Mike Blazer
24 июня 2025 15:05
Для полноценной и прибыльной карьеры SEO-специалистам необходимы 5 основных компетенций.
Каждый навык имеет решающее значение.
Вы не можете быть сильны только в четырех.
Вы должны быть сильны во всех из них.
Развивая все пять, вы станете ценным активом для любой организации.
Вот их распределение:
1️⃣ Коммуникация: Овладение навыками внутреннего согласования, межфункционального сотрудничества и внешнего общения для создания влияния и привлечения лучших талантов.
2️⃣ Обучение: Адаптивность, умение эффективно фильтровать информацию и быть в курсе отраслевых тенденций.
3️⃣ Бизнес-чуйка: Согласование SEO с бизнес-целями, стратегическое планирование и демонстрация окупаемости инвестиций путем целенаправленного выполнения.
4️⃣ Техничность: Использование автоматизации, анализа данных и глубокого технического понимания для достижения эффективных результатов, основанных на данных.
5️⃣ Лидерство: Пропаганда SEO, создание высокоэффективных команд и налаживание прочных отношений в организации.
Эти компетенции взаимосвязаны.
Сильная коммуникация способствует эффективному лидерству, а деловая хватка - стратегическому планированию.
Как вы оцениваете эти поднавыки?
@
Читать полностью…
Mike Blazer
24 июня 2025 11:05
✓ 23-пунктный чек-лист для оптимизации контента с помощью GenAI
Вот базовый чек-лист, который поможет оптимизировать контент для поиска фрагментов с помощью ИИ и того, как такие системы, как ChatGPT, Claude и Perplexity, находят, разбивают на фрагменты, цитируют и упоминают ваш контент.
Обратите внимание, что все это направлено на снижение когнитивной нагрузки и трения между людьми и машинами.
✓ Разбиение на фрагменты — каждый абзац фокусируется на одной основной идее
✓ Избегайте неопределенных формулировок — удалите "может быть", "возможно", "по-видимому"
✓ Оптимизируйте плотность абзацев — разбивайте плотные блоки, делайте абзацы легкими для восприятия
✓ Маркированные списки и числовые списки — используйте структурированное форматирование, если это улучшает ясность
✓ Избегайте избыточности — поддерживайте ключевые термины с помощью синонимов и терминов LSI для векторизации
✓ Ясность сущностей — замените неопределенности и жаргон на четкие понятия
✓ Несоответствие модификатора и намерения — соотносите технические детали с намерением и точками карты путешествия
✓ Сигналы когнитивной нагрузки — структурируйте контент для уменьшения трения при чтении и поиске
✓ Семантический дрейф — удалите отклонения от темы, которые снижают чистоту фрагментов
✓ Уверенность в поиске — используйте четкие атрибуции, избегайте формулировок типа "Говорят, что...".
✓ Ошибки в согласованности встраивания — не смешивайте инструкции и мнения в одном абзаце.
✓ Последовательность и иерархия заголовков — используйте правильную структуру H1/H2/H3 и проверяйте последовательность и релевантность информации.
✓ Длина абзацев — старайтесь, чтобы абзацы естественным образом не превышали +/- 100 слов
✓ Отсутствие структурированных форматов — используйте таблицы для сравнений, списки для процессов
✓ Избыточное использование ключевых слов или повторения — избегайте чрезмерных повторений, используйте естественный язык
✓ Отсутствие синонимов и вариантов использования — используйте несколько способов выражения ключевых концепций
✓ Пропуск именованных сущностей — указывайте бренды, инструменты, версии с учетом контекста
✓ Согласование контента с макро- и микро-намерениями
✓ Нарушение ясности (переизбыток умных выражений) — заменяйте метафоры буквальным языком
✓ Устранение неоднозначности — добавьте контекст для неоднозначных терминов
✓ Оптимизация плотности токенов — цель: 75–400 токенов на фрагмент
✓ Соответствие заголовков шаблонам запросов — пишите заголовки, отражающие естественные поисковые запросы
✓ Сделайте абзацы тематически самодостаточными
@
Читать полностью…
Mike Blazer
23 июня 2025 17:05
При оптимизации под AI-поиск избегайте тем, которые относятся к общеизвестным или устоявшимся сведениям.
Утечка данных из Claude AI показала, что существует команда never_search для информации, не теряющей актуальности, фундаментальных концепций или общеизвестных фактов.
В частности, Claude не будет выполнять поиск в вебе и ссылаться на источники по фактам, которые "не теряют актуальности со временем или являются стабильными".
Можно предположить, что и другие LLM следуют аналогичной команде.
Это не означает, что вся верхняя часть воронки бесполезна.
Однако контент, написанный под копирку, без свежего взгляда и с пережевыванием одних и тех же идей, вознаграждаться не будет.
Это тревожный звоночек для ленивого контент-маркетинга.
Добро пожаловать в эпоху ИИ, где ценность публикации страниц с общеизвестными знаниями равна нулю.
@
Читать полностью…
Mike Blazer
23 июня 2025 13:10
В ближайшие 3 года ИИ убьет "информационный контент" как маркетинговую стратегию.
🪦 ...и, честно говоря, я этому чертовски рад, — пишет Тим Соуло.
Потому что что такое типичная стратегия работы с "информационным контентом"?
1. Взять популярный ключ.
2. Посмотреть, кто по нему сидит в топ-10.
3. Заплатить рандомному копирайтеру, чтобы он написал "более глубокую" статью.
4. Купить ссылок, чтобы впарить Гуглу, что твоя страница лучше других.
🤮
^ тысячи сайтов заваливали интернет практически одинаковым контентом на одни и те же темы.
В этой гонке за доминирование в выдаче Google со своей (шаблонной) страницей не создавалось абсолютно никакой новой информации.
И тогда в Google подумали:
"Раз все эти сайты, по сути, воруют контент друг у друга и переписывают его, не добавляя ничего оригинального, — почему бы нам просто не считать эту информацию ОБЩЕИЗВЕСТНОЙ и не выдавать мгновенный ответ с помощью ИИ, не ссылаясь ни на кого?"
Гениально!
Теперь нет никакого смысла создавать 389-е по счету "Полное руководство по _____".
Потому что, скорее всего, вам нечего добавить к "общеизвестным фактам" на эту тему.
Мы вступаем в эру ОРИГИНАЛЬНОГО КОНТЕНТА!
Нечего сказать нового — не жмите "Опубликовать". 🤷
...
Вот две очень важные концепции, которые помогут вам ориентироваться в этом новом мире, где доминирует ИИ:
1. "Спрос создал не Google. Спрос создал кто-то другой". © Рэнд Фишкин
Если не хотите стать невостребованным маркетологом в ближайшие несколько лет — вам придется научиться создавать спрос, а не просто его удовлетворять.
2. 45.7% всех запросов в Google — брендовые!
(согласно исследованию Ahrefs)
Создание бренда (т.е. формирование аудитории, которая вас знает, следит за вами и доверяет вам) становится критически важным на перспективу.
Потому что, когда у вас есть сильный бренд и большая аудитория, — создавать спрос (и удовлетворять его) становится намного проще.
