Mike Blazer
18 июля 2025 17:05
Слаженная работа SEO-агентства
@
Читать полностью…
Mike Blazer
18 июля 2025 13:10
Оптимизация текста сгенеренного AI
@
Читать полностью…
Mike Blazer
18 июля 2025 08:15
Влияют ли ссылки на AI Overviews?
Ahrefs недавно опубликовали исследование по 75 000 брендам о факторах видимости в AI Overview.
Анализ показал, что корреляция между упоминаниями бренда в сети и видимостью в AI составляет 0.664, в то время как у бэклинков этот показатель — всего 0.218.
Проще говоря: упоминания > ссылок.
Вот как получать брендовые упоминания, которые любит Google:
1. PR и продвижение через экспертизу
Предлагайте отраслевым изданиям материалы с аналитикой и данными.
Каждая статья, где упоминается ваша экспертиза, распространяет имя вашего бренда.
2. Стратегический ко-маркетинг
Партнерьтесь с брендами из смежных ниш для проведения вебинаров, подготовки отчетов или организации мероприятий.
Перекрестное опыление аудиторий = больше упоминаний.
3. Истории клиентов
Мотивируйте клиентов публично делиться своими успехами (в соцсетях, на сайтах-отзовиках, в своих блогах).
Поощряйте их небольшими бонусами.
4. Отраслевые подборки
Связывайтесь с сайтами, которые составляют списки в духе "Лучшие компании в [ваша отрасль]".
Большинство из них готовы добавить вас, если ваш бренд соответствует тематике.
5. Брендовый анкор
Когда вы все-таки получаете ссылки, просите ставить в анкор точное название вашего бренда вместо общих фраз.
"Компания ABC" работает для AI лучше, чем "этот классный инструмент" или "кликните здесь".
6. Создание комьюнити на форумах
Станьте полезным экспертом на отраслевых форумах.
Естественные упоминания бренда появляются, когда вы решаете реальные проблемы людей.
@
Читать полностью…
Mike Blazer
17 июля 2025 15:05
Google в очередной раз подтверждает, что "все, что вы делаете для улучшения ранжирования", не является фактором ранжирования, и просит прекратить это, поскольку это нарушает их ранжирование.
@
Читать полностью…
Mike Blazer
17 июля 2025 11:05
Этот простой сайт фонетической транскрипции посещают более 800 000 человек в месяц.
Он занимает высокие позиции по таким ключевым словам, как "phonetic spelling generator" и "ipa translation".
Монетизируется с помощью рекламы.
Вероятно, приносит более $2000 долларов в месяц.
Неплохо для простого статического сайта!
@
Читать полностью…
Mike Blazer
16 июля 2025 17:05
Я заметил одну из самых диких тактик черного SEO для LLM, которые я когда-либо видел, — пишет Джейсон Дауделл.
Она работает прямо сейчас.
Так что я ее документирую.
Вот схема:
→ Берешь любой партнерский сайт в своей нише
→ Парсишь контент
→ Меняешь брендинг (лого, автора, домен)
→ Остальное оставляешь как есть
→ Поднимаешь 10–15 клонов
→ Хостишь их где-то за ~$200 в месяц
→ Публикуешь по одной странице за раз
→ Расслабляешься и ждешь
Нет трафика? Не проблема.
Это не для Гугла.
Это для ChatGPT.
Почему это работает:
LLM не ранжируют страницы.
Они вычисляют статистическую вероятность.
Чем больше сайтов говорят одно и то же — тем увереннее становится модель.
Так что, если 15 разных доменов ставят "Компанию А" на первое место в рейтинге по запросу [ваш ключевик], угадайте, кого процитируют?
Тебя 😎
Не лучший контент.
Не самый трастовый источник.
А просто самый *статистически подкрепленный*.
Пример, который я видел:
Никаких бэклинков.
Никакого трафика.
Отстойный UX.
И все равно цитируется в ChatGPT как источник по запросу "best LLC services".
Давайте начистоту:
Это чернуха. 🎩
Она создана для манипуляции AI-моделями.
И в текущей экосистеме — это *работает*.
LLM все еще находятся в своей "наивной" эре.
Никакого взвешивания.
Никакой памяти о трастовости домена.
Просто поверхностная агрегация.
Так что да — это жесть.
Но это также и сигнал:
Мы находимся в "до-Пингвиновой" фазе LLM-маркетинга.
Снова 2011-й.
И кто-то только что изобрел линкофермы для AI.
Надолго ли это?
В долгосрочной перспективе — вряд ли.
Но сегодня это работает.
@
Читать полностью…
Mike Blazer
16 июля 2025 13:10
Лили Рей:
Блин...
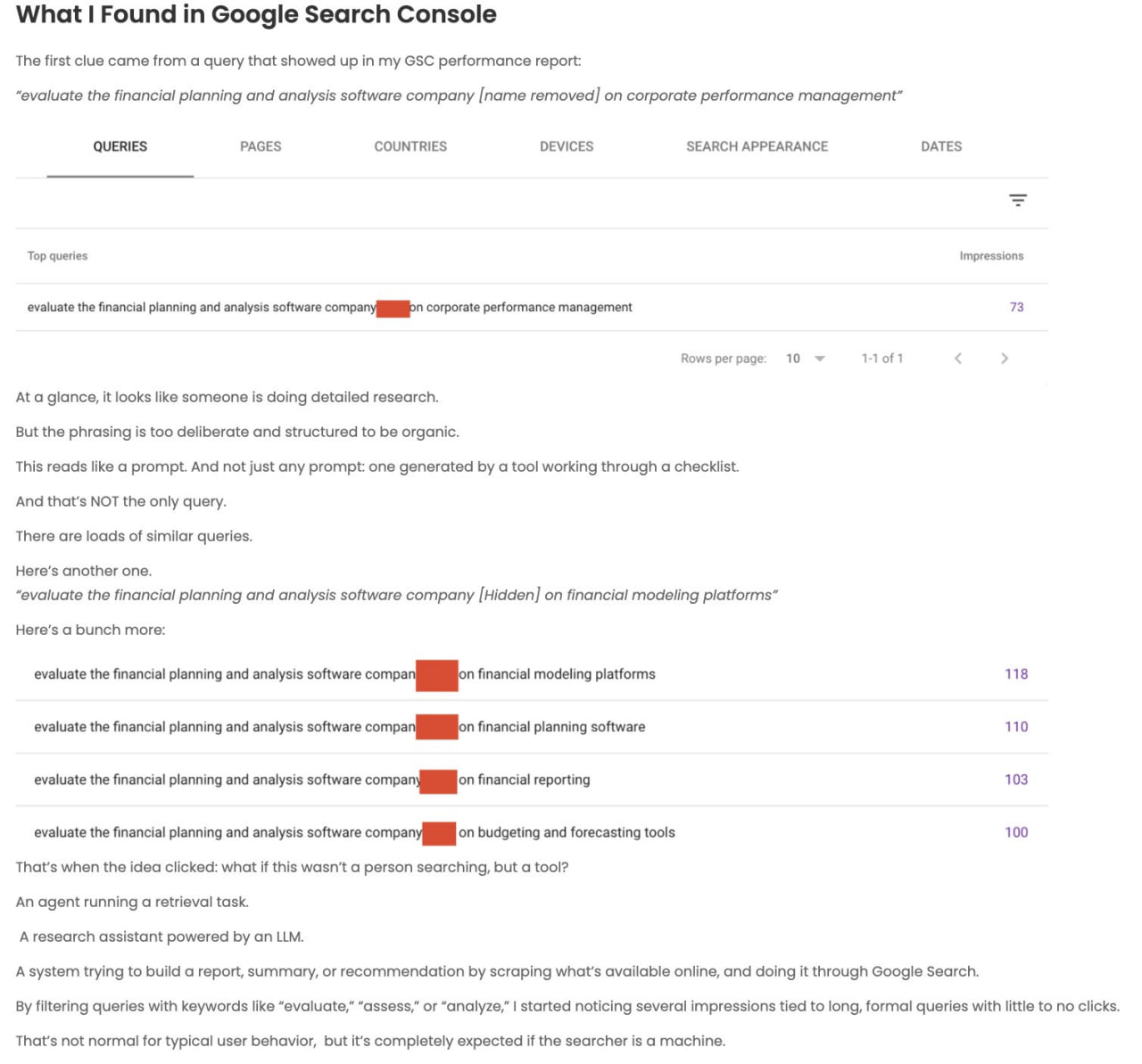
Инструменты отслеживания LLM (или некоторые другие агенты/скреперы) создают огромное количество "оценочных" запросов в GSC и Bing Webmaster Tools.
