Mike Blazer
27 мая 2025 13:10
Мы составили список из 30 самых популярных товаров, которые люди покупают в супермаркетах, пишет Фери Кашони.
Затем мы подсчитали, сколько будут стоить эти товары в 9 крупнейших магазинах Великобритании.
Таким образом, мы создали индекс самых доступных супермаркетов в Великобритании.
Мы отправили наши выводы в прессу и получили бэклинки высокого качества в национальных и региональных новостных изданиях Великобритании.
Эта кампания была настоящей ручной работой.
Нам пришлось искать каждый товар на сайте каждого супермаркета и вручную проверять данные.
И это окупилось отличным охватом и крутыми ссылками для нашего клиента.
В 2025 году все хотят автоматизировать процессы, но иногда старая добрая работа руками может дать наилучшие результаты 🤩
@
Читать полностью…
Mike Blazer
27 мая 2025 08:15
Психологический и поведенческий маркетинг #2
Существуют веские аргументы против тенденции принимать решения, основываясь исключительно на том, что легко измерить, — тенденции, часто описываемой как "заблуждение Макнамары".
Это заблуждение подчеркивает одержимость измеримыми показателями, которая может привести к пренебрежению или игнорированию важнейших, но трудноизмеримых аспектов проблемы или опыта.
Рассмотрим время ожидания в здравоохранении: внимание часто сосредоточено на измеримой продолжительности ожидания, а не на менее осязаемом, но столь же важном "раздражении от ожидания".
Легче отслеживать минуты, чем эмоциональные состояния, однако последнее значительно влияет на опыт пациента.
Аналогично, в том, что называют "иллюзией Амина" (часто иллюстрируемой примером отеля, заменяющего швейцара автоматической дверью), чисто метрический подход рассматривает зарплату швейцара как затраты в сравнении с простой функцией "открывания двери".
Это игнорирует его неизмеримый, но жизненно важный вклад в узнаваемость гостей, безопасность и престиж отеля — всё это теряется во имя измеримой эффективности.
Эта предвзятость к измеримому распространяется на дизайн продуктов и услуг.
Когда проект высокоскоростной железной дороги сосредоточен на сокращении времени в пути на несколько минут — дорогостоящее инженерное достижение — он может упустить из виду более эффективное, хотя и менее "инженерное" решение, такое как обеспечение надежного Wi-Fi.
Хотя время в пути легко измерить, *качество* этого времени и то, как его воспринимают пассажиры (например, возможность продуктивно работать или развлекаться), менее измеримо, но глубоко влияет на удовлетворенность.
Даже стандартные единицы измерения в значительной степени игнорируют человеческое восприятие, за редким исключением, таким как люмен (измеряющий свет, видимый человеку).
Это сравнимо с определением книги исключительно как "предоставление информации", потому что это легко оцифровываемый и измеримый аспект, тем самым упуская ее культурную, социальную и подарочную роли, которые труднее измерить количественно.
Основная проблема возникает, когда те, кто обладает исключительно инженерным или экономическим мышлением, первыми определяют проблему.
Они, как правило, делают это в научных, измеримых терминах (время, вес, расстояние).
Затем решения ищутся в этих узких параметрах, что искажает процесс решения проблемы и с самого начала исключает психологические или основанные на опыте соображения.
Это приводит к оптимизации по метрикам, которые могут не отражать истинную ценность или удовлетворенность человека, что в конечном итоге приводит к неоптимальным результатам, потому что внимание сосредоточено на том, что легко посчитать, а не на том, что действительно имеет значение.
@
Читать полностью…
Mike Blazer
26 мая 2025 15:05
HCU (апдейт полезного контента) скорее всего был сломанным алгоритмом машинного обучения с подавлением на уровне всего сайта, который Гугл просто не может починить.
Есть множество признаков того, что он сломан, но это слишком долго рассказывать здесь сегодня.
(Почему? Они натренировали свой ML на SPAM, но не на том, как различать то, что может выглядеть как SPAM в одном контексте, но не в другом.)
Так много всего хочется сказать о том, что я читаю, включая все ложные пути, по которым повели этого несчастного владельца сайта, пишет Кристин Шачингер.
Столько всего им дали сделать, что либо: никогда не восстановило бы их сайт после любого алгоритмического обновления Гугла, показало недопонимание того, как Гугл применяет эти девальвации, либо было просто базовым SEO, которое также не имело бы никакого отношения к восстановлению сайта после девальвации Гугла такого рода.
Однако я не хочу называть людей по именам, поскольку это не моя практика, так как они могли делать то, что честно считали работающим, и чего не знаешь, того не знаешь.
Однако я скажу всем, кто все еще пытается восстановиться после обновления Google HCU: они НЕВОССТАНОВИМЫ.
Я отказываюсь от клиентов по восстановлению HCU уже более 12 месяцев.
Гугл практически признал, что это сломано безвозвратно, и я никогда не видела восстановившегося сайта.*
Любой, кто приходил ко мне с тем, что он считал HCU, и восстанавливался, на самом деле был задет Core Update, который зажал HCU как рожь горячий пастрами.
У меня даже был кто-то с проблемой HCU, но у него также было ДВА вопроса с Core Update, поэтому мы восстановили 70% их трафика, поскольку HCU составлял только 30% спада - часть HCU НИКОГДА не вернулась.
Я говорю ТОЛЬКО потому, что есть множество способов вернуть эти 30% трафика, но нет способа восстановить сайт с 90% потерей органики от HCU.
[Хотя я думаю, что знаю, в чем была проблема для этих сайтов (нет, не реклама или партнерские ссылки), я не буду их брать, потому что знаю, что HCU - мертвый алгоритм, и если он не запустится снова, вы не сможете восстановиться.]
Я думаю, что Гугл пытается создать новую версию, но это вряд ли будет запущено в ближайшем будущем, поэтому Гугл сказал приглашенным владельцам сайтов на саммите прошлой осенью отпустить свои сайты.
ПРИМЕЧАНИЕ: Вам следует получить оценку, если вы думаете, что были задеты HCU.
Я восстановила нескольких клиентов, которые на самом деле были задеты Core Update и думали, что это был HCU, но если кто-то просит деньги, чтобы "восстановить" вас от HCU СЕЙЧАС в этот момент, они берут это под ложным предлогом.
__________
* Возможно, вы сможете восстановить сайт, сделав ПЕРЕЕЗД, но что будет с сайтами, которые находились на тех доменах, на которых они были в момент атаки? Я не видела ни одного, который удалось восстановить.
