398866/dl@
Читать полностью…
Mike Blazer
18 мая 2025 11:35
Хотел бы я, чтобы Google разрешил создать карту сайта, куда я мог бы загрузить очень старые URL и просто сказать: пожалуйста, перестаньте пытаться их запрашивать... эти URL были изменены вот на эти... 8 лет назад, и мы не хотим, чтобы вы продолжали их запрашивать, пишет Гэган Готра.
Google пытается запрашивать в среднем 2.5-3 миллиона старых URL каждую неделю, и они СТАРЫЕ - редирект был сделан еще 8 лет назад!
Заголовки cache-control для старых URL установлены на 1 год.
Для OLD на NEW настроен 301, затем 304 для одного набора URL, а для другого набора это запрос OLD с возвратом 410.
У этого набора OLD нет многих качественных бэклинков, поэтому я решил напрямую возвращать 410, а у другого набора так много качественных ссылок, что поэтому делаю 301.
Но даже для набора с 410 Гуглобот по какой-то причине продолжает делать запросы.
@
Читать полностью…
Mike Blazer
17 мая 2025 10:05
После ручных санкций, GeeksforGeeks закрыли доступ к подпапке /community/ своего форума в файле robots.txt, и вот что теперь происходит в результатах поиска...
Вероятно, вместо блокировки в файле robots, им следовало бы установить запрет на индексацию на уровне страницы...
Больше о их бане читайте тут, тут и тут.
@
Читать полностью…
Mike Blazer
16 мая 2025 15:05
Гайд: как заходить в GSC без футпринтов
@
Читать полностью…
Mike Blazer
16 мая 2025 11:05
Python-инструмент для обхода анти-бот страниц Cloudflare с помощью Requests
https://github.com/VeNoMouS/cloudscraper
@
Читать полностью…
Mike Blazer
15 мая 2025 17:05
Ваше навигационное меню может стоить вам трафика 📉
Вот почему 👇
Часто сайты используют креативные названия пунктов меню вроде:
❌ "Подарки и радости"
❌ "Для малыша"
❌ "Предметы первой необходимости"
Но проблема в том... что никто не ищет эти фразы.
Вместо этого, попробуйте фразы, которые люди реально ищут:
✅ "Уникальные идеи подарков"
✅ "Подарки для новорожденных"
✅ "Экологичные чистящие средства"
🧠 Простой аудит навигации может привести к быстрым победам в SEO:
1️⃣ Проверьте анкоры в навигационном меню
2️⃣ Проверьте тайтлы этих страниц или ключи, по которым они ранжируются
3️⃣ Замените креативные названия на фразы, которые ваши клиенты реально ищут
Небольшая правка. Большой прирост трафика.
@
Читать полностью…
Mike Blazer
15 мая 2025 13:10
Gym Shark получает 319 000 ежемесячных посещений от небрендовых поисковых запросов.
Более $400 000 оценочной стоимости трафика по данным Semrush (на самом деле они зарабатывают гораздо больше).
Их позиции?
— #1 по запросу "sports bra" (27 000 поисков)
— #1 по запросу "workout sets" (22 000)
— #1 по запросу "flared leggings" (27 000)
— #1 по запросу "gym bag" (50 000)
— #1 по запросу "athletic shorts" (10 000)
— #1 по запросу "oversized tees" (10 000)
— #1 по запросу "workout tops" (18 000)
Но спорим, вы никогда не догадаетесь, что является их секретным оружием...
Стратегическая внутренняя перелинковка.
На их страницах коллекций есть:
— Внутренние ссылки, размещенные по всему описанию коллекций
— Множество дополнительных ссылок внизу страниц
— Ссылки на подколлекции с использованием точных анкоров
Если вы посетите их страницу "workout sets", там повсюду ссылки на связанные категории:
Комбинезоны, спортивные комплекты, бесшовные комплекты...
Красиво ли это?
Возможно, нет.
Но это прибильно!
Когда приходится выбирать между эстетикой и дополнительными несколькими миллионами в месяц от органического дохода... выбор кажется очевидным.
-
"Дизайнеры, видимо, ушли с совещания до того, как всё утвердили."
И в этом вся суть.
Это просто обычные текстовые ссылки вверху/внизу страниц коллекций.
Они оптимизированы для МАКСИМАЛЬНОГО дохода через SEO... и руководству Gymshark, которое собирает дополнительные продажи благодаря им, пофиг, как они выглядят.
Что бы вы предпочли: "красивые" страницы или трафик такого уровня?
Да, ссылочный профиль Gymshark – важный фактор их успеха.
Их узнаваемость бренда огромна.
Но если бы они завтра убрали эти "уродливые" внутренние ссылки, их органический небрендовый трафик, вероятно, значительно снизился бы.
Внутренняя перелинковка часто является самым быстрым способом повысить позиции страниц коллекций, особенно когда вы ставите функциональность выше формы.
Многомиллиардные компании это понимают.
Они не позволяют дизайнерским предпочтениям перевесить решения, приносящие доход.
Иногда "уродливое" решение – это то, что оплачивает счета.