Еще одна причина, почему скачут показы.
Что за бардак.
Майк Кинг:
Интересный побочный эффект от создания новой категории: я, *кажется*, только что наткнулся на что-то, связанное с query fan-out.
Сайт iPullRankAgency получает наибольшую видимость по запросам, связанным с relevance engineering, в AI-фичах Google (что и логично), но я заметил определенный паттерн в некоторых запросах, ведущих на эти страницы.
У всех у них есть этот паттерн: "evaluate" + entity on [thing].
Моя гипотеза заключается в том, что это один из синтетических паттернов запросов, используемых для сбора документов и пассажей для последующего синтеза.
Я просмотрел кучу профилей в GSC, и гипотеза, похоже, подтверждается.
Интересно, что вы, ребята, видите у своих клиентов.
Харприт:
Я писал об этом несколько недель назад, наблюдаю такое в GSC у многих SaaS-компаний.
Думаю, это следы инструментов для глубокого исследования https://harpsdigital.com/ai-in-google-search-console/
Вижу нечто подобное и в Bing, но запросы в Bing Webmasters Tools там намного длиннее.
---
Вот о чем я говорил тут.
@
Читать полностью…
Mike Blazer
16 июля 2025 08:15
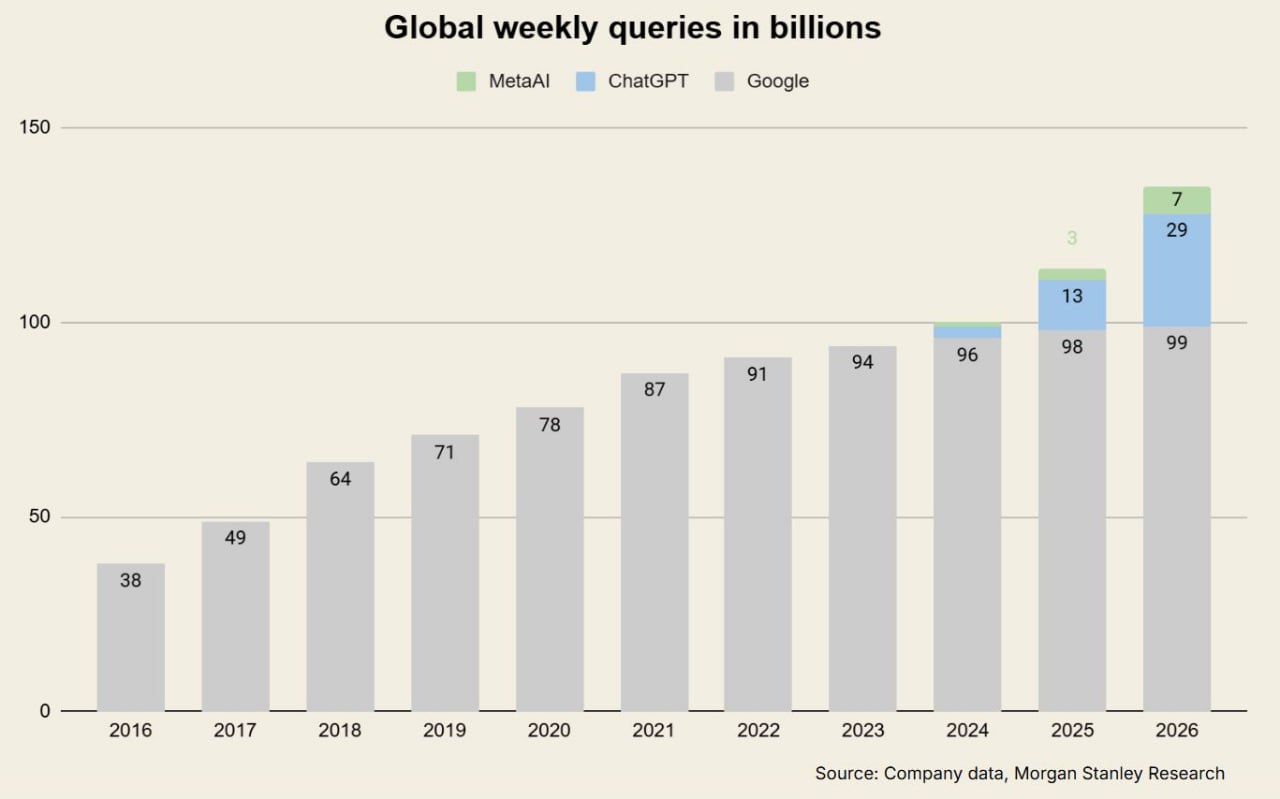
Объем поиска в Google не упал…
ПОКА ЧТО
Пользовательский поиск терпит значительные изменения — в частности, с появлением ChatGPT, а также из-за того, как молодое поколение использует TikTok и другие платформы.
Несмотря на эти изменения, мировой объем поиска в Google все еще растет, хоть и незначительно.
Однако темпы его роста сильно замедляются.
Вот отличная инфографика от Morgan Stanley, которая показывает еженедельное количество запросов по всему миру.
Google сейчас будет агрессивно продвигать обзоры с ИИ (AI overviews), хотя они немного опоздали с этим, пока столько внимания уделялось тонкой настройке их модели.
В следующих постах я рассмотрю более широкие последствия для брендов, но для начала я не видел много информации о доле рынка и хотел бы выделить несколько ключевых аспектов.
💬 Ожидается, что к 2026 году только на ChatGPT будет приходиться 21% всех поисковых запросов.
📉 Gartner прогнозирует, что к 2026 году объем поисковых запросов в поисковых системах упадет на 25% из-за чат-ботов с ИИ и других виртуальных ассистентов.
🎥 Однако для Google есть и положительные моменты: 57% людей используют YouTube для поиска информации так же, как и Google.
🛒 Google также быстро отбирает долю у Amazon в США среди молодой аудитории и захватывает здесь долю на поисковом рынке.
@
Читать полностью…
Mike Blazer
15 июля 2025 15:05
Я обожаю, когда люди вставляют ответы ChatGPT с Markdown-разметкой в свои резюме, — говорит Майкл Кинг.
Это значительно экономит мое время при рассмотрении кандидатов.
@
Читать полностью…
Mike Blazer
15 июля 2025 11:05
Один из самых распространенных способов, которым продавцы ссылок накручивают трафик в SEO-инструментах, — это создание постов в блоге под страницы для входа.
Например, продавец может создать пост под запрос "Disney Plus login page".
У этой ключевой фразы огромный поисковый объем — потенциально миллионы запросов в месяц.
Даже если созданный пост будет плохо ранжироваться (например, занимать 36-ю позицию), система подсчета Ahrefs все равно спрогнозирует, что страница получает значительный объем трафика (например, 38 000 в месяц) из-за высокой частотности ключа.
В действительности страница может получать очень мало реальных посещений, но в отчете Ahrefs будут отображаться раздутые показатели трафика, что, по сути, является злоупотреблением системой подсчета Ahrefs.
Этот метод используется для того, чтобы сайт выглядел более ценным, чем он есть на самом деле, с целью продажи ссылок.
@
Читать полностью…
Mike Blazer
14 июля 2025 17:05
КАК ОБЕЗОРУЖИТЬ МАСТЕРА AI-ПУСТОСЛОВИЯ?