@
Читать полностью…
Mike Blazer
26 мая 2025 11:05
Трехлетний путь восстановления после Google Helpful Content Update за 200 000+ долларов
1. Первоначальные широкие действия
— Проанализировали свой архив из 12 000 статей построчно
— Закрыли от индексации тонкий контент
— Удалили мертвые категории и убрали теги
— Наняли настоящих экспертов
— Перестроили редакционную структуру с нуля
2. Консультация с Лили Рей ($600 за 1 час)
Внедрили и протестировали ее рекомендации:
— Понижение/перемещение категорий (изначально не удаляли)
— Сделали категории более детализированными
— Аудит каждого URL
— Усиление внутренней перелинковки
— Добавление текста к страницам с большим количеством видео
— Раздельная подача разделов Discover в Google Publisher Center
— Удаление/изоляция NSFW контента
— Тестирование нового поддомена для Discover
— Удвоение усилий по темам, показывающим жизнь в Discover
— Оценка широты тематического покрытия
3. Чистка и переписывание контента
— Зачистили тонкий контент: Закрыли от индексации, отправили в черновики или удалили тысячи статей по метрикам количества слов (менее 200 слов)
— Убрали контент с большим количеством вставок: Удалили вставки (TikTok, YouTube, твиты) из ~1300 статей и переписали как оригинальные материалы
— Сократили новости/интервью с большим количеством цитат: Переписали или удалили статьи, сильно опирающиеся на цитаты из Reddit, пресс-релизы или заявления знаменитостей
— Убрали партнерский контент: Удалили статьи с обзорами продуктов и подборками
4. Редакционные и структурные исправления
— Исправили редакционную структуру: Вручную проверили оставшиеся статьи, чтобы добавить внутренние/внешние ссылки, обеспечить несколько изображений и включить встроенное связанное чтение
— Удалили все страницы тегов: Полностью их убрали
— Тестировали теории E-E-A-T: Привлекли предметных экспертов, создали биографии авторов, перекрестно связали профили и обеспечили высококачественный экспертный контент
— Зачистили спящие категории: Полностью удалили целые контентные вертикали (стиль, спорт, груминг), что привело к дальнейшей потере трафика
— Работа с YMYL и NSFW:
- Деиндексировали и удалили весь раздел здоровья (~2000 статей)
- Убрали весь мат и потенциально неподходящий язык
- Отредактировали статьи о фитнесе (удалили фото мужчин без рубашек)
5. Технические изменения на уровне сайта
— Изменили структуру постоянных ссылок: Перестроили всю систему, чтобы включить подкаталоги для категорий (/watches/article-name), создав тысячи редиректов
— Сократили рекламу: Резко урезали программатическую рекламу, зарабатывая только 3-5% от предыдущих доходов с рекламы
— Техническое SEO: Ежегодные инвестиции в разработку, тестирование структур постоянных ссылок, конфигураций серверов, Core Web Vitals, краулинга и скорости сайта
— Дизавуирование ссылок: Тестировали, но оказалось бесполезным
6. Стратегия публикации
— Тестировали частоту публикаций: Варьировали от 8 историй в день (3 дня/неделю) до 1 длинного оригинального материала в день
7. Другие усилия
— Анализ конкурентов: Исчерпывающее исследование конкурентов
— Google News Initiative: Никакой значимой помощи не обнаружили
Сводка затрат
— Общие затраты: 200 000+ долларов за 3 года
— Потерянный доход: Значительная потеря доходов с рекламы от сокращения объявлений
— Штат: Потеряли много штатных журналистов
Результат
Несмотря на все усилия и расходы, DMARGE не восстановил трафик.
Они "потеряли еще больше трафика и продолжают терять его сегодня."
Финальный результат: Сократились с 12 000 статей до 3 000, сосредоточившись только на часах, автомобилях и деловых путешествиях.
lucwiesman/looking-to-recover-from-the-google-helpful-content-update-or-any-algorithm-update-45c25d0d2b62" rel="nofollow">https://medium.com/@he-google-helpful-content-update-or-any-algorithm-update-45c25d0d2b62
@
Читать полностью…
Mike Blazer
25 мая 2025 14:05
Большинство AI-агентов (Manus, Operator и т. д.) используют DOM для навигации и понимания структуры страницы.
При этом не используются движения мыши или классические сигналы сенсорного экрана.
Веб-сайты электронной коммерции должны обеспечить доступ AI ко всем важным деталям продуктов, которые были раскрыты пользователем.
@
Читать полностью…
Mike Blazer
24 мая 2025 10:05
Google: Это не фактор ранжирования.
Сеошники: Это косвенный сигнал ранжирования
Пользователи: Это, вероятно, как-то полезно для нас
Министерство Юстиции: Это часть алгоритма
@
Читать полностью…
Mike Blazer
23 мая 2025 15:05
Вот как выглядит злоупотребление E-E-A-T.
Нет никаких причин для того, чтобы 3 автора ассоциировались со статьей о том, что такое валовая прибыль 😂.
@
Читать полностью…
Mike Blazer
23 мая 2025 11:05
Большинство попыток линкбилдинга проваливаются, потому что агентства юзают базы, а не реальный аутрич.
Я постоянно это вижу, когда к нам переходят e-commerce бренды, пишет Триггви.
Их прошлое агентство брало с них тысячи, закупая дешёвые ссылки из баз.
Мы же работаем совершенно иначе.
Мы покупаем новые домены, похожие на домен клиента, для настройки почты.
Мы как следует прогреваем эти аккаунты, чтобы не попадать под спам-фильтры.
Затем мы проводим аутрич от имени вашей компании, а не как очередное SEO-агентство.
Именно поэтому ручной аутрич работает там, где массовые рассылки сливаются.
Каждое письмо, ответ и полученная ссылка отслеживаются в вашем личном дашборде.
Никаких "чёрных ящиков".
Никаких ежемесячных отчётов с туманными обещаниями.
Только реальный линкбилдинг, который реально даёт результат вашему бизнесу.
@
Читать полностью…
Mike Blazer
22 мая 2025 17:05
Google теперь обрабатывает временные 302 редиректы так же, как и постоянные 301-е.
Один из наших клиентов перенес весь свой сайт (более 3000 URL) на новый домен, используя 302 редиректы вместо 301-х, — рассказывает Абдерразак.
Что в итоге?
Быстрая деиндексация URL, с которых стояли редиректы.