@
Читать полностью…
Mike Blazer
15 мая 2025 08:15
Когда позиции клиента резко упали с #3 до страниц 2-3 по основным запросам в пик сезона, Кевал Шах определил, что Google изменил поисковый интент для этих запросов.
Что произошло
Google переключился с ранжирования страниц категорий товаров на предпочтение главных страниц брендов для целевых запросов клиента.
Решение
Были реализованы три простых шага:
1. Оптимизировали мета-тайтл главной страницы, используя формат "[Запрос] | [Название бренда]"
2. Сделали редирект с ранжирующейся страницы категории на главную, передав ссылочную массу
3. Воссоздали страницу категории с новым URL, чтобы сохранить юзабилити без конкуренции за основные запросы
Результаты
— В течение 24 часов: Позиции улучшились до середины первой страницы
— Через неделю: Клиент достиг #1 позиции по целевым запросам
@
Читать полностью…
Mike Blazer
14 мая 2025 17:05
Недавно опубликованные документы по антимонопольному делу Министерства юстиции США против Google раскрывают интересную инфу:
Поисковый индекс состоит из фактического контента, который прокраулен (заголовки и текст), и ничего больше, т. е. это инвертированный индекс.
Существуют также другие отдельные специализированные инвертированные индексы для других целей, таких как фиды из Twitter, Macy's и т. д.
Они хранятся отдельно от индекса для органических результатов.
Это касается только 10 синих ссылок, но некоторые сигналы хранятся для удобства в индексе поиска.
Сигналы на основе запросов не хранятся, а вычисляются во время запроса.
https://www.justice.gov/atr/media/1398871/dlMacy's это e-commerce ритейлер.
Это наводит на мысль, что для каждого крупного сайта у Гугла может быть отдельный индекс.
Обмозгуйте это перед сном...
@
Читать полностью…
Mike Blazer
14 мая 2025 13:10
Исследование ключевиков с помощью только Google Search Console?
Без Ahrefs.
Без Semrush.
Только данные, которые Google уже предоставляет вам. 👇
Мы использовали именно этот метод, чтобы извлечь 390 172 ключевых слова с одного сайта и создать контент-план, построенный исключительно на реальном поисковом поведении, пишет Стив Тот.
Результат?
Революционный.
— Тысячи низкоконкурентных ключей с высоким интентом
— Напрямую связаны с вашими существующими страницами
— Отфильтрованы, обогащены и готовы к использованию
Мы использовали это для планирования SEO-контента на 6+ месяцев.
Все подкреплено данными.
Никаких догадок.
Каждый месяц (начиная с 16 месяцев назад) мы выполняли 4 отдельных выгрузки ключевых слов:
1) "обычная выгрузка" без параметров регулярных выражений
2) регулярное выражение для ключей с 3+ словами
3) регулярное выражение для 6+ слов
4) регулярное выражение для вопросительных запросов
Вот регулярное выражение:
1) нормальное извлечение, не требуется.
2) ([^" "]*\s){2,}? (3+ слова)
3) ([^" "]*\s){5,}? (6+ слов)
4)
^(who|what|where|when|why|how|was|wasn't|wasnt|did|didn't|didnt|do|is|isn't|isnt|are|aren't|arent|will|won't|wont|does|doesn't|doesnt|should|shouldn't|shouldnt|were|weren't|werent|would|wouldn't|wouldnt|can|can't|cant|could|couldn't|couldnt)[" "]
Даже если вы не попробуете весь метод, можете использовать регулярку прямо в
GSC, чтобы получить отличные результаты.
@
Читать полностью…
Mike Blazer
14 мая 2025 08:15
Метод Link Lazarus использует битые ссылки из Википедии
Йесилюрт обнаружил, что дроп-домены с бэклинками из Википедии сохраняют ценные сигналы авторитетности, которые часто не замечаются популярными SEO-инструментами.
Его метод улучшает традиционные подходы работы с битыми ссылками через:
— Глубокий анализ контента: Изучение архивного контента для выявления связей между сущностями
— Стратегическое маппирование: Сопоставление просроченных доменов с релевантным контентом
— Редиректы на основе интента: Сохранение тематической целостности
— Улучшенное воссоздание контента: Повышение ценности контента, когда это выгодно
Популярные инструменты вроде Ahrefs и Semrush часто не показывают обратные ссылки из Википедии на просроченные домены.
Python-инструмент Йесилюрта на базе Streamlit систематически находит эти возможности путем краулинга Википедии, извлечения внешних ссылок, определения мертвых и проверки доступности доменов.
https://huggingface.co/spaces/metehan777/link-lazarus
(Ограничен 20 результатами/страницами вики.)