…
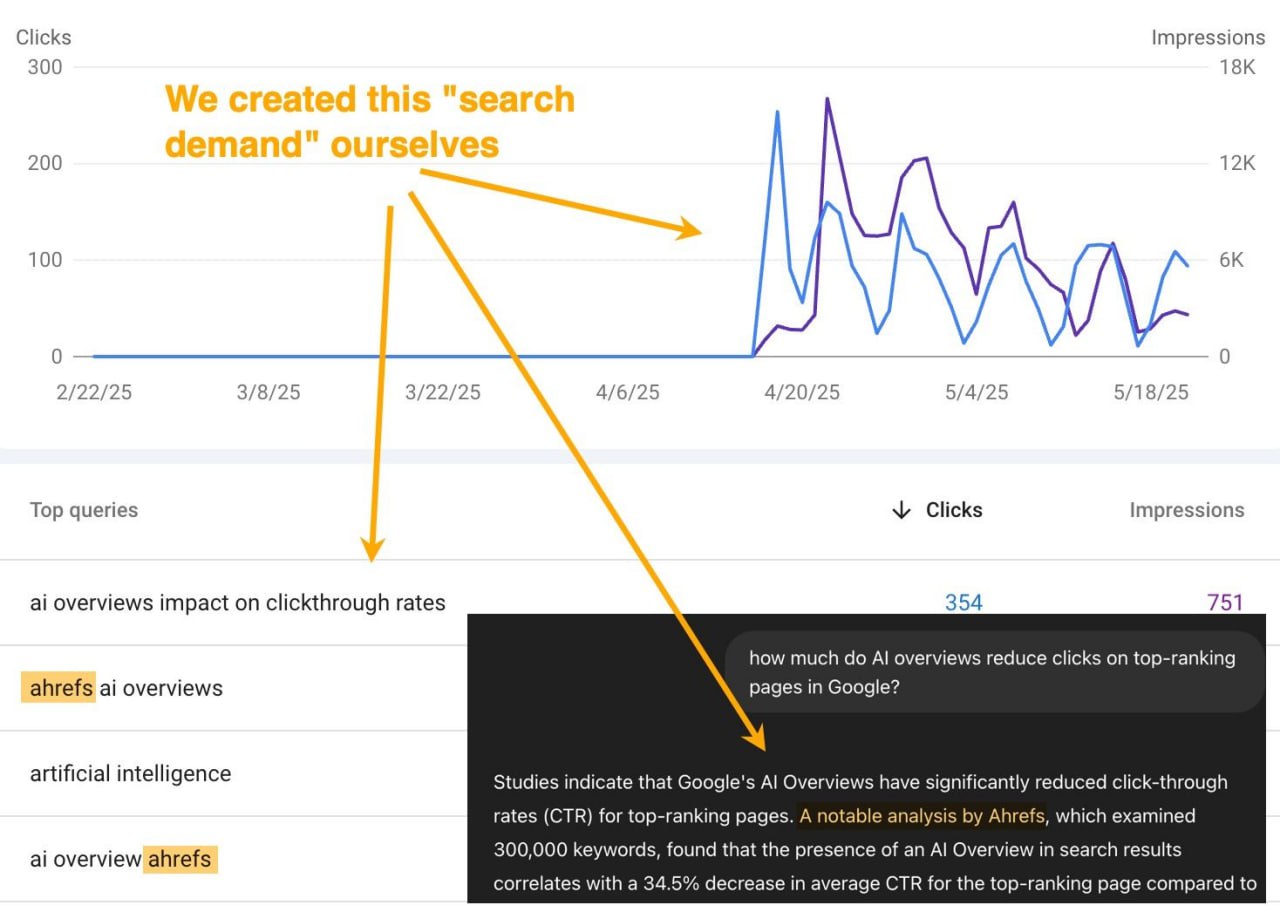
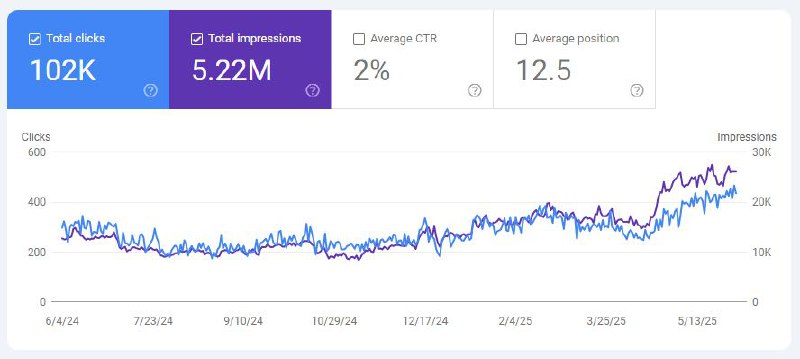
Наглядный пример:
Прикрепляю скриншот поискового трафика, который мы получили в блог Ahrefs после публикации и продвижения (!!!) исследования о том, как AI Overviews снижают количество кликов.
@
Читать полностью…
Mike Blazer
23 июня 2025 08:15
Вот как можно извлечь поисковые промты Gemini
🔍 Проанализировав поисковое поведение ChatGPT, я заинтересовался Gemini, — говорит Дэвид.
Можно ли обнаружить похожие паттерны?
Ответ: да!
Я ввел тот же поисковый запрос — "Latest news" — поскольку он обычно запускает поиск в вебе.
Затем я открыл DevTools → Network и нашел запрос, который готовит ответ Gemini, — включая все URL-источники, которые он рассматривал.
💡Самое интересное (что я чуть не упустил):
В конце есть раздел с меткой "Google Search".
Там можно увидеть реальные поисковые промты, сгенерированные Gemini, например:
➡️ What are today's top news stories in Germany?
➡️ Latest news Germany?
➡️ Any good news in the world?
➡️ Is Good News free?
➡️ Why no new news on Google?
Чуть ниже есть даже инструкция искать на территории Германии.
🎯 Это дает нам прямое представление о внутренней логике поиска Gemini.
🧠 Кто первым создаст букмарклет, который будет автоматически все это извлекать?
@
Читать полностью…
Mike Blazer
22 июня 2025 13:05
МОЩНЫЕ апдейты в графе знаний сразу после запуска AI-режима
Совпадение?
Последняя встряска 11 июня была серьезной... а потом Гугл взял и снес 6% сущностей за 2 дня
БОЛЬШАЯ чистка
Я ставлю на дубликаты, говорит Джейсон Барнард.
А какие у вас ставки?
@
Читать полностью…
Mike Blazer
20 июня 2025 15:05
Хед оф SEO понимает, что оптимизация под ИИ-ответы — это то же самое, что и оптимизация под поисковики.
@
Читать полностью…
Mike Blazer
20 июня 2025 11:05
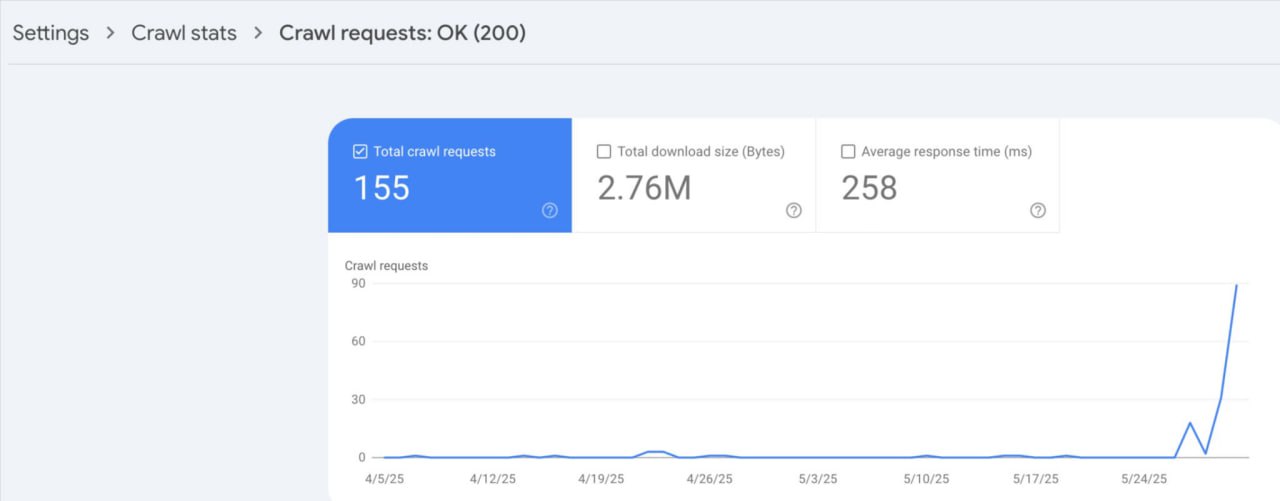
Гуглу понадобилось 14 дней, чтобы начать краулинг и индексацию нового сайта, на всех страницах которого изначально стояли теги noindex.
Во время разработки домен был доступен для пользователей, но полностью заблокирован для краулеров — везде стояли теги noindex и nofollow, а в robots.txt был запрет на обход всего сайта.
🔧 Сайт запустили 16 мая, но Гугл начал краулинг и индексацию только 30 мая.
👉 Главный вывод:
Если вы запускаете сайт с тегами noindex, будьте готовы к задержкам с индексацией даже после их удаления.
Поисковые боты не всегда сразу возвращаются.
💡 Урок усвоен:
Избегайте использования noindex на всех страницах на этапе разработки, если домен общедоступен.
А если без этого никак, перепроверьте всё дважды перед запуском.
Если вы столкнулись с такой же проблемой, вот несколько крутых советов, которые я получила от опытных специалистов по техническому SEO, — говорит Оксана:
1️⃣ Убедитесь, что ничто не блокирует индексацию и краулинг (проверьте и отправьте sitemap.xml, проверьте канонические теги, robots.txt и т. д.).
2️⃣ Используйте Google Indexing API, чтобы протолкнуть страницы в индекс.
3️⃣ Попробуйте Bing Webmaster Tools и проверьте, обходит ли он сайт.
4️⃣ Используйте инструмент проверки URL в GSC и изучите HTML-код, чтобы убедиться, что Гуглобот может отрендерить все необходимые ссылки и элементы страницы.
5️⃣ Добавьте качественные бэклинки, чтобы ускорить процесс обнаружения сайта.