Всего за 10 дней около 90% их страниц были удалены из индекса Google, и трафик успешно перетек на новый домен.
Это доказывает, что старое убеждение — будто Google не выкидывает из индекса страницы при использовании 302-х редиректов — больше не актуально.
@
Читать полностью…
Mike Blazer
22 мая 2025 13:10
Я оптимизирую краулинговый бюджет Гугла через техническое SEO... и вправо, и влево, говорит Суреш.
Я убрал все ненужные запросы и теперь сделал так, что CSS будет подгружаться только когда это абсолютно необходимо для гуглобота.
CSS-запросы снизились с 1022 -> меньше 10 запросов в день.
Магия E-tag.
Размещайте их в HTTP-хидерах.
На прошлой неделе я сделал 2 миграции сайта, и оба имеют одинаковый график!
Показы и клики растут.
Такую тему стоит обсуждать на конференциях, поскольку многие этим не занималиются.
https://developer.mozilla.org/en-US/docs/Web/HTTP/Reference/Headers/ETag
@
Читать полностью…
Mike Blazer
22 мая 2025 08:15
Агрессивная скорость наращивания ссылок
Наращивание большого объема ссылок, например, более 20 ссылок в день на одну страницу или 100 гостевых постов... в один и тот же день на новый сайт, определяет агрессивную скорость наращивания ссылок.
Эта тактика, хотя и потенциально ускоряет получение результатов, несет в себе значительные риски.
Опасность: Резкое проседание в позициях
Если это не контролировать, такая высокая скорость, скорее всего, приведет к тому, что ваша страница или сайт резко просядут в позициях.
Если страница без трафика внезапно получит много [ссылок] в день, эта страница может попасть под раздачу.
Неважно, насколько качественные эти ссылки.
Фикс: Маскировка с помощью имитации виральности
Чтобы этому противодействовать, основной метод маскировки — компенсировать часть этих ссылок трафиком, чтобы это выглядело так, будто контент стал вирусным.
Это часто включает в себя:
— Использование трафика, чтобы получение ссылок выглядело естественным.
— Имитацию трафика, который выглядит так, будто он пришел из социальных сетей.
— Постепенное наращивание этого вирусного трафикового сигнала, а не просто скачок с нуля до... 100 000.
Логика?
Google нормально относится к действительно вирусному контенту, который естественным образом и быстро привлекает много ссылок.
Маскировка пытается это имитировать, показывая Google, что это естественно, хотя на самом деле это не так.
Когда высокая скорость *может быть* нормальной:
Однако скорость наращивания ссылок не всегда является красным флагом:
— Тип ссылок: Размещение 100 цитирований для локального бизнеса за один день обычно считается приемлемым.
— Распределение: Распределение 20 ссылок в день, но на 20 разных страниц ежедневно воспринимается более положительно.
— Авторитет домена: Высокоавторитетный сайт вроде Forbes может переварить много ссылок, в то время как какой-нибудь маленький семейный магазинчик может быть ограничен одной-двумя ссылками в день.
@
Читать полностью…
Mike Blazer
21 мая 2025 11:05
Манипуляция отзывами на Trustpilot
Блэкхэт-техника для манипуляции отзывами на Trustpilot предполагает использование функции импорта CSV, доступной пользователям Trustpilot.
1. Необходимое условие: Необходим доступ к Trustpilot Pro.
2. Использование функции импорта: Trustpilot Pro позволяет пользователям импортировать отзывы с других платформ (например, Google) через CSV-файл.
3. Уязвимость: Суть этого эксплойта заключается в отсутствии валидации содержимого загружаемого CSV-файла со стороны Trustpilot.
4. Метод:
— Скачайте ваши легитимные отзывы (например, из Google) в формате CSV.
— Отредактируйте этот CSV-файл, добавив строки с выдуманными, фейковыми отзывами.
— Загрузите модифицированный CSV на Trustpilot.
5. Результат: Эти фейковые отзывы могут отображаться на Trustpilot как настоящие, импортированные отзывы, потенциально даже с отметками "верифицировано" от предполагаемой исходной платформы (например, Google), несмотря на то, что они полностью сфабрикованы.
@
Читать полностью…
Mike Blazer
20 мая 2025 19:25
Рецепт успешного аутрича в Телеграме
1. Подписываешься на канал
2. Через пару минут отписываешься
3. Пишешь автору канала, что давно читаешь канал и какой он классный, и спамишь свой оффер
4. Профит
Не благодарите.
@
Читать полностью…
Mike Blazer
20 мая 2025 15:05
Копирайтинг - странная работа.
Люди рассказывают вам что-то, вы пересказываете это им меньшим количеством слов, и они вам платят.
@
Читать полностью…
Mike Blazer
27 мая 2025 11:05
Знаешь ли ты, что RankBrain - это система глубокого обучения (ИИ), которая частично обучается на основе того, на какие результаты кликают пользователи при вводе поисковых запросов?
RankBrain переранжирует топ 20-30 результатов, которые изначально выдаются традиционными алгоритмами.
Таким образом, клики не являются прямым фактором ранжирования, но выбор пользователей со временем влияет на алгоритмы ранжирования.
Именно поэтому Гугл рекомендует создавать полезный контент, ориентированный в первую очередь на людей.
Это из показаний Панду Наяка
@
Читать полностью…
Mike Blazer
26 мая 2025 17:05
Новые данные исследования 50 сайтов: трафик на главные страницы вырос на 10.7% благодаря AI Overviews и LLM!
Трафик может падать, но растет количество высокоинтентных посетителей главных страниц.
Siege Media проанализировала 28 B2B компаний и 22 B2C, чтобы оценить влияние ИИ за последние три месяца.
В результате обнаружилось снижение общего трафика, но также значительный рост трафика на главные страницы.
Если предположить, что главная страница конвертирует значительно лучше остального сайта (часто в 3 раза или больше), вполне реально, что это приводит к общему росту конверсии для компаний с долей трафика на главную страницу более 20%.
В B2B сегменте это было более выражено — рост на 15% против 8% в B2C.
Росс Хадженс считает, что это связано с тем, что потребители в сегменте B2B чаще используют новые технологии.
Так что изменения в B2C *в итоге* должны стать похожими на B2B, но это, конечно, пока неизвестно наверняка.
Как действовать на основе этих данных?
Донести информацию до руководства, которое не видит полной ценности показов на этих платформах.
Гипер-оптимизировать ваши главные страницы под кликабельность и конверсию.