Рабочий процесс включает:
1. Сканирование Википедии через поиск по ключевым словам и краулинг категорий
2. Анализ контента через Archive.org
3. Проверку домена через WHOIS и DNS-чеки
4. Маппинг контента с помощью ИИ и эмбеддингов
5. Редиректы на основе топиков, сохраняющие релевантность
Результаты демонстрируют эффективность метода:
— AppSamurai доминировал на первой странице выдачи по целевым запросам
— Сайт в конкурентной нише поднялся с позиции #23 на #2
— Выявлено 1 862 просроченных домена на страницах Википедии на разных языках
— Новый домен в конкурентной нише показал значительное улучшение за 3 недели
— Обнаружены домены с цитированием из Гарварда, MIT и правительственных источников
Метод Link Lazarus работает не только с Википедией, но и с другими авторитетными платформами.
https://metehan.ai/blog/link-lazarus-method/
@
Читать полностью…
Mike Blazer
13 мая 2025 15:05
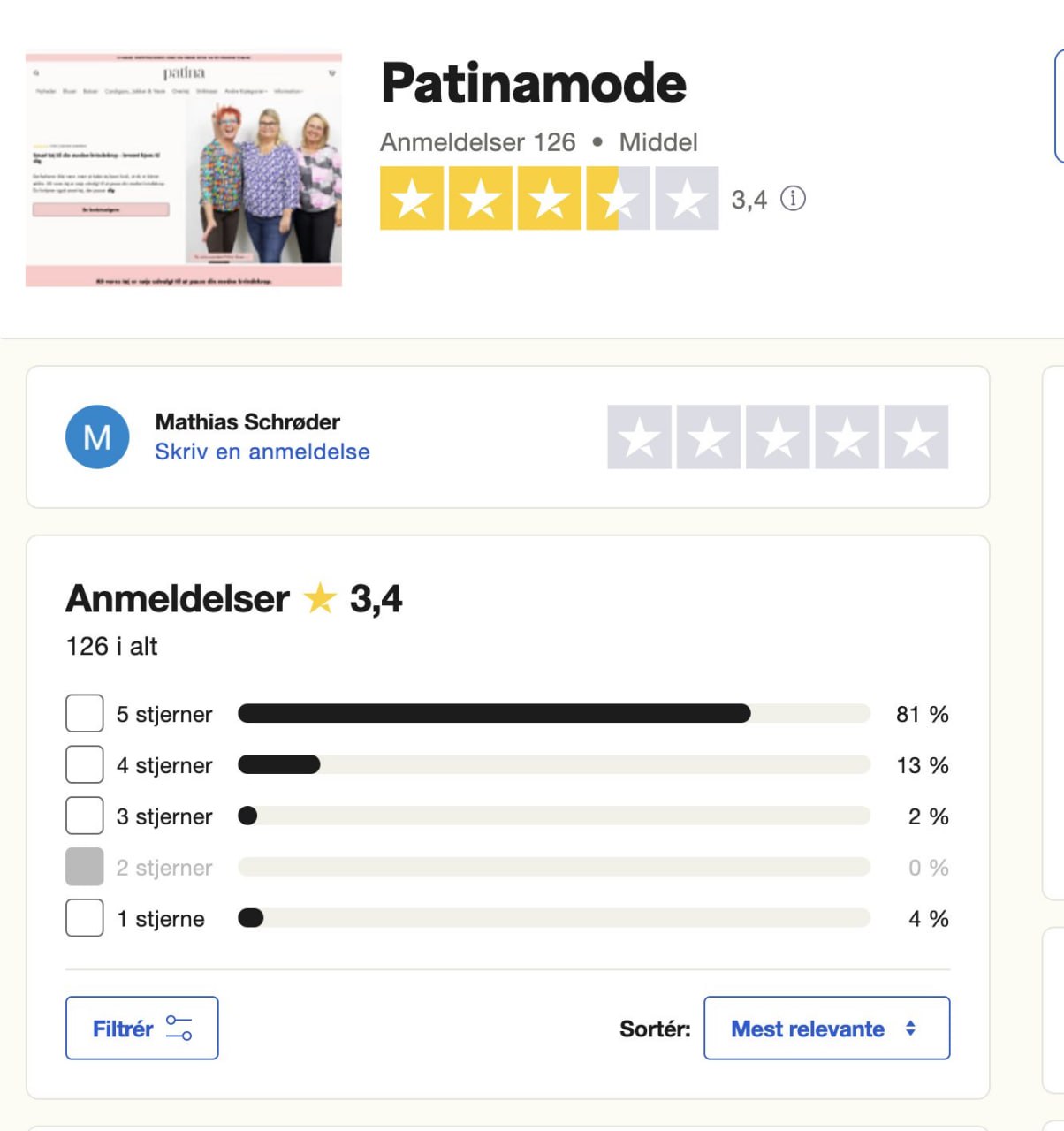
Вау, TrustPilot - это просто развод, мошенничество и все прочие подобные слова, которые только можно придумать.
Я случайно заметил, что у нас средний рейтинг 3.4 по отзывам на Trustpilot, говорит Матиас Шрёдер.
Что казалось странным, учитывая, что у нас средний балл 4.9 по 7660 отзывам через Judge Me Reviews.
Так что я посчитал.
У нас 126 отзывов на Trustpilot:
1 звезда: 5
2 звезды: 0
3 звезды: 2
4 звезды: 16
5 звезд: 103
Среднее арифметическое: 4.68
Средний балл по версии Trustpilot, то есть их TrustScore: 3.4 🙃
Какого хрена?