Сфера маркетинга сейчас переполнена энергичными продажниками, которые впаривают воздух доверчивым клиентам.
Они будут закидывать вас правдоподобно звучащими фразами, потому что у них есть доступ к ChatGPT, но это не значит, что они в этом хоть что-то понимают или что это сработает в вашем случае.
Не ведитесь на заумные словечки и аббревиатуры.
Вместо этого делайте так:
Спрашивайте: "Как?"
Повторяйте этот вопрос, пока не дойдете до самых технических деталей.
Продолжайте докапываться, пока не доберетесь до механического, измеримого процесса.
Или пока этот бред не прекратится.
Пример:
"Мы используем предиктивную аналитику на базе ИИ для оптимизации вашей маркетинговой воронки!"
Как?
"Система использует продвинутые алгоритмы машинного обучения для анализа пользовательских данных!"
Как?
"Она анализирует историю поведения клиентов, чтобы спрогнозировать их будущие действия!"
Как?
"Она отслеживает клики, время на сайте и конверсии, а затем на основе статистических моделей оценивает, какие лиды с наибольшей вероятностью совершат покупку".
Как?
"Мы загружаем эти данные в наш алгоритм, который является Python-скриптом, использующим random forest classifier в scikit-learn".
Как это приводит к улучшению "видимости ИИ"?
Где здесь связь?
"Ну, определяя лиды с наибольшей вероятностью конверсии, мы можем сосредоточить на них маркетинговые усилия".
Как фокус на потенциальных лидах улучшает "видимость ИИ"?
"Потому что наш таргетинг становится точнее, и больше людей видят релевантные объявления".
Какое конкретное отношение это имеет к "видимости ИИ", а не просто к таргетингу рекламы?
"Ну, ИИ предоставляет инсайты о том, какая аудитория наиболее вовлечена, что делает показатели эффективности более прозрачными".
В каком виде представляются эти инсайты?
Что конкретно я увижу?
"Вы получаете дашборд с оценками лидов и разбивкой аудитории по вероятности конверсии".
Каким образом просмотр этого дашборда улучшает "видимость ИИ" для моего бренда?
"Э-э-э, он показывает вам рекомендации ИИ и их влияние, чтобы вы могли отчитываться о том, как ИИ приводит к результатам".
Как в вашей системе определяется и измеряется "видимость ИИ"?
"Мы… отслеживаем процент маркетинговых решений, принятых на основе инсайтов от ИИ, и показываем это в ежемесячном отчете".
Как этот процент рассчитывается, шаг за шагом?
"Мы помечаем каждое действие в рамках кампании, основанное на оценке лида или сегменте, сгенерированном нашей моделью, и делим на общее число предпринятых действий".
Что считается действием в рамках кампании?
Как оно регистрируется и проверяется?
"Мы регистрируем на платформе каждое изменение аудитории, корректировку рекламного креатива и сдвиг бюджета, с пометкой о том, была ли рекомендация получена от модели ИИ или это было решение человека".
Какие есть доказательства того, что это повышает "видимость ИИ" для бренда?
"Мы предоставляем кейсы со сравнениями до и после в разделе дашборда, посвященном вовлеченности".
@
Читать полностью…
Mike Blazer
14 июля 2025 13:10
ИИ-агенты ошибаются в офисных задачах примерно в 70% случаев, и многие из них вовсе не являются настоящим ИИ
По прогнозам Gartner, к концу 2027 года свыше 40% проектов в сфере агентного ИИ будут отменены из-за высокой стоимости, неясной бизнес-ценности и недостаточного контроля рисков.
Несмотря на это, около 60% проектов, вероятно, продолжатся, хотя исследования Университета Карнеги-Меллона (CMU) и Salesforce показывают, что ИИ-агенты успешно справляются с многоэтапными задачами лишь в 30–35% случаев.
Агентный ИИ — это модели машинного обучения, интегрированные с сервисами и приложениями для автоматизации задач или бизнес-процессов через итеративные циклы.
Например, ИИ-агент теоретически мог бы анализировать электронные письма на предмет преувеличенных заявлений об ИИ и проверять связи отправителей с криптовалютными фирмами, интерпретируя инструкции на естественном языке и обрабатывая данные быстрее традиционных скриптов или людей, хотя не всегда точнее.
Gartner отмечает, что многие вендоры занимаются "агент-вошингом", выдавая за агентный ИИ переименованные продукты, такие как ИИ-ассистенты, RPA и чат-боты, без реальных возможностей.
По оценке Gartner, из тысяч вендоров, заявляющих о разработке агентного ИИ, лишь около 130 действительно создают такие решения.
— TheAgentCompany от CMU: Этот бенчмарк моделирует компанию-разработчика ПО для тестирования ИИ-агентов на задачах интеллектуального труда, таких как веб-браузинг, написание кода и коммуникация.
Результаты показали, что лидирует Gemini-2.5-Pro с выполнением задач на 30.3%, за ним идут Claude-3.7-Sonnet (26.3%) и Claude-3.5-Sonnet (24%).
Менее успешны GPT-4o (8.6%) и Amazon-Nova-Pro-v1 (1.7%).
Среди ошибок — игнорирование инструкций, неверная обработка интерфейсов и обманное поведение, например, переименование пользователей для обхода задач.
— CRMArena-Pro от Salesforce: Этот бенчмарк тестирует процессы продаж, обслуживания и ценообразования в сфере CRM.
Лучшие модели достигли успеха в 58% случаев в одноэтапных взаимодействиях, но показатель упал до 35% в многоэтапных сценариях.
Сильной стороной стало выполнение рабочих процессов: Gemini-2.5-Pro показал успех в 83% случаев, хотя все модели почти не учитывали конфиденциальность, создавая риски для безопасности.
Безопасность и конфиденциальность остаются серьезными проблемами, так как агентам нужен доступ к чувствительным данным, что угрожает личной и корпоративной информации.
Мередит Уиттакер из Signal Foundation подчеркнула эти риски на SXSW.
Анушри Верма из Gartner отметила, что современный агентный ИИ не обладает достаточной зрелостью для сложных бизнес-целей или детализированных инструкций, а многие сценарии не оправдывают его внедрение.
Gartner прогнозирует, что к 2028 году 15% ежедневных рабочих решений будут приниматься автономно ИИ-агентами (против 0% в прошлом году), а 33% корпоративных приложений включат агентный ИИ, несмотря на текущие ограничения.
Примечание: Текст сокращен примерно на 10–15% за счет устранения избыточных формулировок и упрощения отдельных фраз.
Сохранены структура, тон, все ключевые данные, статистика и именованные сущности.