И самое важное — инвестировать в бренд (контент + PR + соцсети + реклама) как метод органического роста.
https://www.siegemedia.com/strategy/ai-homepage-traffic-increase
@
Читать полностью…
Mike Blazer
26 мая 2025 13:10
Когда Google анонсировал Helpful Content Update, ИМЕННО ОНИ официально заявили, что восстановление возможно, и что сайты могут начать возвращать трафик после внесения изменений и улучшений, которые снимут классификатор, подавляющий трафик сайтов.
На самом деле, есть даже запись, где Google изначально утверждал, что восстановление возможно "в течение нескольких недель".
Конечно, эта формулировка постепенно изменилась на "несколько месяцев", а затем на еще более расплывчатые временные рамки, вплоть до настоящего момента — где Google на нескольких Creator Summits — включая один пару недель назад — заявил, что "мы все еще работаем над этим и относимся к этому серьезно; это не мгновенное решение".
Владельцы сайтов ловили каждое слово Google и ждали месяцами — инвестируя в внешнюю поддержку и кардинально перестраивая свои сайты — хоть каких-то признаков изменений, которые помогли бы им восстановиться.
Прошло почти 2 года, и очень немногие HCU-сайты увидели какое-либо значительное восстановление, несмотря на кардинальные изменения и улучшения, пишет Лили Рэй.
Это не касается сайтов, затронутых другими обновлениями алгоритма помимо HCU.
Я лично работала над десятками восстановлений на протяжении многих лет, и есть бесчисленные примеры сайтов, которые смогли вернуться в хорошие отношения с Google после попадания под апдейты или санкции.
Это не относится к HCU.
Я говорила с самого начала — кажется, что HCU-сайты "посадили в тюрьму". Я также делала все возможное, чтобы привлечь внимание к тому, насколько несправедливо это для владельцев этих сайтов, и как эти результаты прямо противоречат рекомендациям, которые Google дал нам в начале апдейта.
Моя команда и я работали над различными сайтами, затронутыми HCU, с несколькими отличными кейсами восстановления, но многие сайты не смогли увидеть существенное восстановление.
Мы предоставляли этим клиентам те же рекомендации, которые даем всем клиентам, затронутым обновлениями алгоритма — проверенные временем методы, которые работали годами.
Эти рекомендации всегда основаны на реальном улучшении сайтов и делании их лучше для пользователей.
Я также потратила десятки часов, включая выходные, предоставляя бесплатные советы затронутым владельцам сайтов просто потому, что знала, как сильно это вредит их бизнесу, и хотела помочь.
Мы бы никогда не работали с HCU-клиентами, если бы Google просто был честен с самого начала — большинство сайтов, затронутых HCU, найдут восстановление в течение 2 лет практически невозможным, несмотря на кардинальные изменения.
Опять же, это отличается от поведения других обновлений алгоритма Google.
По моему мнению, нам нужно спрашивать, почему коммуникации Google вокруг этого апдейта так сильно изменились со временем, и почему эти сайты, похоже, получили несправедливое обращение по сравнению со всеми другими обновлениями Google.
@
Читать полностью…
Mike Blazer
26 мая 2025 08:15
Психологический и поведенческий маркетинг #1
(это небольшая серия постов, на подобии поста про лифты и зеркала, о новых внедрениях, принятии решений и измерение эффективности)
"Иллюзия Амина" ярко иллюстрирует распространённую бизнес-ловушку: соблазн оптимизации ради узких, легко измеримых показателей эффективности в ущерб менее осязаемым, но жизненно важным факторам.
Рассмотрим отель, который, руководствуясь исключительно соображениями экономии, рассматривает своего швейцара просто как человека, который "открывает дверь".
Автоматическая дверь, согласно такой логике, выполняет эту функцию гораздо дешевле, что приводит к увольнению швейцара.
Однако такая "эффективность" упускает из виду истинную, многогранную ценность швейцара.
Он – приветливое лицо, узнающее постоянных клиентов, помощник с багажом и такси, символ статуса отеля, оправдывающий высокие цены, и ненавязчивый элемент безопасности.
Этот вклад, хотя его и сложнее измерить, чем зарплату, имеет решающее значение для впечатлений гостей и бренда отеля.
Последствия?
Отель, несмотря на "экономию средств", часто сталкивается со снижением лояльности гостей, престижа и общего качества обслуживания.
Вывод очевиден: слишком узкое определение ценности и оптимизация по легко измеряемым показателям могут непреднамеренно разрушить саму суть того, что делает услугу или бизнес по-настоящему ценным.
@
Читать полностью…
Mike Blazer
25 мая 2025 10:05
Google I/O 2025
@
Читать полностью…
Mike Blazer
23 мая 2025 17:05
Когда SEO-конфа превратилась в дебаты о подпапках и поддоменах
@
Читать полностью…
Mike Blazer
23 мая 2025 13:10
Когда клиент хочет перемен… но не хочет ничего менять.
@
Читать полностью…
Mike Blazer
23 мая 2025 08:15
Букмарклет ct.css от Гарри Робертса цветовым кодом отмечает степень блокировки рендеринга страниц:
javascript:(function(){ var ct = document.createElement('link'); ct.rel = 'stylesheet'; ct.href = 'https://csswizardry.com/ct/ct.css'; ct.classList.add('ct'); document.head.appendChild(ct); }());;Или вы можете скачать его отсюда:
https://csswizardry.com/ct/Откройте свою страницу, дождитесь загрузки, нажмите на букмарклет, чтобы увидеть блокирующие рендеринг скрипты и таблицы стилей.
Вот презентация Гарри Робертса о том, как привести свой
<head> в порядок:
https://speakerdeck.com/csswizardry/get-your-head-straightРич Татум
переписал букмарклет на чистом
JavaScript с несколькими новыми функциями, такими как сворачиваемые детали и экспорт отчета.
Вы можете найти его здесь:
https://richtatum.notion.site/bookmarklet-ct-scan-v2@
Читать полностью…
Mike Blazer
22 мая 2025 15:05
Ты думаешь, что учишься.
Ничего подобного.
Просмотры, чтение и прослушивание ощущаются как прогресс.
Но это не так.
Настоящее обучение происходит, когда ты борешься с идеями, применяешь их и преодолеваешь трудности.
Если кажется легко, ты просто собираешь информацию.
Большинство начинающих основателей и стартап-команд тратят годы в погоне за знаниями вместо мастерства.