Их объяснение:
"Расчет основан на различных параметрах, таких как общее количество отзывов компании и дата создания отзывов.
На TrustScore также влияет то, активно ли компания приглашает своих клиентов оставлять отзывы или нет."
Позвольте мне перевести это для вас:
Trustpilot намеренно занижает средние рейтинги продавцов, использующих другие платформы для отзывов, и маскирует это под собственный "алгоритм TrustScore".
На самом деле, единственный способ получить много отзывов, свежие отзывы и активно приглашать клиентов оставлять отзывы на Trustpilot - те самые "различные параметры" в их объяснении - это... использовать Trustpilot.
Последнее предложение, которое я получил от Trustpilot, было $400 в месяц.
И это было более 5 лет назад, когда мы были лишь частью того бизнеса, которым являемся сегодня.
Так что, поскольку я не готов платить эту сумму, которая, я не удивлюсь, сейчас уже превышает $1000 в месяц, они просто портят нашу репутацию, выдавая нам низкий рейтинг.
РАЗВОД.
@
Читать полностью…
Mike Blazer
20 мая 2025 08:15
Вращающиеся Редиректы
Вращающиеся редиректы - это агрессивная SEO-тактика, которая в основном используется в стратегиях "сжечь и заработать" (churn and burn).
Основная идея заключается в постоянном перенаправлении ссылочной массы с забаненного сайта на новый, активный.
Как это работает:
1. Создается сайт, который агрессивно спамится ссылками для быстрого достижения высоких позиций.
2. После монетизации этот сайт в конечном итоге получает санкции от поисковых систем.
3. Вместо потери силы ссылок, построенных на сожженный сайт, внедряются вращающиеся редиректы. Они перенаправляют входящую ссылочную массу на *следующий* новый сайт в последовательности (Сайт A -> Сайт B -> Сайт C и так далее).
4. Сами ссылки считаются хорошими; штраф получает именно *целевой сайт*.
Зачем их использовать?
— Сохранение ссылочной ценности: Гарантирует, что ценная ссылочная масса, построенная на сайт, не теряется, когда конкретный домен получает санкции.
— Непрерывная монетизация: Позволяет постоянно генерировать доход, быстро перенаправляя силу ссылок на свежий, незабаненный домен.
— Упреждение негативных эффектов: Поскольку обработка ссылок Гуглом может задерживаться, смена цели этих ссылок может произойти *до того*, как потенциальное негативное влияние полностью материализуется на текущем монетизируемом сайте.
Ключевые моменты:
— Они активно используются в конкурентных, часто нерегулируемых рынках (например iGaming).
— Хотя технически возможно, автоматизация вращающихся редиректов рискованна и "очень легко всё зафакапить". Критический триггер - точное определение момента, когда сайт получает бан - трудно надежно автоматизировать. Часто предпочтительнее ручное управление опытным специалистом.
@
Читать полностью…
Mike Blazer
19 мая 2025 15:05
Из недавних судебных документов стало известно, что внутренние тесты Google показали: даже существенное ухудшение качества поисковой выдачи не повредит их бизнесу.
Такая очевидная невосприимчивость к проблемам с качеством, по-видимому, обусловлена доминирующим положением компании на рынке, на которое и обратил внимание недавний вердикт федерального суда.
> "Поскольку у Google нет реальной конкуренции, он может затруднять поиск лучшей информации, заставляя пользователей дольше оставаться на страницах Google и взаимодействовать с большим количеством рекламы", — отметил Пападимитриу.
> "Это опасно для пользователей, большинство из которых уверены, что лучшие результаты всегда показываются первыми".
Судя по всему, с точки зрения бизнеса эта стратегия работает.
Исследование предполагает, что низкое качество органической выдачи на самом деле выгодно Google по двум причинам:
— платная реклама становится более ценной для пользователей, ищущих точную информацию;
— пользователи вынуждены многократно уточнять свои поисковые запросы, что приводит к большему количеству показов рекламы.
@
Читать полностью…
Mike Blazer
19 мая 2025 11:05
В ближайшие 10 лет ценность "образовательного контента блогов" как маркетинговой стратегии снизится до нуля.
Практически все информационные запросы будут решаться с помощью LLMs в тех местах, где мы уже проводим время: в наших приложениях для обмена сообщениями и ведения заметок, в наших почтовых клиентах, в наших социальных сетях.
Не будет никаких причин посещать ресурсный центр случайной SaaS-компании только для того, чтобы найти полезную информацию.
Появятся сотни гораздо более удобных способов доступа к информации, каждый из которых будет персонализирован с учетом конкретных потребностей и предпочтений каждого пользователя.
Мы сможем получать информацию именно в том формате, в котором нам нужно: на том языке и в том тоне, которые нам нравятся, в контексте наших предыдущих разговоров, в тех местах, где мы хотим ее видеть.
Не останется места для перепечатанного контента из Википедии, размещенного на одной из сотен похожих статических HTML-страниц.
Никто не будет мириться с трениями, вызванными контент-маркетингом.
Пользователи больше не будут испытывать неудобства, просматривая корпоративные задворки Интернета, чтобы узнать, как установить программное обеспечение или приготовить обычное блюдо.