6️⃣ Если вы все проверили — наберитесь терпения и ждите 😇
@
Читать полностью…
Mike Blazer
19 июня 2025 17:05
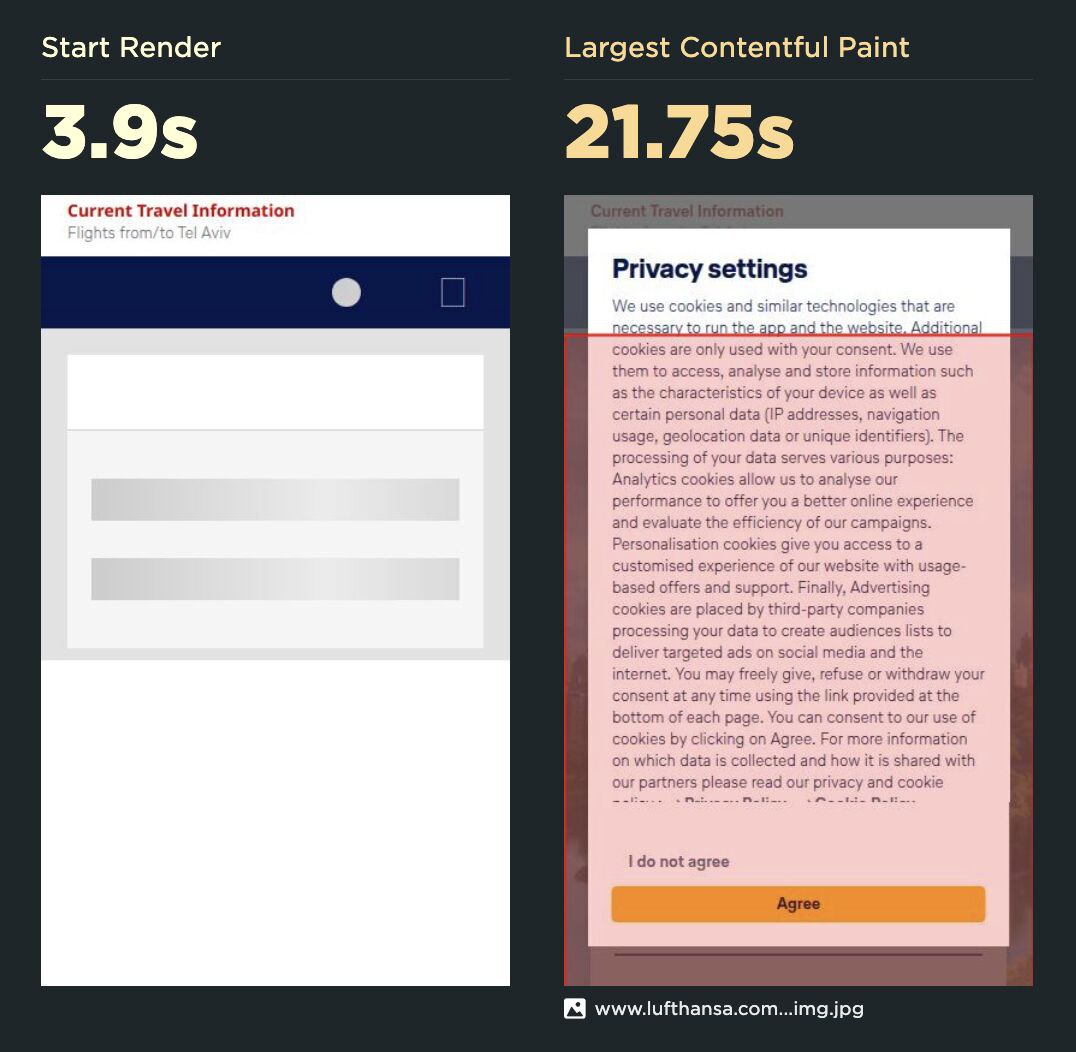
Удивительно, но многие даже не догадываются, что cookie-баннеры на их страницах могут серьезно вредить UX и SEO.
Все потому, что эти баннеры замедляют LCP на многих страницах, особенно на мобильных устройствах.
Что в итоге?
Ваши посетители получают медленный сайт, что для них паршиво.
А поскольку LCP — это фактор ранжирования Google (незаметно крошечный), для вас это тоже паршиво.
Клифф Крокер объясняет самые распространенные проблемы (и их решения) при измерении PageSpeed с использованием менеджеров согласия: https://www.speedcurve.com/blog/web-performance-cookie-consent/
@
Читать полностью…
Mike Blazer
19 июня 2025 13:10
GSC не учитывает около 50% поисковых запросов, помечая их как "анонимные запросы".
По половине трафика из Google нет никаких данных о поисковых запросах, что особенно критично с ростом популярности разговорных запросов.
Томек Рудзки провел эксперимент для проверки отслеживания разговорных запросов в GSC.
Он многократно вводил один и тот же конкретный вопрос о своем сайте с разных устройств и аккаунтов.
Результаты показали, что GSC не зафиксировал трафика по этому запросу.
Для подтверждения гипотезы 10 других SEO-специалистов протестировали уникальные запросы и также не обнаружили по ним данных в GSC.
Это указывает на то, что GSC не приспособлен для отслеживания разговорных запросов.
Похоже, GSC начинает отслеживать запросы только после того, как они достигают определенного порога популярности.
Низкочастотные запросы в отчетах просто не появляются.
Более того, эксперимент коллеги показал, что даже когда запрос начинает набирать популярность, GSC отображает данные только с этого момента, игнорируя всю предыдущую историю.
Это слепое пятно мешает отслеживать зарождающиеся тренды.
Разговорные запросы усугубляют эту проблему.
Пользователь может искать информацию о последнем iPhone, используя самые разные формулировки:
— "What are the pros and cons of the iPhone 16?"
— "Compare iPhone 16 with Samsung S25."
— "Which is better, iPhone 16 or Galaxy S25?"
Каждый такой запрос может иметь частотность 10-15 поисков в месяц, но в совокупности они дают сотни.
GSC упускает из виду эти низкочастотные, длиннохвостые вариации, несмотря на их общую значимость.
По мере развития поиска эта проблема будет только усугубляться.
Голосовым поиском пользуются 20% людей во всем мире, а ИИ-инструменты, такие как ChatGPT, поощряют использование детализированных, разговорных запросов.
Подход Google кажется непоследовательным.
Поисковик отвечает на эти запросы — анализ 140 тысяч вопросов из блока People Also Asked показал, что для 80% из них генерируются ИИ-ответы.
При этом GSC, ключевой инструмент для SEO-специалистов, не предоставляет по ним никаких данных.
Этот пробел в данных приводит к неполному пониманию пользователей, упущенным возможностям для оптимизации под разговорные запросы, искажению показателей эффективности и невозможности отслеживать тренды.
https://ziptie.dev/blog/gscs-huge-search-gap/
@
Читать полностью…
Mike Blazer
19 июня 2025 08:15
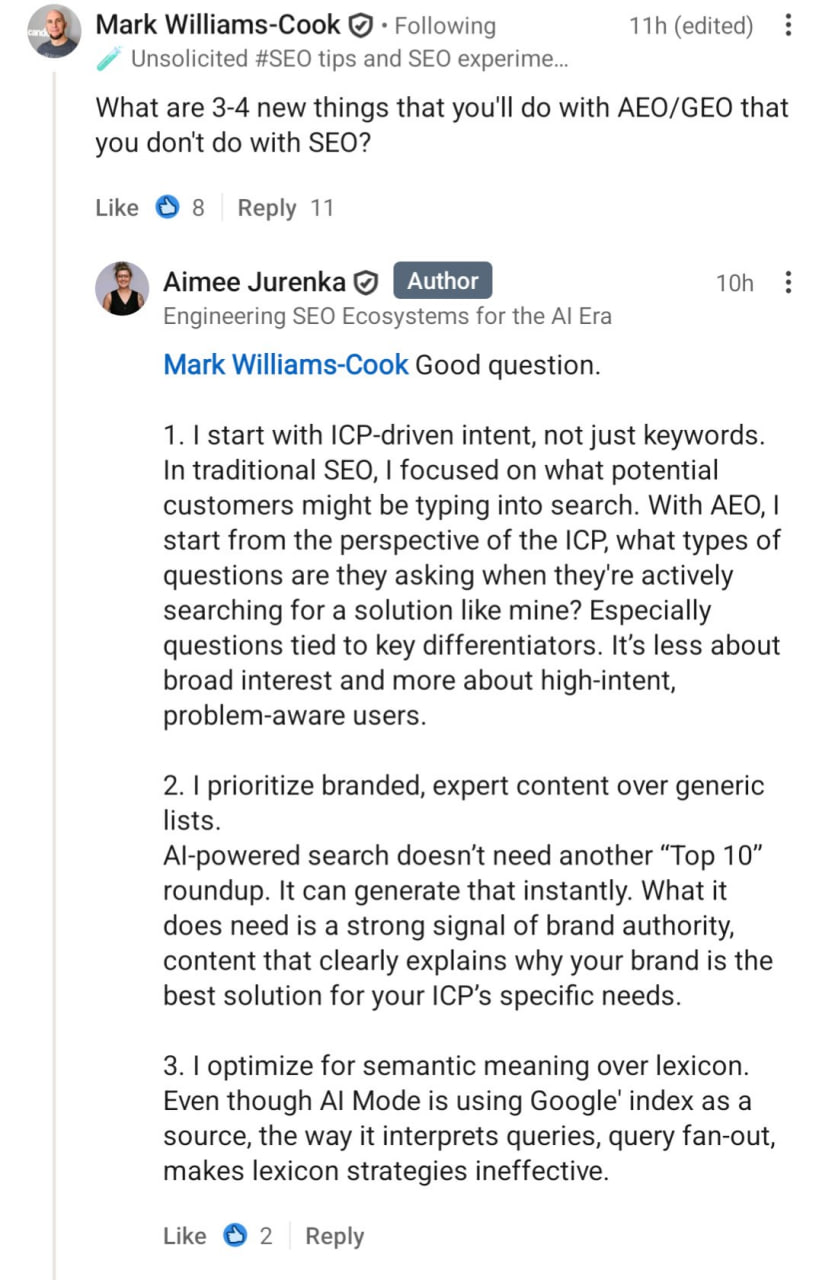
Вопрос: Какие 3 новые вещи вы будете делать с AEO/GEO, чего не делаете в SEO?
Ответ:
1. Я начинаю с интента, продиктованного ICP, а не просто с ключевиков, — пишет Эйми Юренка.
В традиционном SEO я концентрировалась на том, что потенциальные клиенты могут вбивать в поиск.
С AEO я начинаю с позиции ICP: какие вопросы они задают, когда активно ищут такое решение, как мое?
Особенно вопросы, связанные с ключевыми отличиями.