Они верят, что больше чтения, больше прослушивания и больше заметок помогут им во всем разобраться.
Но узкое место не в знаниях.
А в реализации.
Тебе не нужно больше советов.
Тебе нужно применять то, что ты уже знаешь.
Если ты не можешь объяснить что-то просто, значит ты этого не понимаешь.
Если урок обещает научить тебя всему за десять минут, его не стоит изучать.
Книги и подкасты тебя не спасут.
Клиенты расскажут тебе всё, что нужно знать.
Основатели, которые быстро учатся, не выглядят умнее.
Они выглядят так, будто совершают ошибки публично, итерируют и быстро исправляют проблемы.
Потому что так оно и есть.
Твой самый большой риск – не провал.
А потратить годы, чувствуя себя продуктивным, вместо того чтобы реально становиться лучше.
Основатели, которые двигаются быстрее всех – те, кто возвращается к основам.
Говори с клиентами вместо того, чтобы говорить о клиентах.
Записывай то, что узнаёшь, вместо того чтобы полагаться на память.
Хорошо решай одну болезненную проблему, прежде чем гнаться за новыми идеями.
Принимай решения сегодня, а не откладывай их на завтра.
Начни сейчас, потому что ожидание никого не сделало великим.
@
Читать полностью…
Mike Blazer
22 мая 2025 11:05
Ваш якорный текст может тормозить ваш выход в топ Гугла.
Стратегия Оптимизации Якорного Текста:
1. Разбираемся в типах анкоров
Для сбалансированного ссылочного профиля нужен микс разных типов анкоров:
— Целевые анкоры: Содержат любое слово из вашего ключа.
— Брендовые анкоры: Название вашего бизнеса/сайта.
— URL-анкоры: Сам URL (голый URL).
— Тематические анкоры: Более широкая тема вашей страницы.
— Прочие анкоры (безанкорка): "Кликни здесь", "этот сайт" и т.д.
Целевые анкоры дают наибольший буст, но перебор с ними грозит санкциями.
2. Избегайте ловушки с распределением
Избегайте шаблонных пропорций анкоров (например, 20% точных вхождений, 30% брендовых).
За такое ваш сайт может отхватить фильтр.
В каждой нише свои естественные паттерны анкоров.
Чтобы найти свое идеальное соотношение:
1. Проанализируйте анкоры топ-5 конкурентов с помощью Ahrefs.
2. Выгрузите и разбейте по категориям каждый анкор.
3. Сделайте сводную таблицу, показывающую распределение по типам.
4. Усредните распределение по всем конкурентам.
5. Это и будет ваше безопасное целевое распределение.
3. Никогда не частите с целевыми анкорами
Никогда не используйте один и тот же целевой анкор дважды.
Если ваш ключ "best protein powder", варианты должны включать:
— top protein powders
— high-quality protein supplement
— protein powder reviews
— recommended protein products
4. Лайфхак с SEO-тайтлом
Ваш SEO-тайтл естественным образом используется как якорный текст по всему вебу.
— Убедитесь, что ваш SEO-тайтл содержит целевой ключ.
— Это помогает получать целевые анкоры естественно, не выглядя как манипуляция.
— Когда вы выжали максимум из прямых целевых анкоров, делайте упор на анкоры из SEO-тайтлов.
5. Соотносите анкоры с источниками ссылок
Разные типы ссылок естественным образом используют разные паттерны анкоров:
— Статьи в блогах → Целевые/описательные анкоры.
— Списки ресурсов → Брендовые или URL-анкоры.
— Сайдбары → Тематические или пустые анкоры.
— Форумы → URL или SEO-тайтл.
— Комментарии → Имя автора.
Имитация этих паттернов делает ваш ссылочный профиль естественным для Гугла.
6. Разнообразьте URL-анкоры
Варьируйте форматы ваших URL-анкоров.
Миксуйте с такими вариантами:
— https://www.yoursite.com
— https://www.yoursite.com/
— https://yoursite.com
— www.yoursite.com
— yoursite.com
Эта мелкая деталь делает ваш профиль гораздо более естественным.
7. Используйте синонимы
Когда вы исчерпали лимит целевых анкоров, используйте синонимы:
Если целитесь в "best car insurance", можете смело использовать:
— top automobile coverage
— great vehicle protection
— quality auto insurance
Гугл понимает, что они связаны, и вы получите релевантность без риска санкций.
8. Окружайте ключевые слова нецелевыми анкорами
Гугл ассоциирует окружающий текст (околоссылочное) с вашей ссылкой, даже если сам анкор общий (безанкорный).
Распространенная ошибка сеошников: зацикливаться на количестве бэклинков, игнорируя качество якорного текста.
Грамотная оптимизация анкоров позволяет обходить конкурентов, имея вдвое меньше ссылок.
Дополнительные факторы для анкорной стратегии:
— Размещение
— Заметность
— Стиль (оформление)
— Вариации в единственном/множественном числе
— Варианты написания (например, британский/американский английский)
— Стратегические опечатки (использовать дозированно, позже исправлять)
— Взаимная релевантность (страница-донор/раздел к странице-акцептору/разделу)
— Картинки + атрибут Alt как текст ссылки
— Обработка Google нескольких ссылок на один и тот же адрес
— Несколько ссылок из одного источника могут снизить вес
— Оптимизированные, релевантные URL, используемые как анкор
— Разнообразьте анкоры ТОЛЬКО при наличии правильной каноникализации (редиректы, каноникал тег/HTTP-хидер, карта сайта), иначе рискуете навредить сайту.