Компании больше не будут получать экономическую выгоду от простого информационного арбитража.
Неустойчивое перемирие, которое мы терпели в течение последнего десятилетия, закончится.
Мы наконец-то поставим точку в эпохе информационного арбитража как доминирующей маркетинговой стратегии.
Но вот в чем суть: маркетинг существовал до появления этой странной маленькой лазейки, и он будет существовать после нее.
Маркетинговые стратегии, которые сегодня находятся на подъеме, не являются новыми или необычными: мероприятия, брендинг, реклама, социальные сети.
Мы не отказываемся от маркетингового сценария, а просто пропускаем его.
Каждая маркетинговая тактика является частью цикла внедрения, насыщения и отказа.
Технологии ускорили этот процесс, но он существовал всегда.
Страшно видеть, как доминирующая маркетинговая стратегия последнего десятилетия сжимается и увядает с такой угрожающей скоростью, но это не должно быть неожиданностью.
Закон плохих кликов всегда побеждает: когда какая-либо тактика становится слишком популярной, ее эффективность начинает снижаться.
LLM значительно ускорили этот процесс, но, на мой взгляд, мы уже давно находимся на нисходящей кривой "образовательного контента для блогов".
Работа с такими изменениями — часть нашей работы.
Маркетинг — это постоянное стремление к новизне: как мы можем быть заметными и отличаться от других компаний?
Лучшие маркетологи гибки, критичны и достаточно рискованны, чтобы пробовать новые, странные, нарушающие шаблоны стратегии без гарантии успеха.
Люди, которые наиболее привязаны к "контентной" части "контент-маркетинга", могут столкнуться с трудностями в ближайшие несколько лет, но те, кто принимает "маркетинговую" часть своей работы, ждет фантастическое десятилетие.
@
Читать полностью…
Mike Blazer
18 мая 2025 16:05
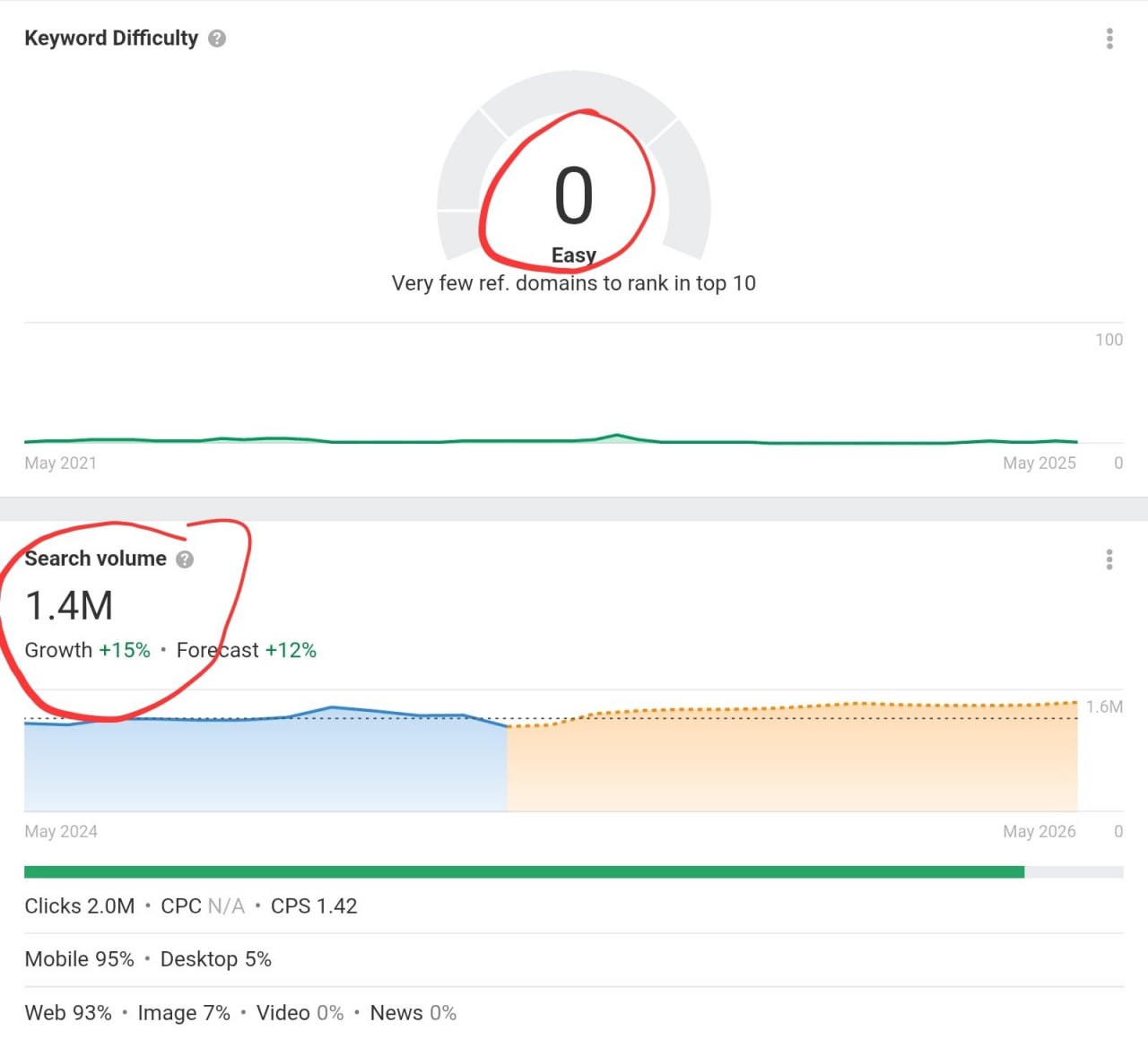
Я не могу не улыбаться каждый раз, когда вижу, как Ahrefs показывает эти два противоречивых метрики.