Речь идет не столько о широком интересе, сколько о пользователях с высоким интентом, которые уже осознают свою проблему.
2. Я отдаю приоритет брендированному, экспертному контенту, а не шаблонным подборкам.
Поиску на базе ИИ не нужна еще одна подборка в стиле "Топ-10".
Он может сгенерировать ее мгновенно.
Что ему действительно нужно, так это сильный сигнал авторитета бренда — контент, который четко объясняет, почему именно ваш бренд является лучшим решением для конкретных потребностей вашего ICP.
3. Я оптимизирую под семантическое значение, а не под лексику.
Хотя AI Mode использует индекс Google в качестве источника, то, как он интерпретирует запросы, — этот самый query fan-out — делает лексические стратегии неэффективными.
@
Читать полностью…
Mike Blazer
18 июня 2025 15:05
Забавная ✨агентская фишка✨ - когда они складывают опыт всех членов команды, и получается, что трёхлетнее SEO-агентство пишет на своём сайте что-то типа "150 лет SEO-опыта".
Супер.
@
Читать полностью…
Mike Blazer
18 июня 2025 13:10
22 типа ссылок для линкбилдинга: Риск, стоимость и эффективность!, (часть 1 из 2)
1️⃣ Редакционные ссылки
Естественные, непрошенные упоминания
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 9.5/10
⏳ Долговечность: 10/10 (если сайт не умрет)
💰 Стоимость: от $0 (получено естественным путем) до $1,500+ (по договоренности)
2️⃣ Ссылки из гестпостов
Контент, размещенный на чужом сайте
⚠️ Уровень риска: Средний (при переоптимизации / если оставляют футпринты)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 6–9/10 (зависит от возраста сайта/качества контента)
💰 Стоимость: $50 – $1,200 за пост
3️⃣ Вставки ссылок / Нишевые правки
Добавление ссылки в существующий, старый контент
⚠️ Уровень риска: Средне-высокий (на плохих сайтах)
🚀 Эффективность: 8.5/10
⏳ Долговечность: 7/10 (зависит от стабильности донора)
💰 Стоимость: $30 – $800 за вставку
4️⃣ Ссылки из Digital PR
Ссылки с инфоповодов/исследований/акций
⚠️ Уровень риска: Средний (риск провала или обратного эффекта)
🚀 Эффективность: 8/10 (может достигать 10/10 при грамотном подходе)
⏳ Долговечность: 9/10
💰 Стоимость: от $250 (своими силами) до $10,000+ (через агентство)
5️⃣ Ссылки с HARO и экспертных подборок
Предоставление цитат журналистам/блогерам
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 7.5/10 (10/10 на сайтах с DR80+)
⏳ Долговечность: 10/10 (если ссылку не удалят из статьи)
💰 Стоимость: $0 (вручную) – $400/месяц (сервис/ассистент)
6️⃣ Ссылки через паразитное SEO
Ранжирование вашего контента на чужом трастовом домене
⚠️ Уровень риска: Средний (контент может быть удален сайтом)
🚀 Эффективность: 9.5/10
⏳ Долговечность: 5–8/10 (могут быстро отваливаться)
💰 Стоимость: $50 – $2,000+
7️⃣ Ссылки с PBN
Ссылки из сеток сателлитов
⚠️ Уровень риска: Высокий (при неправильной постройке/использовании или злоупотреблении)
🚀 Эффективность: 8.5/10 (с ювелирной точностью)
⏳ Долговечность: 3–7/10 (зависит от качества сетки)
💰 Стоимость: $30–$300 (своими силами) или $100–$1,000+ (через подрядчика)
8️⃣ Ссылки из PDF
Ссылки, встроенные в PDF на сайтах для обмена документами
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 6.5/10
⏳ Долговечность: 10/10 (PDF-файлы остаются онлайн)
💰 Стоимость: $0 – $50 за документ
9️⃣ Ссылки из профилей и подписей на форумах
Ссылки в профиле или под постами
⚠️ Уровень риска: Низкий
🚀 Эффективность: 5.5/10 (для тир-2/3) – 2/10 (прямые)
⏳ Долговечность: 6–9/10 (если вас не забанят на форуме)
💰 Стоимость: Бесплатно – $100/месяц (ассистент/автоматизация)
🔟 Ссылки с авторитетных профилей
Crunchbase, About.me, G2 и т.п. – для построения сущности
⚠️ Уровень риска: Нулевой
🚀 Эффективность: 6/10 (повышает траст, а не позиции)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $250 (при аутсорсе)
1️⃣1️⃣ UGC-ссылки (пользовательский контент)
Reddit, Quora, форумы, комментарии
⚠️ Уровень риска: Низкий
🚀 Эффективность: 5/10 (для тир-2/3), 6.5/10 (прямые с Reddit/Quora)
⏳ Долговечность: 7/10 (зависит от площадки)
💰 Стоимость: Бесплатно – $150 (при аутсорсе)
Конец 1-ой части.
@
Читать полностью…
Mike Blazer
18 июня 2025 08:15
Крутые вещи происходят, когда ты выводишь URL-ы продуктов на первый уровень.
До: {domain.com}/{category}/{product}
После: {domain.com}/product/{product}
Мгновенная индексация, больше показов, больше кликов.
Паттерны УРЛов рулят!
@
Читать полностью…
Mike Blazer
17 июня 2025 15:05
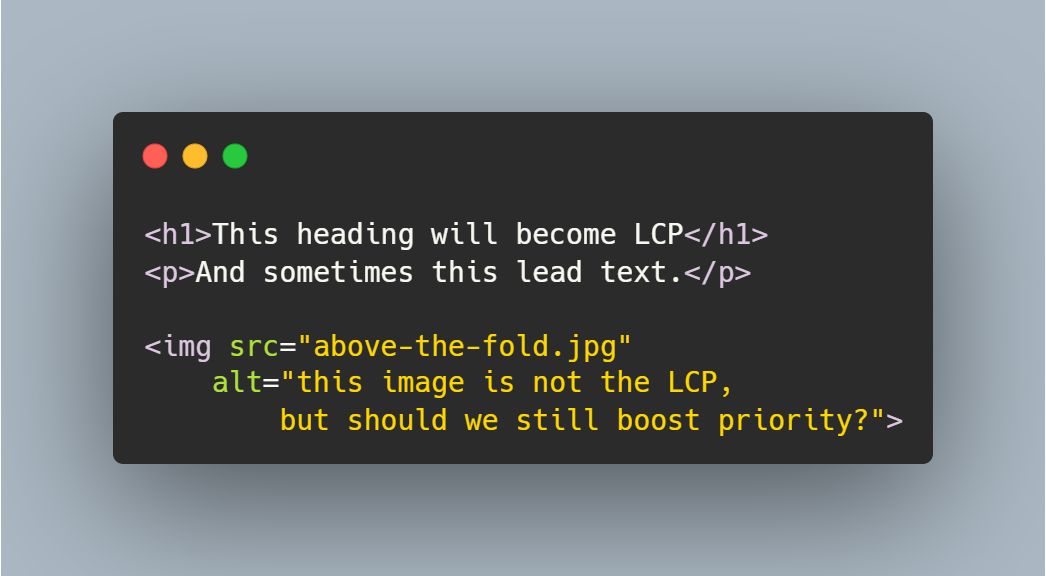
Что делать с изображениями, когда ваш H1 или лид-текст является LCP?
Ответ на самом деле прост:
→ при использовании Lighthouse может показаться, что (или ) всегда является LCP
→ но если вы собираете реальные пользовательские данные через такой инструмент, как RUMvision - мониторинг Core Web Vitals, вы могли заметить (или вам стоит знать), что LCP будет отличаться в зависимости от вьюпорта
→ что и имеет значение для CWV , а не то, что думает Lighthouse
Итак, для надежности, делайте следующее:
1️⃣ считайте ваше самое большое видимое изображение над фолдом как LCP
2️⃣ это значит: не применяйте к нему ленивую загрузку и используйте fetchpriority=high
Вот почему:
3️⃣ ваш и уже будут в исходном HTML-коде (*)
4️⃣ поэтому, загрузка вашего HTML + рендеринг этих элементов в любом случае не будут конкурировать с вашим изображением ()
5️⃣ именно поэтому безопасно повышать приоритет вашего изображения
6️⃣ при этом нужно применять это только к одному изображению на странице
(*) это применимо к `HTML` с серверным рендерингом = также лучше для скорости загрузки страницы и SEO 😜
() если вышеуказанное не применимо, потому что вы используете CSR, нюансы могут отличаться
@
Читать полностью…
Mike Blazer
24 июня 2025 13:10
Аудит по локальному SEO всегда должен начинаться с 10 телефонных звонков.
Зайдите на сайт вашего клиента и позвоните по номеру, указанному на нем.
Затем зайдите на сайты 9 его конкурентов и тоже позвоните им.
После этого сделайте несколько заметок:
— Отвечают ли они на звонки?
— Как быстро они отвечают?
— Насколько они дружелюбны?
— Насколько они готовы помочь?
— Насколько они убедительны?
— Какие у них цены по сравнению с другими?
Как ваш клиент выглядит на фоне конкурентов?
Если конкуренты отвечают на звонок за 5 секунд, а вашему клиенту нужно звонить трижды, чтобы он взял трубку, — удачи вам с таким SEO.
Скорее всего, он никогда не закрепится в топе.