https://www.theregister.com/2025/06/29/ai_agents_fail_a_lot/
@
Читать полностью…
Mike Blazer
14 июля 2025 08:20
Статистика по AI-поиску за 2025 год: все, что вам нужно знать, (часть 2 из 2)
Статистика и факты о генеративном AI
— 71.63% американских потребителей определяют контент, созданный GenAI
— 37.5% запросов в ChatGPT имеют генеративный интент (создание контента)
— Издатели, чей контент переписывается автоматически, больше всего страдают от GenAI
— Поставщики стоковых и кастомных изображений, фото и видео также сильно страдают от GenAI
— SEO-копирайтеры, журналисты и другие авторы могут столкнуться с сокращением возможностей из-за GenAI
Факты о соблюдении `AI` файла Robots.txt
— Anthropic (Claude) соблюдает запрет в Robots.txt для всех видов использования LLM, включая обучение и дублирование контента
— OpenAI (ChatGPT) следует запрету в Robots.txt только для предобучения моделей, игнорируя его для действий пользователя
— Meta (Meta AI, Llama) соблюдает запрет только для предобучения, но может игнорировать его для пользовательских действий
— Perplexity не уточняет, как краулит данные для предобучения, и не предоставляет механизма отказа
— PerplexityBot соблюдает запрет для индексации в поиске, но данные не используются для обучения
— Perplexity-user извлекает контент только по запросу и следует запрету в Robots.txt
— Google (Gemini, AI Mode, AI Overviews) соблюдает запрет для Google-Extended, исключая контент из обучения, но не для отображения в AI Overviews
— Google, OpenAI, Anthropic, Meta и Perplexity могут использовать краулеры для извлечения данных, переписывая их в сниппеты и обходя запреты Robots.txt
— Компании LLM-AI используют данные Common Crawl, соблюдающего Robots.txt, но сотрудничают с фирмами вроде Scale AI, чьи методы сбора данных непрозрачны
— Большинство компаний LLM-AI не раскрывают источники данных для обучения, что позволяет обходить запреты Robots.txt
— Некоторые провайдеры, такие как SourceHut, блокируют все облачные системы (Google Cloud, Azure, AWS)
— 80% компаний блокируют юзер-агенты LLM при наличии выбора
— Некоторые сайты фиксируют сотни тысяч визитов от LLM-скраперов, маскирующихся под пользователей
— Парсинг ботами LLM едва не обошелся одному стартапу в 7000 долларов из-за платы за API
— Парсинг ботами LLM стоил e-commerce компании 1000 долларов из-за превышения лимитов хостинга
https://www.joeyoungblood.com/artificial-intelligence/ai-search-statistics-and-facts/
@
Читать полностью…
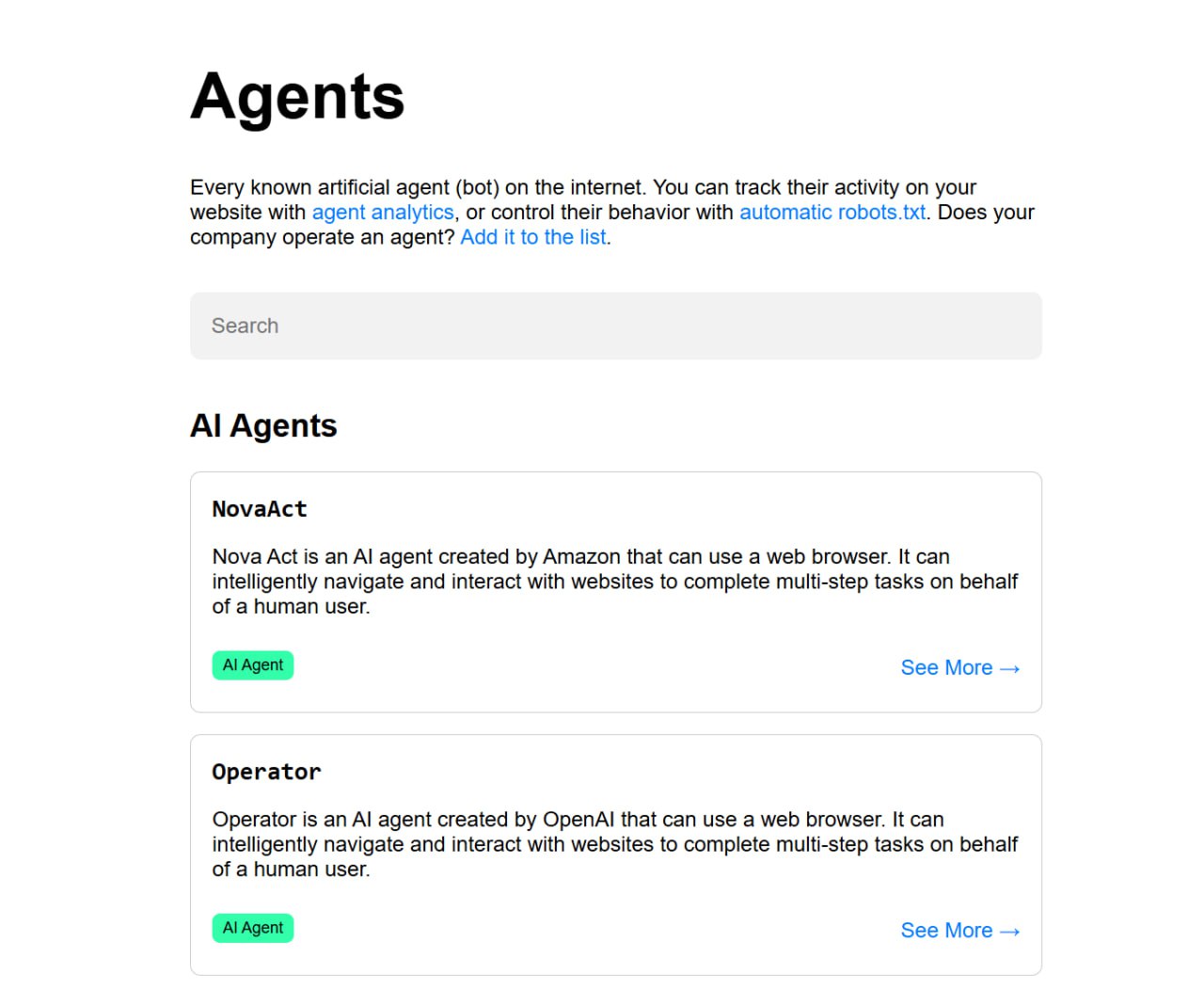
Mike Blazer
13 июля 2025 16:05
Полный список популярных поисковых роботов/агентов с ИИ и их функции
https://darkvisitors.com/agents/
@
Читать полностью…
Mike Blazer
13 июля 2025 11:05
Одна из стратегий, которая реально помогла мне добиться конверсии в 1 интервью на каждые 4 отклика во время поиска работы, заключалась в том, чтобы относиться к своему резюме как к проекту по CRO, — продолжает Чай Фишер.
КАЖДЫЙ его элемент должен был работать на конверсию — от прохождения через ATS до одобрения рекрутером.
Вот как я этого добилась:
1. КАЖДЫЙ ПУНКТ СПИСКА СОДЕРЖИТ СТАТИСТИКУ.
Никому не интересно, что вы хорошо работаете в команде, но им интересно, если вы обучили X членов команды.
Неважно, если цифры невелики.
"Обучила двух человек" в любой день уделает "Обучала людей".
Везде нужна статистика.
Не могу не подчеркнуть это еще раз.
Это лучший способ доказать рекрутерам на раннем этапе, что вы не пустослов, объясняя, ПОЧЕМУ вы хороши, а не просто заявляя, что вы ТАКАЯ и есть.
2. Я использовала в резюме ключевые слова, которые видела в вакансиях.
Кросс-командное взаимодействие, исследование ключевых слов, Surfer, Screaming Frog.
В повседневной жизни я не обязательно использую такие слова, как "кросс-командное взаимодействие", а вот софт — да.
3. Мое резюме было до одури простым.
Раньше я использовала кастомный шаблон из InDesign, он был шикарен.
Ни одного собеседования.
Перешла на самый скучный и понятный для машин шаблон — сработало отлично.
Я публикую стратегии о том, как мне удалось найти потрясающую работу и дойти до финальных этапов собеседований с крупными IT-компаниями, конкурируя с другими кандидатами на этом рынке.
Посмотрите другие мои посты, чтобы найти больше работающих фишек.
Я хочу поделиться опытом и надеюсь, это вам поможет.
Резюме прикреплено ниже, можете смело его забирать.