Как можно легко ранжироваться по ключу с таким высоким поисковым объемом?
@
Читать полностью…
Mike Blazer
17 мая 2025 14:05
На прошлой неделе я принял звонок от одного из ведущих агентств по оптимизации LLM, рассказывает Зак Нотс.
Как сеошнику, мне было очень интересно.
Вот их предложение, вместе с моими мыслями...
— За $15К+ в месяц они будут поддерживать ваше ранжирование по одному ключевому слову в ChatGPT.
Если вы не ранжируетесь, вы не платите.
Я был довольно удивлен, услышав, что они предлагают такую структуру оплаты, особенно учитывая, что результаты меняются от промпта к промпту.
Они сказали, что больше всего тяги получают в B2B.
Учитывая стоимость, я думаю, вполне вероятно, что некоторые компании из Fortune 500, такие как Salesforce, платят за топовые ключи вроде "Best CRM".
— Они добиваются высоких позиций, манипулируя природой Reinforcement Learning (RL) у LLM; предоставляя "фидбек" LLM для изменения их выдачи.
Я точно не знаю, как это выглядит, но предполагаю, что это происходит в форме пользовательских ответов на изначальный промпт.
Это удивило меня, потому что я думал, что RL происходит отдельно, во время обучения.
Я спросил, используют ли они ботов или что-то вроде Amazon Turk, и они сказали, что используют оба метода.
— Они также манипулируют референсными документами, которые цитируют LLM, и эти документы могут находиться как на домене клиента, так и вне его.
Что касается изменений вне домена, это фактически возвращает нас в 2012 год до Penguin, когда покупные ссылки двигали позиции.
— Они утверждали, что трафик от LLM в GA4 часто неправильно атрибутируется как прямой, поэтому реальная ценность трафика намного выше, чем осознает большинство брендов.
Я видел, что и другие говорят то же самое об этом.
Это заставляет меня думать, что многие бренды, платящие за эту услугу, не рассчитывают на солидный трекинг и атрибуцию, это топовое $$$ повышение узнаваемости бренда.
@
Читать полностью…
Mike Blazer
16 мая 2025 17:05
Когда уходящее SEO-агентство передает проект новому.
@
Читать полностью…
Mike Blazer
16 мая 2025 13:10
Топ Гугла в рилтайме
@
Читать полностью…
Mike Blazer
16 мая 2025 08:15
Хоть Google и может измерять "консенсус", это не значит, что ваша страница должна соответствовать этому консенсусу для ранжирования. ⤵️
Существует много поисковых запросов, на которые нет объективно "правильного" ответа, и поэтому Google может стремиться предоставить различные точки зрения. 🚦
Это может объяснить, почему вы не ранжируетесь.
Если вы создали контент, "соответствующий консенсусу", а ваш клиент спрашивает: "Почему мы не ранжируемся, когда наш контент лучше по всем параметрам чем тот, что на позициях #2 и #4" - это может быть правдой, но Google специально хочет разместить на этих позициях нейтральные или несогласные с консенсусом документы. ☝️
Дело не в том, что ваш контент плохой, просто он не вписывается в рецепт того, что они пытаются приготовить! 👨🍳
@
Читать полностью…
Mike Blazer
15 мая 2025 15:05
Жизнь в налоговом раю: переезд из Германии на Кипр
Переезд из Германии на Кипр, чтобы уйти от налоговой ставки в 50% в пользу более привлекательных 12.5%, на бумаге казался идеальной оптимизацией в Excel-табличке, пишет Оле Леманн.
Будучи "табличным гуру" в Берлине, это казалось взломом секретного кода, но реальность показала, что я решал совершенно не то уравнение.
Жизнь в налоговой гавани оказалась гораздо сложнее и затратнее, чем ожидалось, фактически разделяя тебя как личность, когда вся жизнь организована вокруг налоговой оптимизации.
Требование о 60-дневном резидентстве на Кипре, которое изначально казалось выполнимым, в итоге стало контролировать каждый аспект жизни.
Визиты к семье, командировки и спонтанные возможности превратились в сложные расчеты риск-менеджмента резидентства.
По сути, одно ограничение (высокие налоги) сменилось другим (постоянный подсчет дней).
Физическая удаленность от основных инновационных хабов вроде SF, NYC и Сингапура оказалась губительной для развития бизнеса.