Ни ссылки, ни контент, ни супербыстрый сайт не помогут сайту ранжироваться, если интент пользователя не удовлетворяется должным образом после перехода на страницу.
Ссылки толкают сайт вверх, но он рухнет камнем на дно, если пользователь останется недоволен и уйдет на другой сайт.
Начинайте свой аудит с симуляции поведения пользователя и убедитесь, что ваш клиент наилучшим образом удовлетворяет его интент.
И тогда вы увидите, как его позиции растут и закрепляются в топе, при меньших усилиях на линкбилдинг и контент.
@
Читать полностью…
Mike Blazer
24 июня 2025 08:15
Контент-стратегия с использованием дополнительного (вспомогательного) контента в сворачиваемых блоках через HTML-тег <details> поначалу работала отлично: сайты хорошо ранжировались и показывали прекрасные результаты.
Но теперь Google вывел тег <details> из игры, перестав индексировать контент внутри него.
В результате любой контент внутри тега <details> перестал индексироватся, из-за чего сайты, использовавшие этот метод, резко просели в выдаче.
Проблему подтвердил Тед Кубайтис после того, как позиции его клиента упали, а анализ исходного кода сайта выявил использование тега <details>.
Это не значит, что дополнительный контент больше не работает.
Проблема была именно в этой HTML-реализации.
@
Читать полностью…
Mike Blazer
23 июня 2025 15:05
Ключевые SEO-инсайты из материалов антимонопольного дела Google 🔍
1. 🤖 У ИИ — особый мозг: AI Overviews работают НЕ на общей модели Gemini. Они используют специально созданную модель под названием MAGIT, дообученную на огромном массиве поисковых данных и запросов Google.
2. 🖱 Сигналы ПФ правят бал (в веб-поиске): Система Navboost использует агрегированные данные о кликах пользователей за 13 месяцев для переранжирования результатов веб-поиска. Положительное вовлечение пользователей — это не просто теория, а основной, долгосрочный фактор ранжирования.
3. 🧩 Сигналы ПФ повсюду (для фич СЕРПа): Система под названием Glue выполняет ту же работу, что и Navboost, но для *всех остальных элементов поисковой выдачи* (панелей знаний, локальных блоков и т.д.). Это означает, что взаимодействие пользователя определяет всю компоновку СЕРПа.
4. 💥 "Query Fan-Out" — это реальность: Системы ИИ раскладывают один пользовательский запрос на несколько подзапросов, чтобы собрать всестороннюю информацию. Ваш контент должен раскрывать множество аспектов темы, а не только один ключевик, чтобы попасть в итоговый синтезированный ответ.
5. 🗂 ИИ "просматривает" страницы из кэша: Когда AI Overviews "обращаются" к URL, они в первую очередь получают доступ к собственному внутреннему, кэшированному представлению вашей страницы, а не загружают ее в реальном времени.
6. 🧮 Как объединяются сигналы: Система RankEmbed от Google использует dot product (а не только косинусное сходство). Это критически важно, поскольку позволяет совмещать семантическую релевантность с *величиной* (т.е. важностью) традиционных сигналов, таких как PageRank и оценка качества сайта под названием Q***.
7. 🏆 **Дорогой ИИ — только для финалистов: Самые мощные модели глубокого обучения (RankBrain, DeepRank) вычислительно затратны, поэтому они используются только для переранжирования небольшого, предварительно отфильтрованного набора из *20-30 лучших результатов*. Сначала вам нужно пробиться в этот топ с помощью традиционных сигналов.
8. 📄 Ранжирование по пассажам теперь критически важно для RAG: AI Overviews используют фреймворк Retrieval-Augmented Generation (RAG). Сначала они извлекают наиболее релевантные *пассажи* из топовых страниц, а затем генерируют саммари. Структурирование контента в виде четких, хорошо определенных блоков теперь важно как никогда.
9. 📈 Хорошие сигналы вам не навредят: Система ранжирования спроектирована так, что улучшение одного положительного фактора ранжирования имеет монотонный эффект — это *никогда* не должно вредить вашим позициям. Нет никаких санкций за чрезмерную оптимизацию одного валидного сигнала.
10. 🗣 Первый барьер — ясность (QUS): Перед любым ранжированием сервис Query Understanding Service (QUS) переписывает и устраняет неоднозначность вашего запроса. Четкий и однозначный контент помогает на этом первом критически важном этапе.
11. 🔗 Традиционное SEO НЕ умерло: Документы показывают, что это "эволюция, а не революция". Сигналы, созданные вручную, принципы информационного поиска (IR) и линейные комбинации факторов по-прежнему являются фундаментальной основой поиска.
12. 🏢 Фиды со структурированными данными — это отдельная магистраль: У Google есть отдельный, параллельный канал для приема структурированных "фидов" (Merchant Center, данные о рейсах, вакансии и т.д.), который работает независимо от обычного краулинга. Для соответствующих бизнесов это важнейший фаст-трек.
13. 🔮 Будущее перестраивается: Хотя текущие системы эволюционны, Google активно "переосмысливает свой поисковый стек с нуля", чтобы отвести LLM более заметную роль во всех ключевых функциях. Это сигнализирует о том, что на горизонте маячит крупная трансформация.
https://www.linkedin.com/pulse/deconstructing-googles-ai-search-insights-from-antitrust-geraci-ezf7c/
@
Читать полностью…
Mike Blazer
23 июня 2025 11:05
Новый букмарклет извлекает поисковые запросы, которые ChatGPT использует во время диалогов.
Что он делает:
👉 Извлекает поисковые запросы напрямую из функции поиска ChatGPT в вебе.
👉 Открывает результаты в новой вкладке с профессиональным форматированием.
👉 Копирование в буфер обмена в один клик (идеально для вставки в Excel/Таблицы).
👉 Не требует скачивания или установки.
Букмарклет разработан для работы с любыми диалогами в ChatGPT, которые используют веб-поиск Bing.
Это делает его удобным инструментом для быстрого анализа и повторного использования поисковых запросов для исследований или планирования контента.
Полная инструкция и сам букмарклет:
https://www.shtros.com/chatgpt-search-query-extractor/
@
Читать полностью…
Mike Blazer
22 июня 2025 15:05
Какая подпись к фотке вам нравиться больше?
1. Да, вы все остаетесь без работы, но показатель под названием "показы" значительно вырос.
2. Фиолетовая линия = сколько денег зарабатывает Google
Синяя линия = сколько денег зарабатываете вы
@
Читать полностью…
Mike Blazer
20 июня 2025 17:05
Эх, сеошники
@
Читать полностью…
Mike Blazer
20 июня 2025 13:10
Жиза
@
Читать полностью…
Mike Blazer
20 июня 2025 08:15
Люди путают "оригинальность" с "уникальностью".
На ивенте SEOFOMO Алейды в Лондоне Гари Иллиес сказал, что в будущем Google будет отдавать приоритет "оригинальному" контенту.🧝♂️
Если вы используете LLM для генерации контента, вы получите нечто уникальное, но не оригинальное.
Если вы возьмете свои собственные данные, истории, опыт и прогоните их через LLM для написания текста, он будет оригинальным.
Но даже в этом случае вы потеряете одну из "фишек" оригинальности — возможность умело применять стиль.
Скорее всего, у нас у всех коллективно выработается новый вид "баннерной слепоты" к текстам в стиле GPT.
"Я уже ловлю себя на том, что начинаю читать что-то, тут же чувствую, что это написано GPT, и иду дальше", — говорит Марк Уильямс-Кук.
Оригинальность будет становиться еще более редкой и ценной.
@
Читать полностью…
Mike Blazer
19 июня 2025 15:05
Укради 20 копирайтерских лего-блоков Эндрю Энсли
Вот промпт, который он использует, чтобы AI написал целую страницу...
Используй мой ICP, информацию о бизнесе и стилевую структуру для страницы воронки, которой нужен копирайт. Вот контекст для тебя:
{icp}
{biz info}
{style}"
-
Полная структура из 20 блоков:
1️⃣ Блок Большого Обещания - Захвати внимание мощным заявлением о трансформации
2️⃣ Блок Вступления Истории - Создай интимную, разговорную атмосферу с личным обращением
3️⃣ Блок Старого Подхода - Ярко покажи текущие разочарования и болевые точки
4️⃣ Блок Нового Подхода - Представь своё решение как очевидную альтернативу
5️⃣ Блок Истории Происхождения - Объясни, как ты открыл или разработал свою систему
6️⃣ Блок Тройного Доказательства - Соедини личные результаты, социальные доказательства и проекцию
7️⃣ Блок Честности - Построй доверие, устанавливая реалистичные ожидания
8️⃣ Блок Блок-Схемы - Визуально противопоставь "Старый способ" vs "Новый способ"
9️⃣ Блок Аннотированных Результатов - Покажи реальные данные с выделениями, направляющими взгляд читателя
🔟 Блок Предложения - Представь стек ценности + бонусы для повышения воспринимаемой ценности
1️⃣1️⃣ Блок Будущего - Помоги потенциальным клиентам представить лучшую жизнь с твоим решением
1️⃣2️⃣ Блок Скептика - Разбери сомнения до того, как они сорвут продажу
1️⃣3️⃣ Блок Снятия Рисков - Убери страх с помощью сильной гарантии
1️⃣4️⃣ Блок Да/Нет - Дай смелое указание к покупке
1️⃣5️⃣ Блок Ценового Якоря - Покажи скидку от более высокой розничной цены или варианты оплаты
1️⃣6️⃣ Блок P.S. Резюме - Подытожь предложение для тех, кто просто сканирует страницу; усиль срочность
1️⃣7️⃣ Блок Мини-Отзывов - Предоставь небольшие реальные истории успеха рядом с CTA
1️⃣8️⃣ Блок Обоснования - Объясни, почему ты предлагаешь такую выгодную сделку
1️⃣9️⃣ Блок Юридической Оговорки - Включи информацию о соответствии, отказ от ответственности за доходы и т.д.