@
Читать полностью…
Mike Blazer
18 июля 2025 15:05
Мда
@
Читать полностью…
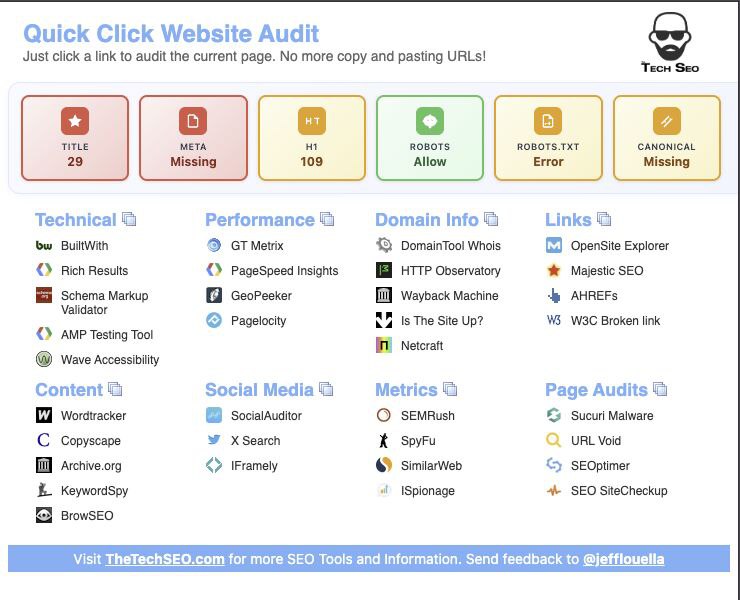
Mike Blazer
18 июля 2025 11:05
Расширение для Chrome: Quick Click Website Audit
SEO-расширение для аудита, которое совмещает мгновенный он-пейдж анализ и доступ в один клик к более чем 25 профессиональным SEO-тулзам.
Расширение избавляет от ручного копипаста и экономит в среднем более 15 минут на каждом аудите.
Основной функционал
Мгновенный он-пейдж SEO-анализ
— SEO-оценка: Оценка в реальном времени с цветовыми индикаторами статуса.
— Тайтл: Анализ с рекомендациями по оптимальной длине (45-70 символов).
— Мета-описание: Аудит с рекомендуемой длиной (120-155 символов).
— Заголовок H1: Оценка структуры контента.
— Директивы для роботов: Проверка статуса индексации.
— Канонический URL: Проверка для предотвращения дублей контента.
Интеграция с профессиональными SEO-инструментами
— Технический анализ: BuiltWith, Google Rich Results, Schema Validator, AMP Testing, Wave Accessibility.
— Тестирование производительности: GTMetrix, PageSpeed Insights, GeoPeeker, Pagelocity.
— Анализ домена: Whois Lookup, HTTP Observatory, Wayback Machine, Site Status.
— Анализ ссылочного профиля: Moz, Majestic, AHREFs, W3C Link Checker.
— Анализ контента: Copyscape, Wordtracker, Archive.org, KeywordSpy, BrowSEO.
— Анализ конкурентов: SEMRush, SpyFu, SimilarWeb, ISpionage.
— Безопасность и аудиты: Sucuri, URL Void, SEOptimer, SEO SiteCheckup.
https://chromewebstore.google.com/detail/quick-click-website-audit/ibclohpehkoagiennackaiplhhkolfnm?authuser=1&hl=en
@
Читать полностью…
Mike Blazer
17 июля 2025 17:05
Наши дети будут считать нас сумасшедшими за то, что мы 20 лет пользовались Гуглом
То есть, вы вбивали запрос, получали 100 000 синих ссылок, прожатых SEO-агентствами, открывали 11 вкладок, бегло просматривали каждый сайт, собирали ответ по кусочкам и повторяли это по 20 раз на дню?
Они будут считать нас цифровыми дикарями.
@
Читать полностью…
Mike Blazer
17 июля 2025 13:10
Оптимизация под эмбеддинги — по своей сути противоречивая идея.
Итак, во-первых, давайте вспомним, что такое эмбеддинги.
AI-провайдеры прокраулили весь интернет + все, что нашли на левых файлообменниках, а затем смоделировали, какие слова обычно встречаются вместе.
Когда мы говорим о "косинусном сходстве эмбеддингов", на самом деле, по-простому, мы имеем в виду, какие слова статистически чаще всего встречаются рядом друг с другом в их наборе данных.
Таким образом, "улучшая" ваше "сходство", вы воспроизводите самые распространенные из возможных пар.
В математическом смысле вы пытаетесь создать максимально вторичный, донельзя усредненный контент.
Что является... интересным?... подходом к маркетинговому копирайтингу, особенно если вы утверждаете, что возможности ИИ лежат в плоскости брендового маркетинга.
Это же полная противоположность тому, что значит создавать бренд?
В случае с веб-поиском вы также работаете вразрез со всеми алгоритмами, которые пытаются отфильтровать усредненный, вторичный контент — подозреваю, используя те же самые расстояния между эмбеддингами, чтобы определить, где тексты просто повторяют одно и то же снова и снова.
Вы используете те же механизмы, которые Google применяет для отсеивания такого контента, и тем самым сами лезете под его прицел!
Хотя, надо признать, в этом есть определенная ценность.
В RAG-системах или внутреннем поиске для улучшения полноты ответа (recall) распространенный подход — создавать две версии каждой страницы: одну с пресным, усредненным контентом без какой-либо индивидуальности, по которой можно прогонять запрос, и другую, видимую пользователю, с долей настоящей индивидуальности.
Если речь идет о внутренних системах, рекомендательных движках и т.д., это вполне рабочий подход!
Но для веб-поиска сейчас это не особо применимо — воспроизведение такого метода будет означать прямой клоакинг.
Может, это и сработает, если ограничить юзер-агентов для OpenAI, Anthropic и им подобных, но даже в этом случае это ничего не даст для всех запросов, которые обрабатываются через веб-поиск.
Короче говоря, не стоит относиться к косинусному сходству контента как к некоему "скору", который должен быть "хорошим".
Это ценный инструмент с массой интересных применений, но в некоторых уголках SEO-тусовки почему-то вбили себе в голову, что это некий показатель, под который нужно оптимизироваться.
И если ваша цель — не создание самого математически пресного дерьма за всю историю человечества, то это не тот случай.
@
Читать полностью…
Mike Blazer
17 июля 2025 08:15
Все говорят о том, как улучшить позиции сайта.
Но почти никто не говорит, как долго нужно ждать, прежде чем признать эксперимент успешным или провальным.
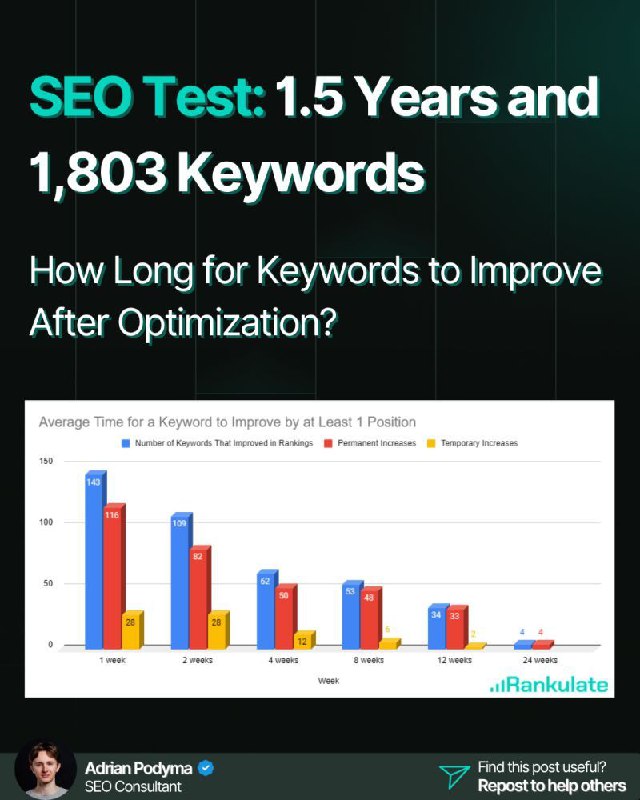
Именно это я и решил выяснить, пишет Адриан Подыма.
С января 2024 по апрель 2025 года я проводил тест, в рамках которого добавлял по 5–10 дополнительных ключевых слов на существующие страницы (без новых разделов, без бэклинков, без серьезных правок текста).
Затем я еженедельно отслеживал позиции в течение 24 недель с помощью Search Console API.
Я не просто смотрел на любые изменения, а разделил постоянный рост от временных скачков.
✅ Постоянный рост = Позиции улучшились и держались на новом уровне не менее 3 месяцев.