@
Читать полностью…
Mike Blazer
21 мая 2025 17:05
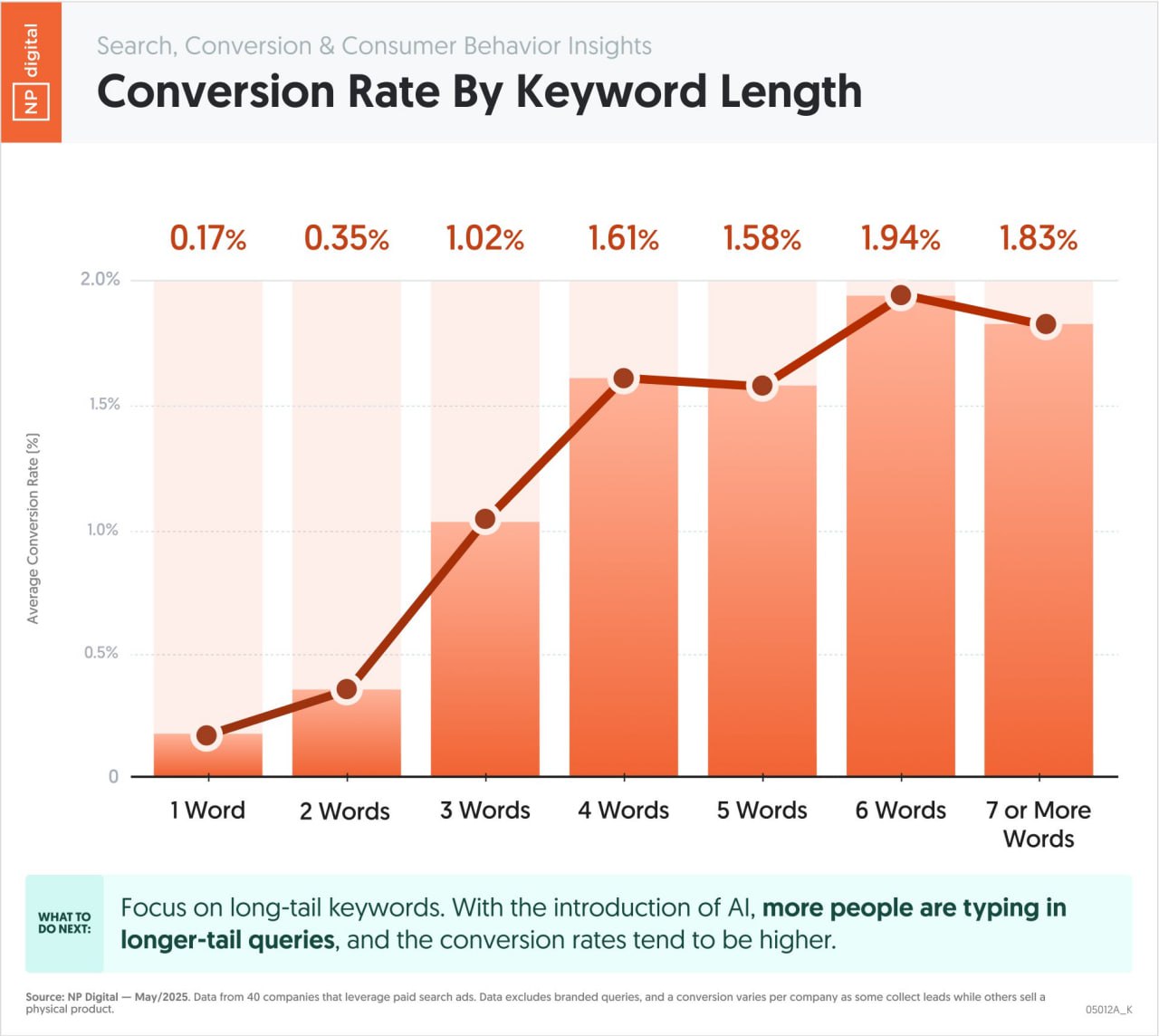
Длиннохвостые запросы могут не приносить столько трафика, как высокочастотные, но они действительно дают конверсии.
Посмотрите на средний коэффициент конверсии по длине ключевых слов.
Эти данные получены от 40 компаний, которые запускают поисковую рекламу.
@
Читать полностью…
Mike Blazer
21 мая 2025 13:10
Чтобы получать 1к кликов в день, вот что я на самом деле сделал, — говорит Басит:
— Я собрал сущности, а затем добавил их в свой контент.
— Опубликовал 25 статей 8 месяцев назад.
— Добавил свои ключевики в свою ручную разметку Schema (я могу разметить каждое слово 😉, в основном я использую ручную разметку Schema, а не сгенерированную плагинами).
— Мета тайтлы я делал только на основе ключевых слов, никаких других слов там не было.
Потом я забросил этот домен, ссылок не ставил.
Этот домен переживал взлеты и падения во время апдейтов...
Теперь я вернулся к этому сайту, обновил весь контент и разместил "Дату последнего обновления" прямо под H1.
И в течение 3 дней трафик пошел вверх, ранжирование улучшилось.
Все статьи моего блога ранжируются в топ-10.
Еще одна вещь, которую я сделал:
я обратился к ChatGPT и сделал инструмент, который мгновенно ищет слово по всей статье, чтобы читатель мог легко перейти к тому, что ему нужно, вроде якорных ссылок.
Потому что я хотел создать эффект инструмента, так как сайты-инструменты сейчас хорошо ранжируются.
Так какие выводы можно сделать?:
— Обновление контента очень важно, таким образом молодые сайты могут улучшить ранжирование.
— Создание инструментов, специфичных для вашей ниши, также полезно для взаимодействия с пользователем.
— Google также хочет видеть новые изображения в вашей нише, поэтому новые сайты могут ранжироваться в разделе картинок (мой сайт основан на изображениях и тексте).
— Старайтесь выбирать темы строго под пользователя, чтобы никакие AI-обзоры не занимали ваше место в SERP.