2️⃣0️⃣ Блок Тизера Апселла - Намекни на продукт более высокого уровня или "следующий шаг" после покупки
-
Результат - отличная отправная точка, позволяющая скипнуть много рутинной работы.
Оригинал тут.
@
Читать полностью…
Mike Blazer
19 июня 2025 11:05
Интересный способ найти дроп-домен про который уже знает AI + он имеет историю 🍿.
Делая ресёрч обнаружил что chat.gpt рекомендует сайты которые уже не работают, при этом он утверждает то, что они предоставляют услуги которые я искал, пишет Наум.
Я решил проверить, а не дропы ли это случайно?
Оказалось что из списка сайтов несколько было в продаже.
Я решил протестить, создав такой запрос ( представьте что я хочу открыть сайт по content/blog writing services в Канаде):
Сформируй мне список лучших сервисов по content or blog writing services в Канаде за 2015 - 2018 год?
Постарайся включить в список сайты которые уже не работают.
Из списка не все сайты попадают под мой запрос, но есть пару интересных вариантов:
1) Contentgather.com - Скриншот 1 / Скриншот 2 + история с 2016.
Продаётся за 8к. Вебархив
2) Contentrunner.com - Скриншот 3 / Скриншот 4.
Нужно делать оффер что бы выкупить.
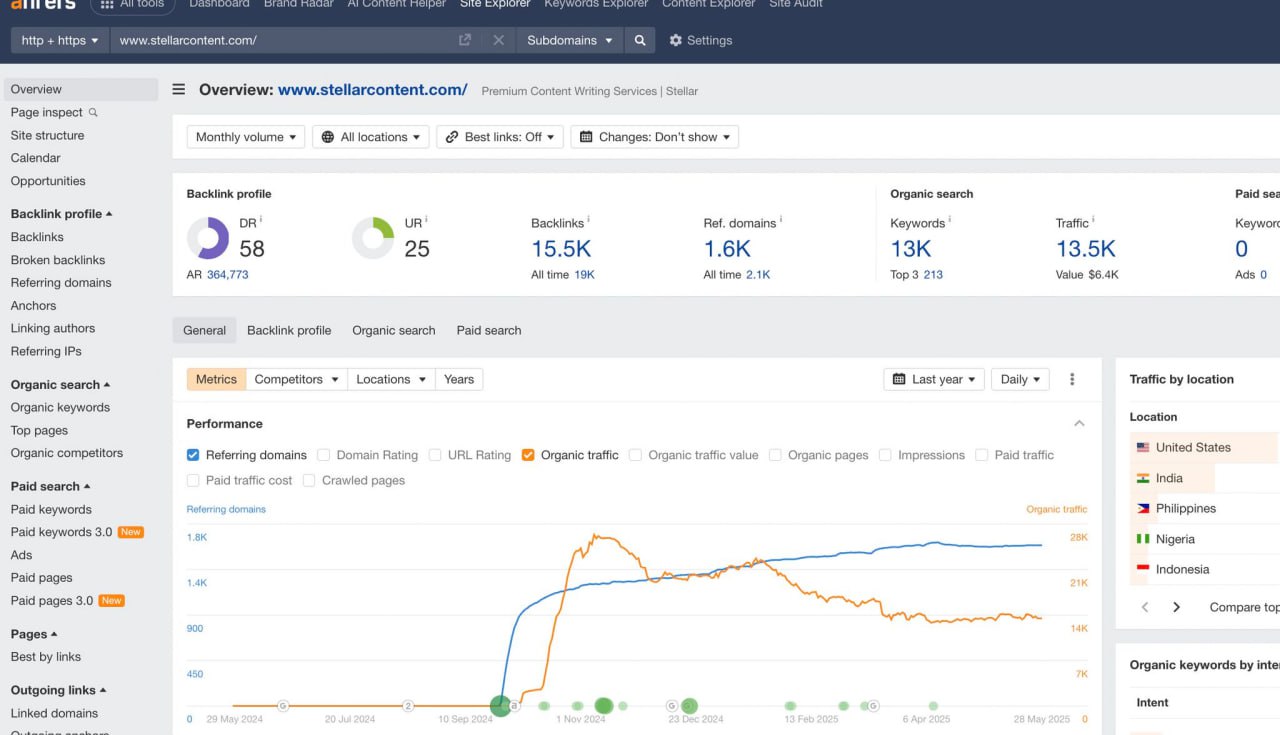
Интересный кейс с Stellarcontent.com.
Эти ребята средиректили - crowdcontent.com на себя и получили офигенный буст.
Но возможно это просто ребрендинг и это в прошлом их же проект.
Вебархив
Буст - Скриншот 5 (момент 301 - Скриншот 6).
Менее интересные сайты:
— Textnerd.com - история с 2013. Вебархив Продаётся за 995$.
— ContentWriters.ca - продаётся за дорого, история с 2009. Вебархив
*Домены не проверялись детально и могли быть использованы, суть поста показать механику поиска.
@
Читать полностью…
Mike Blazer
18 июня 2025 17:05
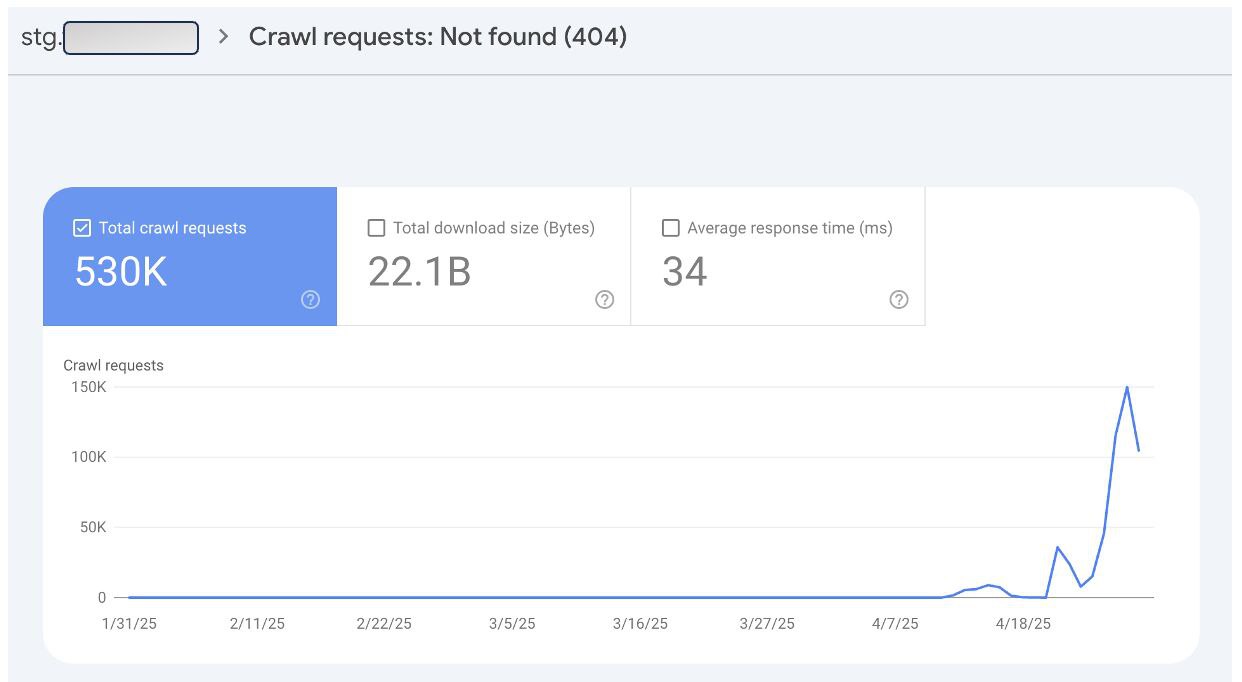
Гугл: 404-е — это нормально!
Они — естественная часть веба.
Можете просто их игнорировать, и мы тоже будем.
Тем временем Гугл, увидев, что стейджинг начал отдавать 404-е *и* получил запрос на удаление страниц в GSC: Я ПРОКРАУЛЮ ТЕБЯ 530 ТЫСЯЧ РАЗ!