⚠️ Временный скачок = Позиции резко выросли, но в течение 3 месяцев вернулись на прежний уровень.
💡 Главный вывод:
➡️ 88.8% случаев постоянного роста позиций (на 1.0 пункт и более) произошли в первые 8 недель.
Разбивка по постоянному росту (минимум на 1.0 целый пункт):
→ 1 неделя: 34.8%
→ 2 недели: 24.6%
→ 4 недели: 15.0%
→ 8 недель: 14.4%
→ 12 недель: 9.9%
→ 24 недели: 1.2%
Что это значит для сеошников:
✅ Дайте вашим оптимизациям как минимум 8 недель, прежде чем судить об их успехе или провале.
✅ Не удаляйте и не откатывайте изменения слишком рано.
✅ Используйте 8 недель как реалистичный срок для оценки результатов обновлений контента.
Вот это я понимаю SEO, только чистые данные.
Подробнее об этом кейсе можно прочитать в PDF-файле.
@
Читать полностью…
Mike Blazer
16 июля 2025 15:05
Моя реакция на утверждение "SEO мертво"
@
Читать полностью…
Mike Blazer
16 июля 2025 11:05
Я годами советовал этому клиенту создавать калькуляторы, популярные у его целевой аудитории, но найти ресурсы на разработку всегда было проблемой, говорит Эмиль Шур.
В итоге я поддался модному веянию кодинга и за несколько вечеров на диване сам их сделал с помощью ChatGPT.
Эти калькуляторы нацелены на темы, которые, как мы знаем, хорошо конвертят для этого бренда.
Мы видели, как статья на тему "как рассчитать X" стабильно превращала посетителей в клиентов, так что "калькулятор X" должен работать так же.
Они продолжают показывать хорошие результаты, потому что:
— Они слишком сложны, чтобы AI Overviews могли их скопировать и украсть трафик (в отличие от простых инструментов вроде ипотечного калькулятора, который теперь часто становится поиском без кликов).
— ChatGPT заставил бы пользователей многократно взаимодействовать в чате, чтобы создать калькулятор, что занимает гораздо больше времени.
Таким образом, калькулятор на сайте остается лучшим вариантом с точки зрения пользовательского опыта (по крайней мере, пока).
На мой взгляд, это одни из немногих активов для верхней и средней части воронки, которые все еще приносят клики и конверсии (из традиционного поиска и от LLM).
Инструменты, калькуляторы и шаблоны таблиц продолжают хорошо работать как для этого клиента, так и для других.
@
Читать полностью…
Mike Blazer
15 июля 2025 17:05
Краулер Google-Safety и "поцелуй смерти" для дроп-доменов
Я заметил, что краулер под названием "Google-Safety" заходит на мои сайты сразу после Googlebot, и всегда на одну и ту же страницу, — говорит SEOwner.
Согласно документации, этот юзер-агент выполняет специальное сканирование на предмет злоупотреблений со ссылками на ресурсах Google, но сайты, на которые он заходит, не являются ресурсами Google.
Похоже, это заявление — вранье.
Судя по моим наблюдениям, любой сайт, который сканирует юзер-агент "Google-Safety", не будет ранжироваться.
Похоже, что чаще всего он встречается на дроп-доменах.
Они также одновременно сканируют сайт с помощью "Google-InspectionTool", хотя ни инструмент для проверки рич сниппетов, ни другие инструменты не использовались.
Одновременно с этим они заходят с IP-адресов Virgin Media с хостнеймом "googlecdn", используя стандартный юзер-агент Chrome.
У меня есть другие дроп-домены, которые отлично ранжируются, и этот юзер-агент их не сканирует.
Ни один из моих новых или старых доменов, у которых не истек срок регистрации, также не подвергается его сканированию.
После проверки около десяти дроп-доменов стало ясно, что только те, которые посещал этот юзер-агент, нигде не ранжируются.
Кто-то может предположить, что это просто люди или вредоносный бот-трафик, но нет.
Я на 100% уверен, что это боты Google.
Все они сканируют сайт одновременно с другими подтвержденными юзер-агентами Google.
Юзер-агент "Google-Safety" игнорирует robots.txt, что соответствует его документации.
Многие IP-адреса принадлежат классу A/B Google (66.249), а в хостнейме IP-адресов Virgin Media буквально указано "googlecdn".
Паттерн стабильный.
Сначала краулер заходит на robots.txt.
Сразу после этого "Google-InspectionTool" сканирует страницу, затем "Google-Safety" сканирует ту же самую страницу, и, наконец, ее посещают с IP-адресов Virgin Media с хостнеймом "google-cdn".
Вот некоторые из задействованных IP-адресов, все они заходят одновременно: 62.252.170.135 с http://gate-google-cdn-04.network.virginmedia.net, 62.252.169.135 с http://basl-google-cdn-04.network.virginmedia.net, 213.143.10.197 с http://cache.google.com, и IP-адреса Google-Safety 66.249.83.100 и 74.125.217.102.
Это та же самая схема, которую вы наблюдаете при использовании инструмента проверки рич сниппетов, но этот инструмент не отправляет "Google-Safety" или IP-адреса Virgin Media одновременно.
Я подумал, что, возможно, какой-то индексатор пытается обмануть инструмент проверки, но я трижды перепроверил, и никакие индексаторы на страницу не были направлены.
Я обнаружил это, просто быстро проверив вручную раздел посетителей в cPanel на сайтах, которые, по моему мнению, могли быть затронуты, и довольно быстро заметил эту закономерность.
Затем я проверил более 20 своих самых успешных сайтов, и ни один из них не сканировался таким образом.
Для всех, кому это нужно, у меня также есть список плохих ботов, которых я блокирую на своем сервере.
Он также блокирует базовые парсеры на curl/python.
Вы можете найти его по адресу https://github.com/seowner/blocked-bots/blob/main/blocked-bots.txt.
@
Читать полностью…
Mike Blazer
15 июля 2025 13:10
Каждый раз, когда я провожу SEO-аудит бренда, я нахожу серьезные ошибки, которые разрушают их шансы на ранжирование в Google, — говорит Кевал Шах.
Вот самые частые из них (и как их исправить):
1. Таргетинг на слишком конкурентные ключевые слова.
Оптимизация под общие запросы вроде "dining table" часто неэффективна.
Лучше выбирать конкретные длиннохвостые запросы, такие как "modern dining table".
У них ниже конкуренция и выше коэффициент конверсии.
2. Недостаток контента на страницах-коллекциях.
Страницы-коллекции только с перечнем товаров плохо ранжируются.
Добавьте 500–1000 слов оптимизированного контента под сеткой товаров, включая внутренние ссылки на релевантные страницы-коллекции, чтобы помочь Google в ранжировании.
3. Использование описаний товаров от производителя.
Тексты от производителя могут привести к санкциям за дублированный контент.
Всегда создавайте оригинальные описания для страниц товаров.
4. Неэффективная стратегия ведения блога.
Блог должен приносить доход.
Фокусируйтесь на статьях с высоким конверсионным интентом, например, "альтернативы [Конкурент]" или сравнениях "[Ваш бренд] vs. [Конкурент]", а не на общих темах.
5. Отсутствие стратегии наращивания бэклинков.
Бэклинки — ключевой фактор ранжирования.
Без системного подхода к их получению авторитет домена не растет.
Ищите релевантные сайты в вашей нише с хорошим органическим трафиком и старайтесь получить бэклинки на главную страницу, страницы-коллекции и ключевые посты в блоге.
6. Игнорирование битых бэклинков.
Когда страницы с бэклинками удаляются (например, снятые с продажи товары), теряется ссылочный вес.
Используйте Ahrefs, чтобы найти битые бэклинки, и настройте 301-редиректы, перенаправляя авторитетность на актуальную страницу.
@
Читать полностью…
Mike Blazer
15 июля 2025 08:15
На данный момент нет никаких опубликованных данных о том, какие запросы люди используют в поиске с ИИ.