Находиться вдали от реальных инновационных центров стоит дороже любой налоговой экономии – энергетику и возможности, циркулирующие в этих локациях, невозможно воспроизвести в налоговом раю.
Бизнес растет медленнее в налогово-эффективных зонах, независимо от экономии на бумаге, при этом теряется доступ к критически важным драйверам роста бизнеса.
Проблемы с инфраструктурой и логистикой создавали постоянное трение, превращая простые задачи в многоступенчатые челленджи.
Обычная стойка для приседаний ехала три недели из-за особенностей логистики ЕС и островного положения.
Базовые бизнес-потребности сталкивались с повышенными расходами на доставку, а содержание нескольких жилищ плюс частые экстренные перелеты быстро съели обещанную налоговую экономию.
Профессиональная сеть контактов деградировала несмотря на Zoom-коллы, поскольку ничто не могло заменить случайные знакомства в реальных инновационных хабах.
Среда налоговой гавани привлекала людей с мышлением защиты капитала, а не его создания, где разговоры крутились вокруг налоговых схем вместо создания значимых венчуров.
Окружение не стимулирует создавать что-то значимое, потому что все здесь временно.
Психологическое влияние оказалось существенным.
Идентичность сместилась от гордого местного предпринимателя, создающего что-то значимое, до очередного экспата в погоне за налоговыми льготами.
Настоящая проблема Германии была не только в налоговой ставке, но в фундаментальном анти-предпринимательском настрое – однако обмен этого на место, ценящее только низкие налоги, не стал улучшением.
Жизнь с временным мышлением создала странное лимбо-состояние с вечной 70%-ной вовлеченностью во все – никаких инвестиций в правильное обустройство дома или офиса.
Построение длительных отношений стало практически невозможным из-за постоянной текучки людей, поддерживающих минимальные требования резидентства.
Комьюнити никогда не укреплялось, так как люди исчезали на месяцы, ненадолго возвращаясь, чтобы снова исчезнуть.
Налоговая оптимизация обошлась ценой реальной оптимизации жизни.
Урок очевиден - если вы не стали бы жить в месте, где нет налоговых преимуществ, не живите там ради налоговых преимуществ.
Истинная цена налоговой оптимизации оплачивается более ценными валютами: временем, энергией, комьюнити и душевным спокойствием.
@
Читать полностью…
Mike Blazer
15 мая 2025 11:05
Первичное ранжирование vs. Повторное ранжирование - Понимание гибридного конвейера оценки Google
Разберём на реальном примере SEO для казино 👇
1. Первичное ранжирование основано на статистической семантике:
Оцениваются сущности, предикаты и распределение фраз.
Здесь начинается индексация - показывая, что вы существуете в семантическом пространстве.
2. Повторное ранжирование происходит через сентенциальную семантику:
Точность, согласованность и извлекаемый смысл вашего контента определяют, поднимитесь вы или упадёте.
Дело не в том, чтобы один раз попасть в ранжирование.
А в том, чтобы выжить в циклах оценки.
3. Эти системы опираются на:
— Количественные проверки (структура, PageRank, охват)
— Качественные проверки (точность повествования, согласованность, удовлетворенность пользователей)
➡️ Вот почему некоторые сайты пропускают определенные фильтры.
Они заранее получают доверие благодаря тематическому авторитету, поэтому мгновенно краулятся и приоритизируются.
4. Система Google гибридная.
— Страница с высоким PageRank может быстро получить ранжирование - но плохие поведенческие сигналы или слабый тематический охват = падение.
— Страница с низким PageRank может быть проигнорирована - если только не получит 10 000+ показов и не запустит более глубокую оценку.
5. Это то, что называется конвейером ранжирования.
Новый проект с идентичным контентом набрал органический трафик через этот конвейер за 28 дней.
Каждый пик трафика = новое состояние ранжирования.
Google не вернется полностью к прежнему состоянию.
Он просто продолжает тестировать, может ли страница заменить другую.
Это не просто SEO.
Это наука информационного поиска в действии.
@
Читать полностью…
Mike Blazer
14 мая 2025 18:05
Кое-что еще из этого же документа
Сигналы ABC (основные сигналы):
(Разработаны инженерами, считаются «сырыми».)
— Якоря (A -anchors): ссылки с исходной страницы на целевую страницу.
— Текст (B - body): термины в документе.
— Клики (C - clicks): исторически, время, которое пользователь провел на странице по ссылке, прежде чем вернуться к SERP.
Эти сигналы, наряду с такими факторами, как Navboost, являются ключевыми компонентами тематичности (T - topicality).
Тематичность (T):
— Оценка релевантности документа запросу (базовый балл).
— Эффективно сочетает (по крайней мере) сигналы ABC относительно ручным способом.
— Оценивает релевантность документа на основе терминов запроса.
— Находился в постоянном развитии до примерно 5 лет назад; сейчас изменения менее значительны.