@
Читать полностью…
Mike Blazer
18 июня 2025 13:15
22 типа ссылок для линкбилдинга: Риск, стоимость и эффективность!, (часть 2 из 2)
1️⃣2️⃣ Локальные цитирования / Ссылки из каталогов
NAP (Название, Адрес, Телефон) для локального SEO
⚠️ Уровень риска: Нулевой (если не спамить)
🚀 Эффективность: 7/10 (только для локального SEO)
⏳ Долговечность: 10/10
💰 Стоимость: Бесплатно – $300 (самостоятельно vs через сервис)
1️⃣3️⃣ Ссылки с Web 2.0
WordPress.com, Tumblr, Blogger и т.п., часто как прокладки/для тиров
⚠️ Уровень риска: Низкий (для тир-2/3); Средний (спамный Тир-1)
🚀 Эффективность: 5.5/10 (Тир-1); 7.5/10 (стратегия для Тир-2)
⏳ Долговечность: 8/10
💰 Стоимость: Бесплатно – $100 (ассистент/боты)
1️⃣4️⃣ Ссылки с изображений
Инфографика, мемы, диаграммы, вставки
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 6.5/10 (выше на трастовых сайтах)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $300+ за графику
1️⃣5️⃣ Ссылки из пресс-релизов
Ссылки через новостные агрегаторы и синдикацию
⚠️ Уровень риска: Низкий (если не злоупотреблять/не спамить)
🚀 Эффективность: 7/10 (для динамики), 5/10 (для прямого влияния на ранжирование)
⏳ Долговечность: 6/10 (зависит от срока хранения новости агрегатором)
💰 Стоимость: $75 – $800
1️⃣6️⃣ Ссылки с доменов .EDU / .GOV
Ссылки с образовательных/государственных учреждений
⚠️ Уровень риска: Низкий (если легально); Высокий (если перемудрить со схемой)
🚀 Эффективность: 9/10
⏳ Долговечность: 10/10 (если страница не умрет/админ не удалит)
💰 Стоимость: Бесплатно (получено естественным путем) – $1,500+ (платные размещения)
1️⃣7️⃣ Обмен ссылками
Взаимный обмен, схемы A-B-C
⚠️ Уровень риска: Средний (если злоупотреблять или схема легко отслеживается)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 5–9/10 (зависит от размера сетки)
💰 Стоимость: Бесплатно – $500+
1️⃣8️⃣ Ссылки с купонных и скидочных сайтов
Ссылки с сайтов вроде RetailMeNot, Groupon и т.п.
⚠️ Уровень риска: Низкий (если не спамить)
🚀 Эффективность: 7.5/10
⏳ Долговечность: 6–9/10 (пока действует предложение)
💰 Стоимость: Бесплатно – $500
1️⃣9️⃣ Ссылки с вебинаров, видео и подкастов
В описаниях, шоу-ноутах, биографиях спикеров
⚠️ Уровень риска: Нулевой
🚀 Эффективность: 8/10 (сильно недооценены)
⏳ Долговечность: 10/10
💰 Стоимость: Бесплатно – $1,000 (своими силами vs спонсорство)
2️⃣0️⃣ Ссылки из отзывов
Предоставление отзыва в обмен на ссылку
⚠️ Уровень риска: Минимальный
🚀 Эффективность: 7/10 (при грамотном размещении)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $150 (стоимость использования продукта/услуги)
2️⃣1️⃣ Ссылки в сайдбаре и футере
Сквозные ссылки (сквозняки)
⚠️ Уровень риска: Высокий
🚀 Эффективность: 8/10 (если они чистые и релевантные)
⏳ Долговечность: 4–7/10
💰 Стоимость: $50 – $500 (часто с помесячной оплатой)
2️⃣2️⃣ NoFollow и Sponsored ссылки
Ссылки с атрибутами rel="nofollow" или rel="sponsored"
⚠️ Уровень риска: Отсутствует
🚀 Эффективность: 4/10 (для ранжирования) – 8/10 (для траста и динамики)
⏳ Долговечность: 9/10
💰 Стоимость: Бесплатно – $1,000+
https://presswhizz.com/blog/types-of-backlinks/
@
Читать полностью…
Mike Blazer
18 июня 2025 11:05
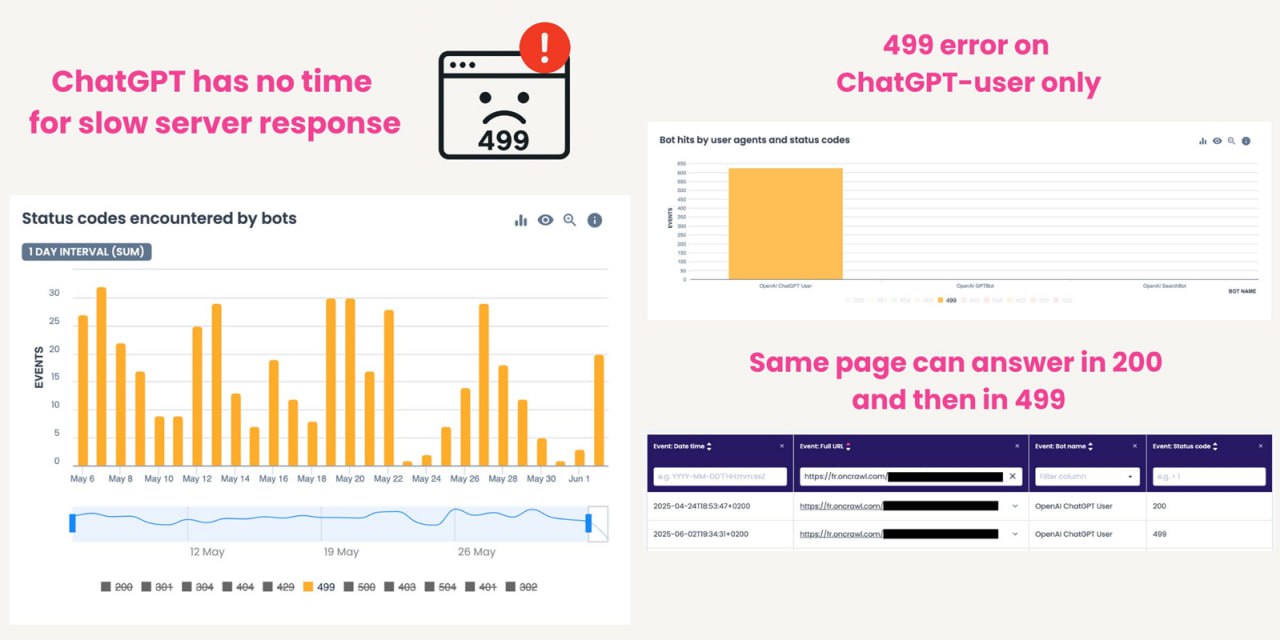
У ChatGPT нет времени на ваши медленные страницы ⏱️
Анализируя ботов OpenAI в логах сервера, я наткнулся на то, что нечасто встретишь у Гуглобота: множественные хиты от ботов с кодом ответа HTTP 499, — пишет Жером Саломон.
Что такое 499-я ошибка?
Код ответа HTTP 499 означает, что клиент закрыл соединение до того, как сервер успел ответить.
В нашем случае клиент — это бот, отправленный ChatGPT, который прерывает запрос из-за задержки ответа сервера.
🔍 Углубившись в анализ, я обнаружил:
— 99% этих хитов с 499-й ошибкой приходится на бота ChatGPT-user.
— Эта ошибка встречается не на всех сайтах.
— Ее доля может достигать 5% от всех хитов бота ChatGPT-user.
— Некоторые страницы могут на один запрос отдавать код 200, а на другой — 499.
Почему это важно?
ChatGPT-user — это бот, которого ChatGPT Search отправляет в режиме реального времени, чтобы получить контент и использовать его в качестве цитаты в ответе.
Он всегда краулит несколько источников одновременно, чтобы собрать самую релевантную информацию и на лету сформулировать исчерпывающий ответ.
Если ChatGPT-user закроет соединение до того, как ваш сервер успеет ответить, ваша страница не будет использована в ответе.
Вы упускаете возможность быть процитированным и, возможно, даже получить реферальный трафик.
🧠 Теории:
Учитывая, что поиск ChatGPT работает в реальном времени, он не может позволить себе ждать медленные страницы.
Если ваш сервер отвечает медленно или страница грузится слишком долго, ChatGPT прервет запрос, что и приведет к ошибке 499.
1. Вероятно, ChatGPT Search использует правила таймаута, чтобы обеспечить быстрые ответы и хороший пользовательский опыт.
2. Боту ChatGPT-user больше не нужно ждать вашу страницу — возможно, потому что процесс краулинга останавливается, как только X страниц успели ответить вовремя.
Это объясняет, почему одна и та же страница иногда отдает 200-й код, а иногда — 499-й.
Это значит, что ваш сайт конкурирует с другими по времени ответа сервера и скорости загрузки страниц.
Растущая важность Bot Experience
Это подчеркивает критический сдвиг: одной лишь оптимизации под пользовательский опыт уже недостаточно.
И дело не только в скорости.
Бот ChatGPT не рендерит JavaScript.
Если показ контента на вашей странице сильно зависит от JS, она будет невидима для бота.
Ему нужен быстрый, чистый, хорошо структурированный HTML.
В меняющемся ландшафте поиска с использованием ИИ приоритизация опыта взаимодействия с ботами становится критически важной.
Быстрый, доступный и хорошо структурированный контент не только улучшает вовлеченность пользователей, но и повышает вероятность того, что ваши страницы будут процитированы в ответах, сгенерированных ИИ.