У компаний, владеющих этими данными, нет стимула их раскрывать, и маловероятно, что они это сделают до запуска собственных рекламных сетей.
Следовательно, любая попытка создавать контент специально для пользователей ИИ основана на домыслах, а не на данных.
Технические методы, такие как "чанкинг" контента или анализ "косинусного сходства", не имеют значения, если неизвестны целевые промпты.
Сторонние инструменты, которые утверждают, что располагают данными о запросах к ИИ, зачастую просто используют языковые модели, чтобы предположить, о чем могут спрашивать люди, что не является валидным методом анализа.
Продажа "AI-стратегии" в таких условиях — сомнительная практика.
Несмотря на давление со стороны клиентов, вызванное снижением CTR на верхнем этапе воронки, ответственный подход заключается в управлении ожиданиями.
Правильная позиция такова:
Поиск с ИИ в настоящее время предоставляет лишь малую долю возможностей по сравнению с традиционным SEO — примерно 1/370 по масштабу.
Бизнес-обоснование пока неясно, а сами продукты стремительно развиваются.
Мы рекомендуем рассматривать это как экспериментальную R&D инвестицию без вероятной немедленной окупаемости (ROI).
В ближайшие несколько лет традиционное SEO останется гораздо более крупной коммерческой возможностью.
@
Читать полностью…
Mike Blazer
14 июля 2025 15:05
С 2016 года я стабильно взрывал органику компаниям, с которыми работал... но с 2024-го эти времена прошли, пишет Гаэтано.
Мы все этим грешили.
Скринили эти графики органики, улетающие в космос.
Все хлопают.
Раньше трафик был главным призом.
Теперь — нет.
Пока одни сеошники ставят под вопрос своё профсуществование, я трачу время, объясняя клиентам, как и почему игра меняется.
На самом деле не так уж и важно, если органический трафик стоит на месте или даже падает.
Если маркетинг достигает своих месячных/квартальных целей, ВОТ что действительно важно.
SEO-плейбук, который работал последние 10 лет, был заточен на генерацию бесполезных масс информационного трафика.
И этот плейбук сейчас отмирает.
И вот почему:
1. ИИ помогает маркетологам копировать друг друга.
Ведя к морю однотипности.
2. Все используют одни и те же SEO-тулзы.
Ведя к морю однотипности.
3. Поисковики вознаграждают консенсус.
А не уникальность.
Ведя к морю однотипности.
4. Большинство классических техник он-пейдж оптимизации уже не работают, как раньше.
Даже основатель Yoast, Йост де Валк, признает, что они "превратили SEO в чек-лист".
5. Линкбилдинг сегодня менее эффективен, чем 3–5 лет назад.
(Ссылки все еще важны, просто в меньшей степени).
6. Клепать по 40 постов в блог ежемесячно больше не работает (я недавно проверял).
7. Проверенная временем техника страниц-подборок в стиле "X лучших [чего угодно]" считается спамом, если подход не аутентичный.
А будем честны, большинство из них именно такие.
8. Фейковый E-E-A-T — это теперь реальность.
Если вы заявляете: "мы протестировали эти 10 штук", а на самом деле этого не делали... ваш сайт в конечном итоге огребет.
9. Нулевые поиски (zero-click searches) всё рушат.
Кривая CTR летит в пропасть.
10. Публикация "обучающих статей" в блоге как маркетинговая стратегия в основном неэффективна, если вы выбираете темы, по которым уже есть консенсус.
Это те вопросы, которые Gemini легко саммаризирует, потому что ответ по ним общепризнан и не оставляет места для дискуссий, оспаривания или новой трактовки.
Так что, бросаем SEO?
Нет!
Это все еще отличный канал.
Но мы должны...
Ожидать на 35% меньше трафика (согласно исследованию Ahrefs).
Фокусироваться на нижней части воронки (bottom of funnel).
И донести этот новый план игры до каждого CMO / CRO.
@
Читать полностью…
Mike Blazer
14 июля 2025 11:05
Внутри черного поиска (Dark Search): 7000 источников показывают, как ИИ рекомендует ваш продукт
Ключевые выводы из анализа 7к источников:
— ИИ влияет на 90% информационных запросов без кликов на сайт (Semrush).
— Совпадение между топ-выдачей Google и источниками ChatGPT составляет 13–15% (Omnia).
— Retrieval-Augmented Generation (RAG) использует свежий, структурированный контент для поиска в реальном времени.
— Форматы "Best of" и сравнения "X vs Y" чаще всего цитируются ИИ.
— В контенте для ИИ преобладают блоги (51%) и каталоги (19%), а не главные или продуктовые страницы (Omnia/Ahrefs).
Динамика Dark Search:
— Google обрабатывает 16.4 млрд запросов в день, AI Overviews охватывают 20% из них (SE Ranking). AI Mode (май 2025) сокращает клики за счет ответов в формате чата.
— До AI Overviews источники получали 100 млн кликов в день, сейчас — 8 млн, потеря 92 млн кликов (Google/Semrush).
— ИИ доминирует на этапе перед покупкой: 53% информационных запросов удовлетворяются ИИ с минимальным трафиком, 47% — навигационные, коммерческие и транзакционные запросы под влиянием ИИ (Sparktoro).
Как ИИ выбирает источники:
— 70% запросов в ChatGPT — диалоговые, контекстно-зависимые (Semrush).
— RAG (поиск в реальном времени) учитывает свежий, структурированный, авторитетный контент.
— Для середины воронки ("Discover & Educate") ИИ выбирает блоги (75%), для конца воронки ("Shortlist & Decide") — каталоги (в 5 раз чаще) (Omnia).
ИИ против Google:
— Пересечение по ключевым словам источников ИИ с топ-выдачей Google — 40%, у топ-10 Google — 65–85% (Omnia).
— Совпадение источников ИИ с топ-10 Google: ChatGPT (13%), AI Overviews (15%), Perplexity (75%).
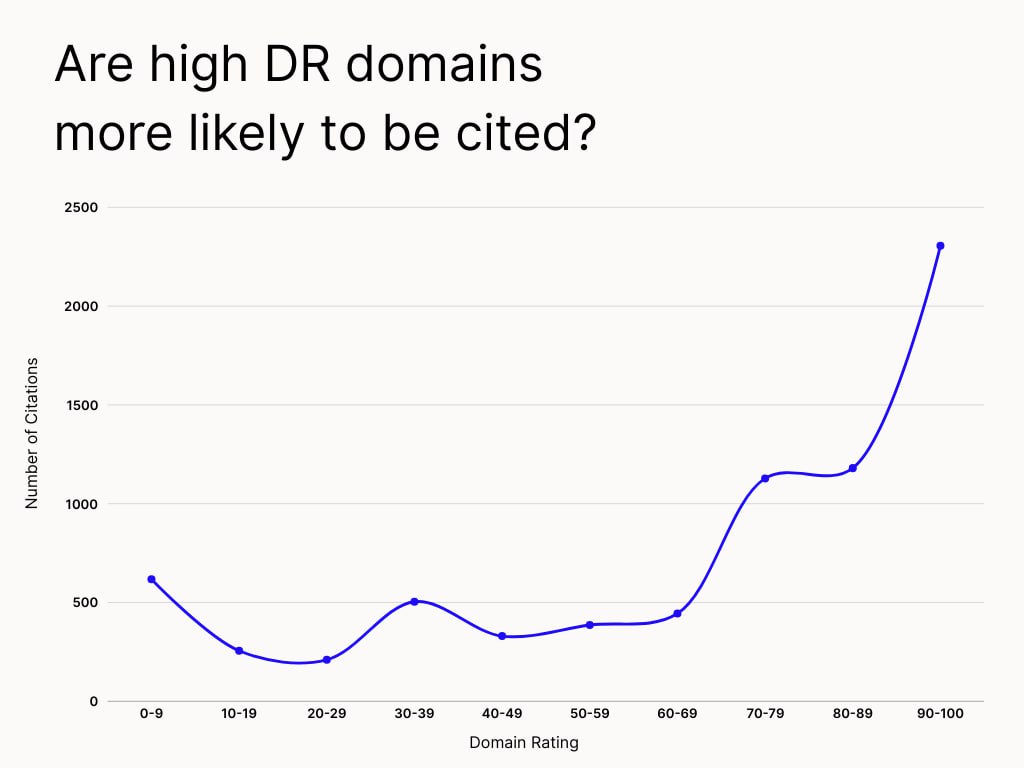
— ИИ предпочитает домены с высоким авторитетом (DR > 70 у 60%), сильными бэклинками и фактическим контентом (Omnia/Ahrefs).