@
Читать полностью…
Mike Blazer
21 мая 2025 08:15
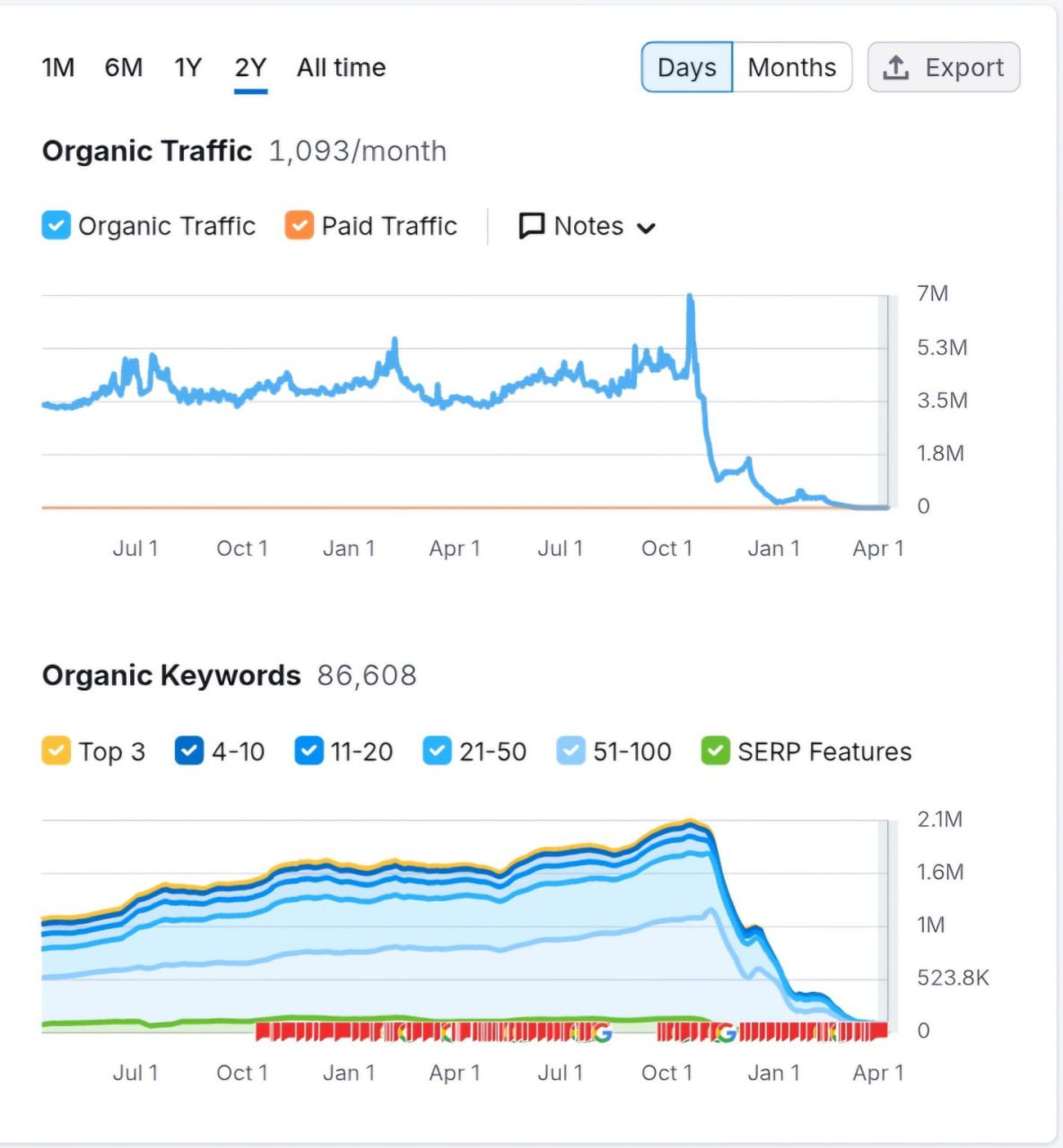
Вы, ребята, походу, не догоняете, в какой заднице сейчас паблишеры.
График из Semrush ниже показывает состояние Techopedia.
За последние несколько месяцев они потеряли 99% своего трафика.
Просто вдумайтесь в это на секунду.
Я тут быстренько поресёрчил и почитал комменты о том, что сайт, возможно, баловался схемами паразитного SEO, но я сейчас не об этом, пишет Джон.
Общая картина пугает, потому что им пришлось уволить десятки авторов и редакторов, лишив людей средств к существованию.
И это не единичный случай, если что.
Это повсюду, и страдают мелкие независимые издатели.
Вспомните Retrododo (падение на 90%), Travel Lemming (минус 94%).
Если вы знаете этих ребят, то в курсе, что они пишут РЕАЛЬНО хороший контент, но их все равно карает HCU.
Я потратил месяцы в 2023 году, изучая апдейт HCU, каждый день зависая на Reddit и форумах, наблюдая, как люди пытаются сделать хоть что-то, чтобы восстановиться.
Я делал заметки, следил за кейсами, отслеживал изменения.
Я так этим всем проникся, что на какое-то время даже разочаровался в SEO.
Вся эта история, честно говоря, угнетала.
Но знаете, что я понял за все это время?
1. Никто толком не шарит, что происходит.
Все только строят догадки и, в лучшем случае, выдвигают более-менее обоснованные предположения.
2. Ко всей этой теме "пиши хороший контент и будешь ранжироваться" я отношусь с огромной долей скепсиса.
Я видел слишком много сайтов, которые штампуют исключительный контент, но все равно продолжают сливать трафик.
Всё намного сложнее.
3. Историй восстановления не так уж много (по крайней мере, когда я последний раз проверял).
Помню одного паблишера, которого накрыло: они переехали на новый домен, снова выросли, только чтобы через месяц-другой их прихлопнуло тем же классификатором.
Всё это восстановление похоже на какую-то лотерею.
4. Поиск сломан.
Google говорит, что им не все равно, но на самом деле это не так.
Недавно читал анализ Кевина Индига, и там все по делу.
Количество zero-click запросов подскочило с 72% до 76% с момента выкатки AI Overviews.
Но поисковые сессии без AI Overviews генерируют ВДВОЕ больше просмотров страниц, чем те, где они есть.
Давайте начистоту, что это значит: Google удерживает пользователей на своих площадках, не отправляя их на сайты, которые изначально и создали этот контент.
Тем временем Google заявляет, что они "растят трафик для экосистемы", что… ну, данные показывают совсем другое.
Вообще.
Вот почему я, как паблишер, научился не слишком полагаться на поисковый трафик.
Сейчас всё решает бренд.
Я диверсифицирую трафик, создаю вечнозеленый контент, наращиваю релевантность в соцсетях.
Это включает создание комьюнити, рассылки, мембершип-модели, инфлюенс-маркетинг, платную рекламу, email-листы.
Всё, что не зависит от показов рекламы из поискового трафика.
Если и есть что-то, что стоит вынести из моего этого спича, так это вот что:
Стройте то, что переживет будущие апдейты.
Потому что БУДЕТ еще один апдейт, и еще один за ним, и еще больше фич, чтобы упростить пользовательский поиск.
Но если вы зацементировали свой бренд в головах людей, у вас хотя бы есть шанс побороться.
@
Читать полностью…
Mike Blazer
20 мая 2025 17:05
Как попасть в выдачу ChatGPT?
ChatGPT использует 3 основных юзер-агента:
— ChatGPT-User
— OAI-SearchBot
— GPTBot
ChatGPT-User — это бот, работающий в реальном времени и действующий немедленно на основе промптов.
Ни один из 3 ботов OpenAI не умеет рендерить JavaScript.
Ваш основной контент должен находиться в HTML.
Основные шаги для ранжирования в поиске ChatGPT:
1. Быть проиндексированным в Bing.