@
Читать полностью…
Mike Blazer
17 июня 2025 17:05
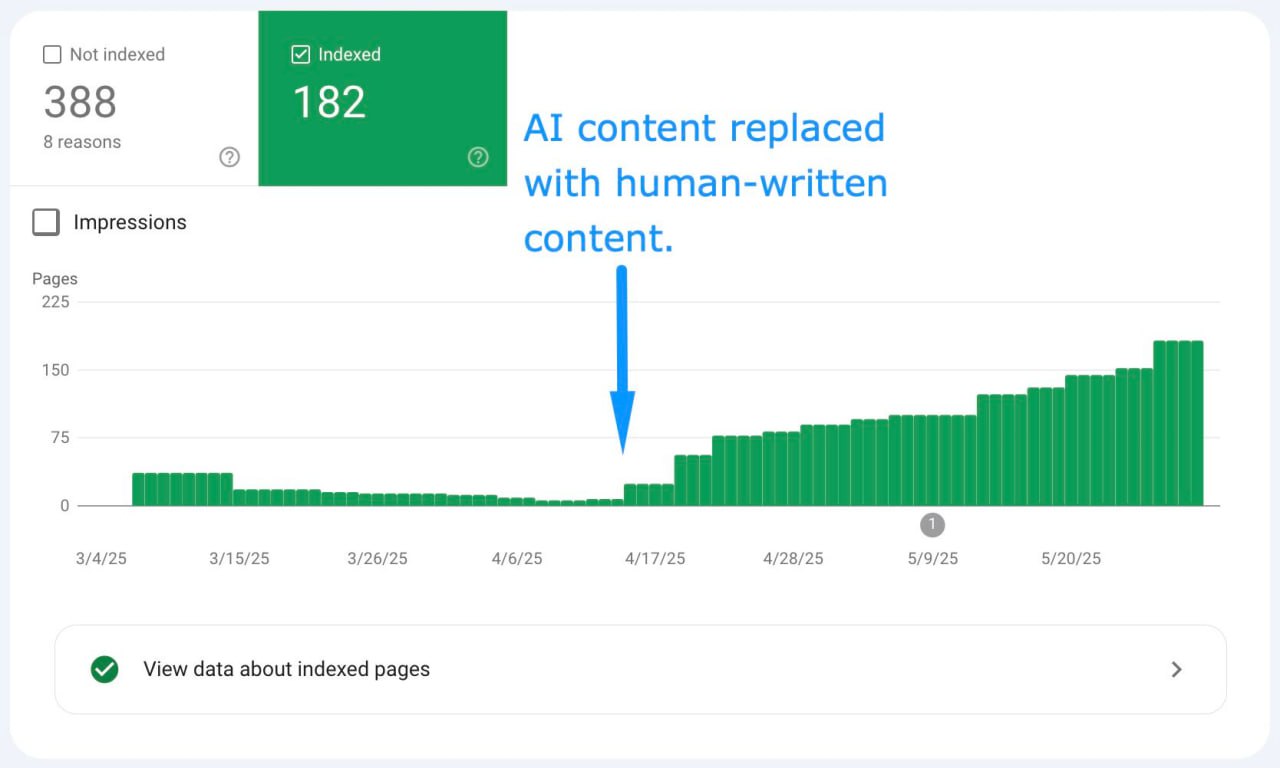
Влияет ли замена AI-контента на созданный человеком контент на индексацию?
А то! Еще как может 😂
Вот вам кейс: программатик-сайт (продукт на базе ИИ), который в прошлом году взломали и он вылетел из индекса Гугла.
Прошло 9+ месяцев, а сайт все еще с трудом попадал в индекс, когда они пришли ко мне.
С безопасностью все было чисто.
Мы перепробовали ВСЕ, чтобы улучшить SEO, пользовательский опыт и авторитет сайта, — пишет Кристан Бауэр.
Ничего не давало долгосрочного эффекта.
Мы видели временные всплески индексации, но потом Гугл снова и снова выбрасывал эти страницы из индекса.
В конце концов клиент вернулся к одной из моих первоначальных рекомендаций: протестировать замену AI-контента на контент, написанный человеком.
Ооо, какая свежая мысль 😂
Будучи AI-продуктом, они ИСКЛЮЧИТЕЛЬНО использовали сгенерированный ИИ контент по всему сайту — как программатик-контент, так и редакционные материалы.
Моя рекомендация была просто протестировать гипотезу и убедиться в ее состоятельности, прежде чем вкладывать значительные ресурсы.
И что бы вы думали...
Моментальная индексация и видимость. 👏
Эти цифры все еще ОЧЕНЬ скромные, и им предстоит ДОЛГИЙ путь, чтобы вернуть сайту былую славу.
Но это уже прогресс.
Другие внесенные нами изменения улучшат вовлеченность и позиции, но "серебряной пулей" здесь стала замена AI-контента на качественный авторский контент.
Заставляет задуматься, не так ли?!
ЛОЛ.
Я не говорю, что любой AI-контент не будет работать или индексироваться, но в данном случае ВЕСЬ контент был сгенерирован ИИ, что, вероятно, и вызвало проблемы с качеством.
@
Читать полностью…
Mike Blazer
17 июня 2025 13:10
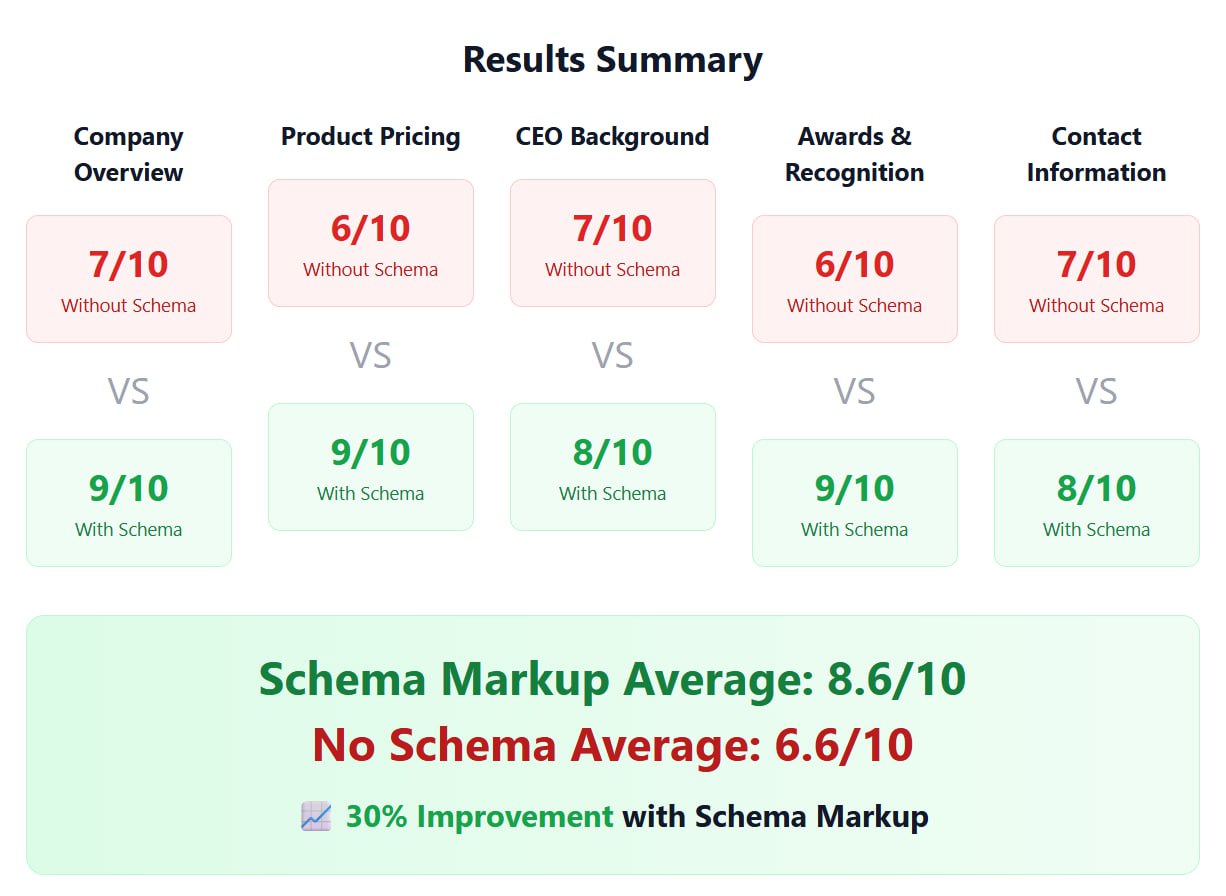
Давайте выясним, насколько хорошо ChatGPT видит контент на ваших страницах.
Итак, вот эксперимент о влиянии микроразметки Schema.org на видимость для LLM.
Я хотел получить сухие факты о влиянии микроразметки на видимость в AI-поиске, — говорит Бенджамин Танненбаум.
Действительно ли она улучшает то, что ChatGPT знает обо мне?
Поэтому я сделал сайт с двумя подстраницами.
С одинаковой информацией. Одна с микроразметкой Schema.org, другая — без.
Я попросил ChatGPT ответить на конкретные вопросы по каждой из них.
Результаты?
С микроразметкой: в среднем 8.6/10
Без микроразметки: в среднем 6.6/10.
-> 📈 Улучшение на 30% с микроразметкой!
Особенно сильно это повлияло на структурированные данные: пользовательские рейтинги (4.8/5 звезд) и сертификаты (ISO 27001, SOC 2) появились только в ответах для страницы с микроразметкой!
И улучшение происходит моментально!
Не нужно ждать шесть месяцев, как с другими полезными вещами, вроде сторонних источников.
И что самое крутое?
Вы можете сами все проверить — все данные в открытом доступе.
Вывод: внедряйте микроразметку Schema.org правильно, чтобы улучшить видимость для LLM (и ранжирование в Google!).
https://www.getaiso.com/blog/schema_markup_experiment_blog_post
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}