@
Читать полностью…
Mike Blazer
14 мая 2025 15:05
Букмарклет, который извлекает схему из страниц и сохраняет ее в текстовый файл с разделением между JSON и Microdata:
javascript:(function(){javascript:(function(){function e(){return Array.from(document.querySelectorAll('script[type="application/ld+json"]')).map(e=>e.textContent).join("\n\n")}function t(){return Array.from(document.querySelectorAll("[itemscope]")).map(e=>Array.from(e.querySelectorAll("[itemprop]")).map(e=>`${e.getAttribute("itemprop")}: ${e.textContent.trim()}`).join("\n")).join("\n\n")}function n(e){return e.replace(/^(https?:\/\/)?(www\.)?/,"").replace(/[^a-z0-9]/gi,"_").toLowerCase()}const o=e(),r=t(),c=`JSON-LD:\n${o}\n\nMicrodata:\n${r}`,a=n(window.location.hostname+window.location.pathname),i=new Date().toISOString().split("T")[0],l=`${a}_${i}.txt`,s=new Blob([c],{type:"text/plain"}),p=document.createElement("a");p.href=URL.createObjectURL(s),p.download=l,p.click(),URL.revokeObjectURL(p.href)})();})();@
Читать полностью…
Mike Blazer
14 мая 2025 11:05
Я восстановил трафик 3 сайтов, удалив страницы, на которые владелец купил сотни платных ссылок, говорит Шейн Дутка.
Найти сайты, продающие ссылки, чрезвычайно просто, и мы знаем (благодаря утечке API), что Google встроил в свой алгоритм функции, которые выявляют "BadBackLinks".
Я только что запустил бесплатный инструмент getseoshield.com, который индексирует все сайты, активно продающие ссылки (на данный момент 157,411) по всему интернету.
Мы находим эти ссылки, агрегируя их с различных маркетплейсов, гигов на Fiverr и тех самых нежелательных писем, которые мы все так любим.
Этот сайт позволяет проверить, насколько "токсичен" ваш ссылочный профиль, и увидеть, какие страницы пострадали больше всего.
Если мы находим несколько источников для одной и той же ссылки, мы помечаем сайт как "высокорисковый", то есть получить ссылку с такого сайта хуже, чем с сайта, найденного только из одного источника.
Чем больше платных ссылок относительно неоплачиваемых = более токсичный ссылочный профиль.
Для спасения сайта я обычно перепубликую страницы по новым URL без 301 редиректа (то есть разрывая ссылку).
Разрывая ссылки с сайтов, которые активно продают ссылки, вы потенциально можете восстановить сайт (я делал это 3 разных раза).
Если вы активно покупаете ссылки на линкбилдинговых маркетплейсах, и ваш трафик растет - отлично, но если трафик падает, я бы рекомендовал удалить страницы со слишком большим количеством токсичных ссылок.
Проблема возникает всегда, когда вы перебарщиваете.
Несколько стратегических ссылок с оптимизированным анкором - отлично.
Сотни покупных ссылок с маркетплейсов - не очень.
Больше информации в видео.
@
Читать полностью…
Mike Blazer
13 мая 2025 17:05
Гуглу не важно, лучше ли ваша статья.
Ему важно, уходят ли пользователи с сайта или остаются.
Вот как Чарльз Флоут заманивает по CTR, а затем удерживает на странице:
— Тайтл = кликбейт → Используйте сильные слова + вопросительные модификаторы
— Первые 150 слов = резюме + интригующий CTA → Не давайте ответ сразу
— Добавьте якорные ссылки в оглавление → Манипулируйте метриками глубины просмотра страницы
— Встройте мультимедиа (видео, GIF, слайдеры) в первый экран
— Загружайте похожие статьи в середине контента через AJAX → Держит время на сайте завышенным
Вам не нужен более качественный контент или информация.
Вам нужна лучшая психология кликов.
@
Читать полностью…
Mike Blazer
13 мая 2025 13:10
Вы можете предсказать, будет ли страница деиндексирована!
На основе комплексного исследования 1.4 миллиона страниц на 18 сайтах, проведенного Indexing Insight, выявлена чёткая корреляция между частотой краулинга и статусом индексации.
Ключевые выводы:
1. Порог в 130 дней: Страницы, не краулившиеся более 130 дней, имеют 99% шанс быть деиндексированными.
После 151 дня деиндексация становится практически гарантированной (100%).
2. Корреляция между краулингом и индексацией: Чем дольше страница не краулится, тем выше риск её деиндексации:
— Страницы, краулившиеся в течение 30 дней: 97% остаются в индексе
— Страницы, краулившиеся в течение 100-130 дней: 85-94% остаются в индексе
— Страницы, краулившиеся после 131 дня: Резкое снижение индексации (падает до 0% после 151 дня)
3. Практическое применение: Мониторинг "Дней с последнего краула" через URL Inspection API предоставляет надёжный индикатор страниц, находящихся под угрозой деиндексации.
"CrawlRank" (КраулРанк) - страницы, которые краулятся реже, получают меньше видимости в поиске.
Отметка в 130 дней служит системой раннего предупреждения, позволяющей вебмастерам предпринять превентивные меры до того, как важные приносящие доход страницы исчезнут из индекса.
https://indexinginsight.substack.com/p/new-study-the-130-day-indexing-rule
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}