2. Быть доступным для ботов OpenAI.
Поисковые запросы в ChatGPT — это в основном хвостовые запросы.
Bing поддерживает IndexNow.
Если ваш сайт на Shopify, Wordpress или Wix, проверьте доступные плагины IndexNow.
ChatGPT иногда использует несколько документов с одного и того же домена.
Иногда ChatGPT "галлюцинирует" `URL`ы.
Если `ChatGPT` продолжает посещать или "галлюцинировать" один и тот же URL, рассмотрите возможность его создания или настройки редиректа.
В настоящее время ChatGPT не краулит файлы llms.txt.
Это логично, поскольку llms.txt более актуален для агентных сценариев использования (agentic use cases).
Если вы укажете ваши XML-сайтмапы в robots.txt, ChatGPT будет их краулить.
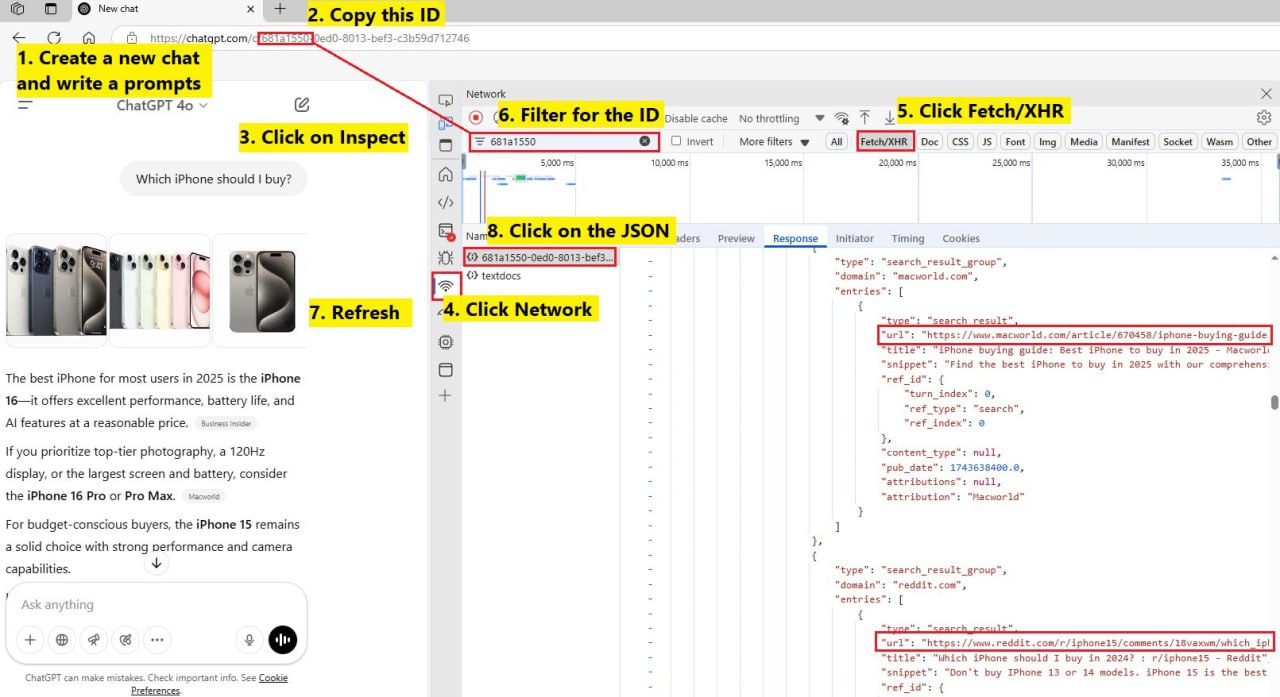
А вы знали, что из поиска ChatGPT можно получить JSON с полными списками результатов?
С помощью Inspect > Network > Fetch/XHR вы можете получить доступ к JSON-файлу со всей информацией, которая пошла на генерацию результата.
Для доступа к файлу необходимо быть залогиненным.
В JSON есть разные типы URL:
— search_results: все URL
— sources_footnotes: основные цитаты
— supporting_websites (поддерживающие веб-сайты)
— safe_urls (безопасные URL)
— blocked_urls: URL, к которым ChatGPT не может получить доступ или не хочет показывать пользователю по соображениям безопасности
Можно использовать инструменты вроде Peec AI для отслеживания нескольких сотен промптов.
Затем посмотрите список самых важных источников по всем этим промптам.
Многие из самых важных источников окажутся сайтами, которые ваши традиционные PR-усилия обошли бы стороной.
Вы можете спросить у ChatGPT, какие атрибуты он учитывает при вынесении рекомендации.
Используйте это для создания действительно холистического контента!
Многие предполагают, что структурированные данные помогают ранжироваться в ChatGPT.
Но пока никто не предоставил данных, подтверждающих это.
@
Читать полностью…
Mike Blazer
20 мая 2025 13:10
Меняющаяся экономика веб-контента: парсинг против трафика
По словам главы Cloudflare, соотношение между парсингом контента и объемом привлекаемого ими трафика радикально изменилось, что ставит под угрозу традиционную бизнес-модель веба.
Соотношение объема парсинга к числу привлеченных посетителей:
— Google (10 лет назад): 2 спаршенные страницы : 1 привлеченный посетитель
— Google (сегодня): 6 спаршенных страниц : 1 привлеченный посетитель
— OpenAI: 250 спаршенных страниц : 1 посетитель
— Anthropic: 6000 спаршенных страниц : 1 посетитель
Что изменилось?
Google по-прежнему краулит с той же скоростью, что и раньше, но теперь ответы на 75% поисковых запросов даются прямо в СЕРПе Google, и пользователям не нужно переходить на первоисточник.
Эта тенденция резко усиливается в случае с ИИ-компаниями, такими как OpenAI и Anthropic.
Последствия
Этот сдвиг угрожает жизнеспособности создания контента в онлайне.
Когда создатели оригинального контента получают значительно меньше трафика, в то время как их материалы продолжают использоваться, экономические стимулы для создания качественного контента ослабевают.
Как заявляет глава компании: "Если создатели контента не могут извлекать выгоду из того, что они делают, они перестанут создавать оригинальный контент".
Веб-экосистеме нужна новая бизнес-модель, чтобы устранить этот дисбаланс между созданием контента и его доставкой с помощью ИИ.
https://www.cfr.org/event/bernard-l-schwartz-annual-lecture-matthew-prince-cloudflare
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}