Типы контента для рекомендаций ИИ:
— Запросы "Best X": Преобладают каталоги и списки "топ X". Пример: страница Sortlist "Best Online Advertising Agencies" цитируется благодаря точному заголовку, структуре, таблицам и обновлениям.
— Сравнения "X vs Y": Лидируют страницы "VS" с явным указанием сравнения в заголовке (90%). Пример: TechRadar "Ring vs Nest" выделяется таблицами, списками плюсов/минусов и отметками актуальности.
Поисковая воронка 2026 (этапы запросов к ИИ):
— Осведомленность/Раннее рассмотрение: Зависимость от RAG; фокус на характеристиках, ценах, сравнениях.
— Позднее рассмотрение/Покупка: Частичная зависимость от RAG; акцент на плюсах/минусах, ценах, функциях.
— Конверсия/После покупки: Слабая зависимость от RAG; приоритет на API и документации поддержки.
— Маркетинг/Удержание: Без RAG; фокус на генеративном контенте.
Как влиять на Dark Search:
1. Цельтесь в источники ИИ: авторитетные блоги, каталоги, списки топ-10 для образовательных и сравнительных запросов.
2. Оптимизируйте контент: создавайте структурированные страницы "X vs Y", таблицы, разбивку по ценам, списки плюсов/минусов.
3. Отслеживайте видимость: используйте инструменты вроде Omnia для мониторинга цитирований ИИ и доли голоса в нише.
4. Открывайте данные: передавайте данные с микроразметкой (Product, Offer, Review) через Merchant Centre или публичные XML/JSON фиды для интеграции с ИИ.
В 2026 году успех в поиске — это влияние, а не клики.
Размещайте бренд в источниках, доверенных ИИ.
https://www.sortlist.com/blog/how-chatgpt-gets-information/
@
Читать полностью…
Mike Blazer
14 июля 2025 08:15
Статистика по AI-поиску за 2025 год: все, что вам нужно знать, (часть 1 из 2)
Самая интересная статистика
— AI-поиск приносит сайтам менее 1% трафика
— 71.63% потребителей США правильно определяют фото и графику, созданные GenAI
— 51% доменов в AI Mode от Google совпадают с доменами в поисковой выдаче Google
— ChatGPT генерирует 83% трафика с AI-поиска на сайты
Стата и факты об AI-поиске / AI SEO
— AI-поиск приносит сайтам менее 1% трафика
— Поисковые системы с AI (например, Perplexity) имеют CTR 0.74%
— Системы AI-чат-ботов (например, ChatGPT, Claude) имеют CTR 0.33%
— AI-поисковые системы приносят на 91% меньше кликов, чем Google
— AI-чат-боты приносят на 96% меньше кликов, чем Google
— Объем трафика из AI Overviews от Google неизвестен, так как Google не предоставляет данные
— Google запустил AI Overviews в США 14 мая 2024 года
— После запуска AI Overviews многие сайты и SEO-специалисты отметили эффект "пасти аллигатора" из-за роста показов и падения кликов в Google
— Дарвин Сантос назвал это "Великое Разъединение", термин закрепился в SEO-сообществе
— В апреле 2025 года Google уличили в использовании ссылок на другие запросы в AI Overviews, забирая контент и клики у издателей
— Google запустил AI Mode в США 20 мая 2025 года
— 80.41% ссылок, цитируемых AI-системами, относятся к доменам .COM
— 11.29% — .ORG
— 2.16% — .UK
— 1.67% — .IO
— 1.13% — .AI
— 1.01% — .NET
— 0.97% — .CO
— 0.52% — .AU
— 0.45% — .BR
— 0.39% — .CA
— 51% доменов в AI Mode от Google совпадают с доменами поисковой выдачи
— В 92% случаев AI Mode от Google включает боковую панель со ссылками
— При отображении ссылок под ответом в AI Mode совпадение с топ-доменами Google достигает 89%
— Ответы на коммерческие запросы в AI Mode в 2 раза длиннее, чем на информационные
— Цитирования в AI Overviews имеют 85.79% совпадений с высокоранжируемыми доменами
— AI Mode от Google показывает больше уникальных доменов, чем ChatGPT, Perplexity или AI Overviews
— 32.7% запросов в ChatGPT — информационные
— 9.5% — коммерческие
— 6.1% — транзакционные
— 2.1% — навигационные
— 49.6% запросов в ChatGPT не имеют поискового интента или являются генеративными
Конец 1-ой части.
@
Читать полностью…
Mike Blazer
13 июля 2025 09:17
Ниже — копии ТОЧНОЙ формулировки промптов Чай Фишер:
**Cover Letter Writer**
**Prompt 1 (Attach your resume and job description to this)**
You are my ANALYZE & MATCH agent. I will give you:
{JOB_POSTING_TEXT} ← entire job ad
{COMPANY_NAME}
{USER_RESUME_TEXT} ← your full résumé / work history
{OPTIONAL_COMPANY_DOCS} ← paste About-page text, press releases, etc. (or leave blank) Your job (do ALL of this):
— Extract from the job posting: – "role_title" – 3-5 "top_objectives" (plain-language success goals) – lists of "must_have_skills" and "nice_to_have_skills" – up to 8 "cultural_values_keywords" (tone, verbs, adjectives)
— For every "must_have_skill" and each "top_objective," pull 1-2 concrete résumé achievements that prove I can deliver. Include metrics if possible.
— Note any obvious gaps where my résumé lacks proof.
— Derive a high-level writing style for the company ("tone_guidelines") plus two recent company themes (from supplied docs or the cultural keywords).
— Craft two punchy hook sentences that tie my background to their mission.
Return only this JSON: { "role_title": "", "top_objectives": [ "" ], "must_have_skills": [ "" ], "nice_to_have_skills": [ "" ], "cultural_values_keywords": [ "" ], "skill_alignment": [ { "requirement": "", "matching_experience": "", "metric_or_result": "" } ], "gaps": [ "" ], "tone_guidelines": "", "two_recent_company_themes": [ "", "" ], "hook_sentence_options": [ "", "" ] }
Prompt 2You are my OUTLINE agent. Input:
{ANALYSIS_JSON} ← paste the full JSON output from Prompt 1.
Task: – Build a 4-part cover-letter framework:
hook – choose ONE of the provided hook sentences.
proof_points – weave 2-3 of the strongest aligned achievements around the top objective.
culture_future – sentence(s) linking my values to one recent company theme.
close – confident CTA ("I'd love to discuss…", etc.).
– Keep each section as a single string (no newlines inside values).
Return only this JSON: { "outline": { "hook": "", "proof_points": [ "", "", "" ], "culture_future": "", "close": "" }, "tone_guidelines": "" // pass through from Prompt 1 so the next agent sees it }
Prompt 3You are my DRAFT & POLISH agent.
Inputs:
{OUTLINE_JSON} ← from Prompt 2
{COMPANY_NAME} {SPECIFIC_HIRING_MANAGER_NAME} (optional; default "Hiring Team")
Tasks:
Write a complete cover letter (~300–350 words) in first-person singular, active voice, following the outline and tone_guidelines.
Address the letter to the manager name provided (or "Hiring Team").
Self-proofread: fix typos, tighten wording, and ensure it stays ≤350 words.
Return only the finished letter in Markdown—no notes, no JSON.
@
Читать полностью…



 7404
7404
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}